视频网站是怎么建成的--------JustinTV教你如何打造实时视频网站
Justin.TV每月有3000万个独立访问量,在游戏视频上传领域打败了YouTube ,他们每天每分钟新增30个小时的视频,而YouTube只有23。
下面从Justin.TV的实时视频系统使用到的平台,他们的架构细节,从他们身上应该学到的东西等几个方面逐一展开。
使用到的平台
- Twice —— 代理服务系统,主要用缓冲优化应用服务器负载
- XFS —— 文件系统
- HAProxy —— 用于TCP/HTTP负载平衡
- LVS stack and Idirectord —— 高可靠性
- Ruby on Rails —— 应用服务器系统
- Nginx —— web服务器系统
- PostgreSQL —— 数据库,用于用户和meta数据
- MongoDB —— 数据库,用于内部分析
- MemcachedDB —— 数据库,用于存放经常要修改的数据
- Syslog-ng —— 日志服务系统
- RabitMQ —— job系统
- Puppet —— 创建服务
- Git —— 源代码管理
- Wowza —— Flash/H.264视频服务器和许多Java写的custome modules
- Usher —— 播放视频流的逻辑控制服务器
- S3 —— 用于存储小型镜像
Justin.TV的一些统计数据
- 有覆盖全美的4个数据中心
- 在任何时候都有2000多个同时流入的数据流
- 每天每分钟新增30个小时的视频
- 每月有3000万个独立访问量(不计同一用户多次访问)
- 每秒实时的网络流量在45G左右
实时视频结构详述
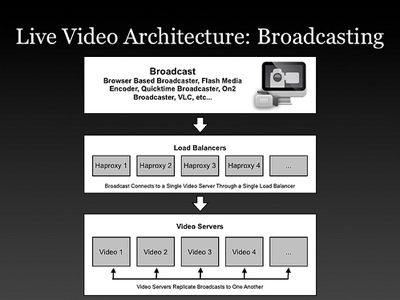
实时视频结构
1.使用了P2P和CDN
一般人认为,只需要不断提高带宽,把传来的数据都放入内存,不断的接收数据流就可以了,事实并非如此。实时视频要求不能打断,这就意味着你不可以超负荷的使用带宽。YouTube只需要让播放器缓冲一下,就可以用8G的带宽解决10G通道的需求,但在实时视频里,你不能缓冲,如果在信道上的流量超过了它的传输能力,哪怕只是一瞬间,那么所有的正在看的用户在那一刻都会卡。如果你在它的极限能力上再加入了一点儿负载,所有人立刻就会进入缓冲状态。
Justin.TV使用了点对点的结构来解决这个问题,当然他们也有更好的解决办法,CDN(内容分发网络)便是之一。当用户的流量负载超过Justin.TV的负载能力时,Justin.TV便很巧妙的将超标流量引入到一个CDN中去。Usher控制着这个处理逻辑。一旦接到了超标用户的负载请求,Usher便立刻将这些新用户转发到CDN中去。
2.100%可用时间和维护的矛盾
实时视频构建的系统既要保证100%的可用时间,又要保证机器可以进行维护。与一般网站不同,一般网站维护时出现的问题只有少数人会发现、关注,而实时视频网站不同,用户很快就会发现维护时带来的任何问题,并且互相传播的非常快,这就使得没有什么问题可以隐瞒用户,面对现在用户的挑剔,你必须避免维护时出问题。对一个服务器维护时,你不能主动结束用户的进程,必须等待所有在这个服务器上的用户自己结束服务才能开始,而这个过程往往非常缓慢。
3.Usher与负载均衡
Justin.TV遇到的最大的麻烦是即时拥塞,当大量的用户同时看同一个栏目的时候,便会突然产生突发网络拥塞。他们开发了一个实时的服务器和数据中心调度系统,它就是Usher。
