火车头采集器
火车头采集器功能还是很强大的,不过如果涉及到采集数据导入自己数据库的话,可能自己写采集的导入更有效率点(不过要有点实力了)。介绍下火车头采集的一点点知识点:
1:采集的开始,就是新建任务(可以先建立分组,在组下建立任务)。
2:之后呢 ,就是建立规则了,分四步:
1):采集网址规则
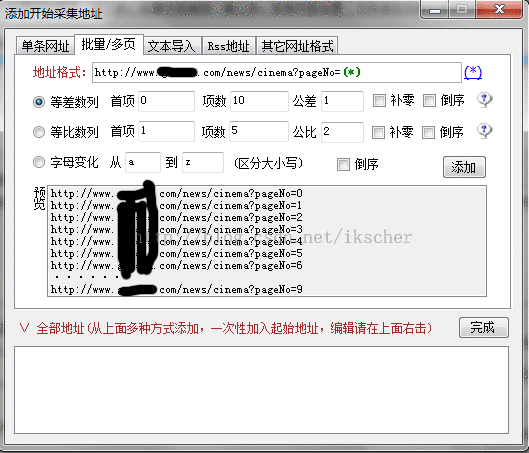
2):采集内容规则
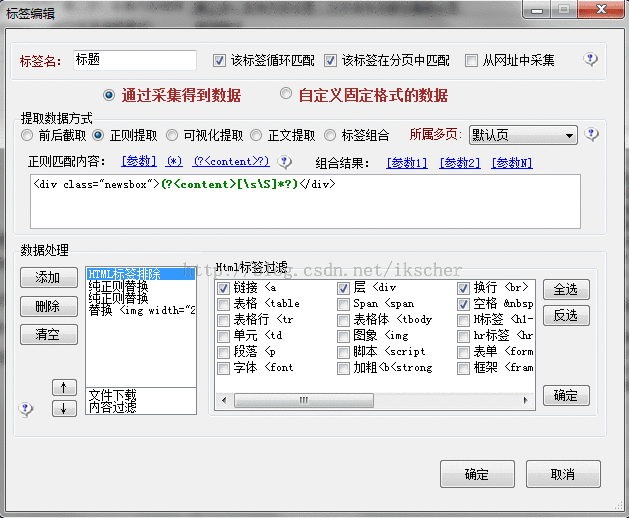
如果采集的结果含有参数1,参数2等的,那么应该是之前的设置采集规则没有删除组合结果的原因。
火车采集器里支持两种正则,一个纯正则,一个参数正则。
关于纯正则:
在标签中用正则表达式采内容的格式是这样:
开始代码(?<content>正则表达式)结束代码
其中在开始代码和结束代码中如有需要转义的字符就要用\转义。
比如这个:<div class="newsbox">(?<content>[\s\S]*?)</div> ,这里我们需要的是<div>标签里面的内容,所以可以这样写。其他的延伸点:
<div class="class_\d">(?<content>[\s\S]*?)</div>也是采集div标签里面的内容,
<a href="v_\d.html">(?<content>[\s\S]*?)</div></a> 采集a标签的内容。
关于参数正则:
这个不算是正则,可以对采到的内容进行组合。输入框两边都不得为空,后边的组合结果参数是按正则匹配内容的顺序来写的。
比如:
正则匹配内容:<a href="[参数]" alt="www" title="[参数]" ></a> ,组合结果里面,[参数1] 就是href对于的内容,[参数2]就是title对应的内容。
一般来说,如果页面有多个重复的标签div,想采集这个div标签里面里面里面的标签内容,那么最好从最外层这个重复的标签div开始,然后采用内容过滤的方法来采集到里面里面里面的标签内容。
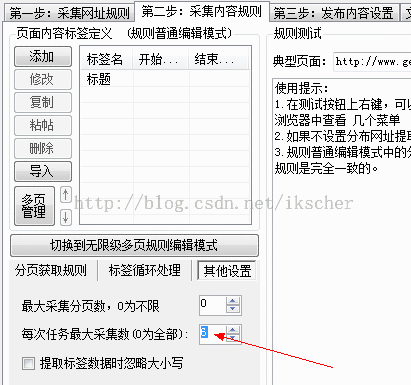
3):发布内容设置
免费版, 一般选择方式三,导入到自定义数据库access中。
4):文件保存及高级设置
这个一般不操作
如果报错:该任务您没有选择采网址,采内容的任何步骤,请检查任务====》任务首页,勾选任务右边三个复选框。
附:http://www.locoy.com/Buy/FunctionComparison/