使用AST树
第五章、使用AST树中间结果来计算表达式值
现在我们已经知道,通过创建ANTLR 语法文件 以及添加一些动作来实现一个“转换器”,这一章节将介绍另外一种方式来实现同样的功能,这需要额外用到一些树结构。我们将使用相同的grammar语法来创建一个中间数据结果,只是用树的创建规则来替换我们之前添加的一些动作。一旦,我们有了树结构,就可以用树解析器来解析树,并且执行一些动作。
ANTLR将会从grammar文件从创建一个树解析器。Parser grammar 会把输入的字符流转换成一个树结构,然后输解析器会对其解析求值。
尽管之前的方法更加直接,但是从语言规划来讲做得不够好。向grammar中添加方法调用、while循环,意味着,解析器要执行相同的代码多次。每当需要调用一个方法时,解析器需要重解析这个方法。因此相比较AST方法,之前的方法不够灵活,AST方法生成AST树来存储中间结果,再遍历树执行相关操作。很明显,重复遍历树比重复解析grammar效率更高。
一个中间结果通常是一棵树,树中节点不止是符号,还有表示符号间关系的节点。举例来说,下面的图表示了3+4这个表达式:
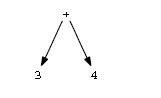
在许多例子中,你会看到树被表示成文本形式。比如,3+4可表示为(+ 3 4 )。括号后面第一个符号是根节点,随后的事他的孩子。表达式3+4*5的一颗AST树,文本形似为 (+ 3 (* 4 5)),如下图所示:
正如我们看到的,AST树结构严格表示了操作优先级。这里,乘法必须先被执行,因为加法需要乘法的结果作为操作参数。
AST不同于解析树,解析树代表了解析规则。下图展示了本例子中的解析树:
解析树的叶子节点是输入符号,非叶节点是规则名。根节点prog表示,3+4是一个prog。更具体的说是一个stat,而stat是由expr组成。所以解析树,记录了recognizer如何与输入进行匹配的。
在实际中,让语法和树解耦是非常有用的。因此,AST树不受解析树的影响。一个语法通常会改变解析树的结构但不会影响AST,这对处理AST树的代码来说很有意义。
一旦生成好了AST树,你可以有多种方式访问它,来计算你要的结果。一般来说,我建议你使用tree grammar 来生成访问树的代码。
在下一章节,你将学习如何创建AST树,怎样通过一个tree grammar访问它,如何在tree grammar中设置动作。最会,你会得到一个和之前有一样功能的转换器。
创建ASTS
为ANTLR创建AST是很简单的。我们需要在解析grammar里面设置树的创建规则,来指明我们需要怎样创建树。相比之前方法加入action,这里的语法更小,能更快被读写。当我们使用选项:option=AST,每个语法规则,将返回一个树节点,或者一颗子树。最顶层规则返回的树,将是一颗完整的AST树。
一开始我们需要告诉ANTLR我们需要创建AST树:
grammar Expr;
options {
output=AST;
// ANTLR can handle literally any tree node type.
// For convenience, specify the Java type
ASTLabelType=CommonTree; // type of $stat.tree ref etc...
}
如果仅仅这样设置,将会创建一颗平坦的AST树,每个匹配字符,都是一个AST节点,而AST树就是这些节点组成的列表。为了指定树的结构,我们需要简单的指明,哪些字符需要被考虑为操作,哪些不需要放到树中。我们分别使用^ 和 !这两个后缀。
现在我们修改规则如下:
expr: multExpr (('+' ^|'-' ^) multExpr)*
;
multExpr
: atom ('*' ^ atom)*
;
atom: INT
| ID
| '(' ! expr ')' !
;
我们只需要对+ - * ( )添加操作。!符号防止’(‘ ‘)’后面是告诉ANTLR不要为圆括号创建节点。
下面,我们要为prog和stat重写语法。为每种可能性添加规则:
/** Match a series of stat rules and, for each one, print out
* the tree stat returns, $stat.tree. toStringTree() prints
* the tree out in form: (root child1 ... childN)
* ANTLR's default tree construction mechanism will build a list
* (flat tree) of the stat result trees. This tree will be the input
* to the tree parser.
*/
prog: ( stat {System.out.println($stat.tree.toStringTree());} )+ ;
stat: expr NEWLINE -> expr
| ID '=' expr NEWLINE -> ^('=' ID expr)
| NEWLINE ->
;
->符号右边的语法是tree grammar 语法,他指明树的结构如何创建。^()里面的第一个元素是根节点,其余元素是他的孩子。你可以认为重写的规则是语法到语法的转换。有些时候,我们会看到,在tree grammar中精确的 树创建规则可能会有多种形式。Prog规则只是打印树,没有任何指定的树生成规则。默认的规则创建时,prog是有stat树组成的数组。
Stat第一种形式,直接返回expr生成的树结构。第二种形式,返回一颗子树,以 = 为根节点,ID 为第一个孩子,expr返回的树结构为第二个孩子。第三种形式,不创建任何树。