Lucene之MaxScorer算法简介
简介
名叫“Lucene之MaxScorer算法分析”其实并不准确,因为有Stefan提交的MaxScorer代码尚未提交到Lucene,至今还在讨论
中,具体见:https://issues.apache.org/jira/browse/LUCENE-4571,他索所要解决的问题就是Lucene在计算Top-k时效率慢的问题。
目前Lucene对于MaxScore的计算, AND计算比较快,这个就不用优化,主要是针对OR 查询,这时需要比对每个Scorer,计算其得
分这样就很耗时,导致性能很慢。其实可以预先就可以确定一些是不需要计算的,直接可以跳过,所以自1995年提出的MaxScore算
法就是为解决这个问题。Stefan根据几天涉及Maxscore优化的论文为Lucene贡献了MaxScorer代码(尚未通过审核提交到Lucene),
在此感谢Stefan的贡献。
MaxScorer思想
对于一个Boolean查询,每个Term查询出来对应一个Inverted List,每个list有可能很长有可能很短,每个list中的每个doc都包含了该term,
都有和当前term的一个相似性打分。那么对于每个List来说就存在一个对于当前Term的最大打分。称为该list的Upper Bound。
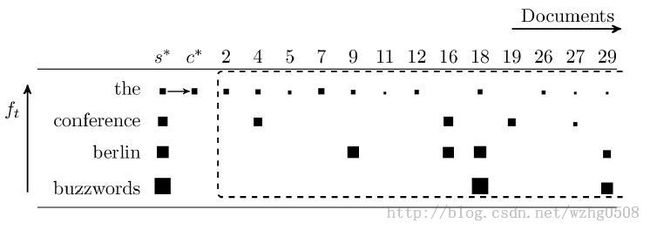
假设queryString=“The OR conference OR berlin OR buzzwords”,具体MaxScore算法如下:
按照term对应的dcoFreq(包含该Term的文档数)从大到小排序。上图中方块的大小代表该文档
和term的相似性打分的大小

在索引期间,计算词典中每个term和当前索引文档的相似性打分,那么在查询时就可以直接得到
每个term对应的每个doc的相似性打分,并且可以得到每个term对应的倒排列表中的最大打分值。
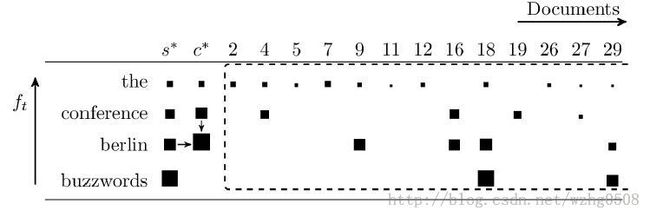
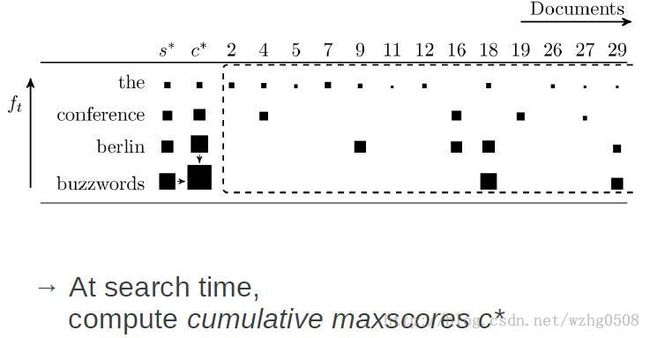
在搜索阶段,得到倒排列表之后,得到最大得分,然后最大得分累加起来。如上C*(the) = S*(the),
C*(conference)= S*(the) + S*(conference),C*(berlin)= S*(the) + S*(conference) + S*(berlin),
C*(buzzwords)= S*(the) + S*(conference) + S*(berlin)+ S*(buzzwords),为什么要这样呐
下面会解释。
下面开始计算 Top-2

开始时把当前相似性打分最小的最为threshold,这样为了确保凡是大于该域值的doc都能被当做
candidate来处理。把C*(the)作为threshold的最上限,此时threshold没有超过C*(the),一旦超出
就得调整C*的值。每次nextDoc(),调整Top-2 堆,去最小为Threshold,和当前的C*判断,是否
超过C*。
一旦threshold超过当前的C*,那么说明已有得分超过当前最大得分,那么把当前的2个doc送进
最小堆中。调整C*为下一个即C*(conference),那么这时跳跃表跳到docID=16处再开始比较。
为什么会跳到docID=16呐?
1、首先当前threshold已经大于Term(the)的最大值了,这时Term(the) 列表中以后的doc
就不需要再进行比较了。
2、从当前超出C*(the)的docID往后平移,遇到非Term(the)倒排表的第一个doc时停止,
然后开始比较
3、在开始比较之前,调整C*为C*(conference)
如下图:

平移完之后,开始只把第二个虚线框中的docID来进行比较
如下图,当再次超出C*(conference)时,需要再次进行调整,此时最小堆中的最小值已经超出
前面两个list的最大值的和了,所以Term(the)和Term(conference)的列表内容就不需要再纳入
Top-2的范畴了,直接平移跳过包含Term(the)和Term(conference)列表中的元素,直到遇到非
以上两个列表中的元素,然后调整C*为下一个C*(berlin),继续开始比较。
下面依次进行这样的过程直至遍历完所有的列表。如下图所示

这样的话,我们就能得到精确的Top-2的docID了。
在一开始的时候,按照docFreq排序之后,记住Maxscore最大的docID,一旦比较操作超过了这个docID时,以后的doc就不再
需要比较,就直接终止,就是所谓的Early Termination
参考文献
1、https://issues.apache.org/jira/browse/LUCENE-4571
2、H. Turtle, J. Flood. Query Evaluation: Strategies and Optimizations, IPM, 31(6), 1995.
3、A. Z. Broder, D. Carmel, M. Herscovici, A. Soffer, J. Y. Zien. Efficient Query Evaluation using a Two-Level Retrieval Process, in Proc. of CIKM, 2003.
4、 T. Strohman, H. Turtle, W. B. Croft. Optimization Strategies for Complex Queries, in Proc. of ACM SIGIR, 2005.
5、K. Chakrabarti, S. Chaudhuri, V. Ganti. Interval-Based Pruning for Top-k Processing over Compressed Lists, in Proc. of ICDE, 2011
6、S. Pohl, A. Moffat, J. Zobel. Efficient Extended Boolean Retrieval, IEEE TKDE, 24(6), 2012.