solr DocumentCache的问题
发现如果不使用Document Cache的时候,solr内部还是会调用两次
第一次,在QueryComponent里会有处理搜索,取得result,除了内部lucene id外,会调用doPrefetch方法,取出doc文档 放在DocumentCache缓存里,
便于下次使用,如果当前没有使用DocumentCache的话,发现还是会调用该方法去拿Document出来。。
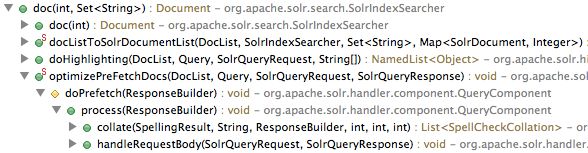

responseWriter的时候也会调用doc(int ,Set<String>)方法取Document,如果有使用document Cache的话,可以得到之前已缓存的数据,不用再去索引里取数据,但如果没有用cache的话,就会去查询。这样,会重复调用两次取document数据
先看正向取文档时的代码如下:
public Document doc(int i, Set<String> fields) throws IOException {
Document d;
if (documentCache != null) {
d = documentCache.get(i);
if (d!=null) return d;
}
if(!enableLazyFieldLoading || fields == null) {
d = getIndexReader().document(i);
} else {
d = getIndexReader().document(i,
new SetNonLazyFieldSelector(fields));
}
if (documentCache != null) {
documentCache.put(i, d);
}
return d;
}
或者应该修改的地方,应该在没有使用document cache的地方不调用该方法:
doPrefetch(rb);
应该修改判定条件
protected void doPrefetch(ResponseBuilder rb) throws IOException
{
SolrQueryRequest req = rb.req;
SolrQueryResponse rsp = rb.rsp;
//pre-fetch returned documents
if (!req.getParams().getBool(ShardParams.IS_SHARD,false) && rb.getResults().docList != null && rb.getResults().docList.size()<=50) {
// TODO: this may depend on the highlighter component (or other components?)
SolrPluginUtils.optimizePreFetchDocs(rb.getResults().docList, rb.getQuery(), req, rsp);
}
}
改为:
protected void doPrefetch(ResponseBuilder rb) throws IOException
{
SolrQueryRequest req = rb.req;
SolrQueryResponse rsp = rb.rsp;
//pre-fetch returned documents
if (documentCache != null&&
!req.getParams().getBool(ShardParams.IS_SHARD,false) && rb.getResults().docList != null && rb.getResults().docList.size()<=50) {
// TODO: this may depend on the highlighter component (or other components?)
SolrPluginUtils.optimizePreFetchDocs(rb.getResults().docList, rb.getQuery(), req, rsp);
}
}