Justin.TV的系统在突发的高峰拥塞上做了很多。他们的网络每秒可以处理大量的链入连接。用户也参与了负载均衡,这也是Justin.TV需要用户使用Justin.TV自己的播放器的原因之一。至于TCP,由于它的典型处理速度就是百kbps级的,所以也不用对TCP协议做什么修改。
相对于他们的流量,他们的视频服务器看来来有些少,原因是他们可以使用Usher把每个视频服务器的性能发挥到最好。负载均衡可以确保流量从不会超过他们的负载极限。负载大部分是在内存中,因此这个系统可以让网络的速度发挥到极限。服务器他们是一次从Rackable(SGI服务器的一个系列)买了一整套。他们做的仅仅是从所有预置的里面做了下挑选。
Usher是Justin.TV开发的一款定制化软件,用来管理负载平衡,用户认证和其他一些流播放的处理逻辑。Usher通过计算出每个流需要多少台服务器提供支持,从而分配资源,保证系统处于最优状态。这是他们的系统和别家不同之处。Usher通常会从下面几个指标计算、衡量某个流媒体所需要的服务器:
- 每个数据中心的负载是多少
- 每个服务器的负载是多少
- 延迟优化的角度
- 当前这个流可用的服务器列表
- 用户的国家(通过IP地址获得)
- 用户是否有可用的对等网(通过在路由数据库中查询IP地址获得)
- 请求来自于哪个数据中心
Usher使用这些指标便可以在服务净成本上来优化,把服务放在比较空闲的服务器上,或者把服务放在离用户较近的服务器上,从而给用户带来更低的延迟和更好的表现。Usher有很多个可以选择的模式从而达到很细的控制粒度。
Justin.TV系统的每个服务器都可以做边缘服务器,直接为用户输出视频流,同时每个服务器也可以做源服务器,为其他服务器传递视频流。这个特性,使得视频流的负载结构成了动态的,经常改变的一个过程。
4.服务器形成了加权树
服务器之间由视频流的拷贝而产生的联系和加权树非常相似。数据流的数量经常被系统取样、统计,如果观看某个视频流的用户数量飞速上涨,系统便将其拷贝很多份到一些其他的服务器上去。这个过程反复执行,最终就形成了一个树状的结构,最终会将网络中所有的服务器都画在里面。Justin.TV的视频流从源服务器出发,被拷贝到其他服务器,或者拷贝到用户的整个过程中,都处于内存中,没有硬盘路径的概念。
5.RTMP和HTTP
Justin.TV尽可能的使用了Flash,因为它使用RTMP协议,对每个视频流,系统都有一个独立的Session去维护它。由于使用这个协议,成本就相当高。由于下载流的ISP不支持,因而无法使用多路广播和P2P技术。Justin.TV确实想过用多路广播在内部服务器之间拷贝数据流,然而由于他们的系统控制覆盖整个网络,而且内部有大量的很便宜的带宽可以使用,这样使用多路广播的技术就并没有产生多少效益。同时,由于他们的优化算法是将每个服务器上的流数都最小化,这就使得在很细的力度上做些事情会非常麻烦,甚至超过了他们能得到收益。
Justin.TV的Usher使用HTTP请求去控制某个服务器负载哪个视频流,从而控制了服务的拓扑结构。Justin.TV在流数据上使用HTTP,但存在的一个问题是它没有延迟和实时方面的性能。有些人说实时的定义就是5-30秒,然而,面对数千人做实时视频的时候这显然不行,因为他们还需要实时的讨论,交流。这意味着延迟不能高于1/4秒。
6.从AWS到自己的数据中心
起初Justin.TV使用AWS,后来迁移到Akamai(云服务供应商),最后到了自己的数据中心。
离开AWS到Akamai的原因有:1,成本;2,网速不能满足他们的需求。视频直播对带宽非常敏感,因此有一个快速的,可靠的,稳定的和低延迟的网络非常关键。使用AWS时,你不能控制这些。它是一个共享的网络,常常超负载,AWS的网速不会比300Mbps更快。他们对动态范围改动和云API很重视,然而在性能和成本问题上没有做什么。
3年前,Justin.TV计算他们每个用户的成本,CDN是$0.135,AWS是0.0074,Datacenter是$0.001如今,他们的CDN成本降低了,但他们的数据中心的成本却仍然一样。
拥有多个数据中心的关键是为了能够接近所有的主要交换节点。他们选择国内最好的位置从而使得他们为国内最多的节点提供了入口。而且节约了成本。构建了这些数据中心后,他们就直接连入了这些其他的网络,从而就省去了之前处理这些中转流量的费用。还提高了性能。他们直接连入了他们所谓的"eyeball"网络。这个网络中包含了大量的cable/DSL用户。和"content"网络连接有些类似,Justin.TV的"eyeball"连接的流量主要来自终端用户。在大多数情况下,这些都是免费的,不用任何花一分钱,要做的就是连进来就行。Justin.TV有一个主干网,用于在不同的数据中心传输视频流。因为要到一个可用节点的选拔过程是去找愿意和你做对等节点的过程,这通常是很困难的。
7.存储
视频流不是从磁盘形成,而是要存到磁盘上去。源服务器将一个传入的视频流在本地磁盘上复制一份,之后便将这个文件上传到长期存储器上。视频的每一秒都被录下来并且存档了。
存储设备和YouTube类似,就是一个磁盘库。使用XFS文件系统。这个结构用于记录通过服务器传播的广播。默认的视频流是保存7天。用户可以手动的设置,甚至你可以保存到永远(如果公司没有倒闭的话)。
8.实时转码
增加了实时的转码功能,可以将任何一种流式数据转化为传输层数据或者是代码,并且可以用新的格式将它重新编为流媒体。有一个转码集群,用来处理转换工作。转换的会话使用job系统进行管理。如果需要的转码服务超过了集群的处理能力,那所有的服务器都可以用作转码服务器。
Web结构
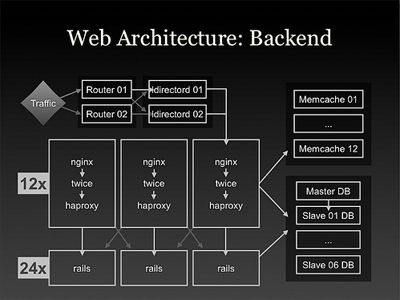
Web 结构
1.Justin.TV前端使用Ruby on Rails。
2.用Twice做缓存
系统个每个页面都使用了他们自己定制的Twice缓存系统。Twice扮演的角色是轻量级反向代理服务器和模板系统的合并角色。思路是对每一个用户,缓存每一个页面,然后将每个页面的更新再并入其中。使用Twice以后,每个进程每秒可以处理150条请求,同时可以在后台处理10-20个请求,这就扩展了7-10倍之前的服务器可以处理的网页的数量。大部分动态网页访问都在5ms以内。Twice有一个插件结构,所以它可以支持应用程序的一个特点,例如添加地理信息。
不用触及应用服务器,便能自动缓存像用户名一样的数据。
Twice是一个为Justin.TV的需求和环境而定制化开发的。如果开发一个新的Rails应用,使用Varnish或许是一个更好的主意。
3.网络流量由一个数据中心服务,其他的数据中心为视频服务。
4.Justin.TV 对所有的操作都做了监控.每一个点击,查看页面和每一个动作都被记录下来,这样就可以不断提高服务。前端,网络呼叫或者一个应用服务器的日志消息都被转换成系统日志消息,通过syslog-ngto转发。他们扫描所有的数据,将它装入MongoDB,使用Mongo执行查询。
5.Justin.TV的API来自网站的应用服务器。它使用相同缓冲引擎,通过扩展网站来扩展他们的API.
6.PostegreSQL是他们最主要的数据库。结构式是简单的主从结构,由一个主机和多个从属读数据库组成。
由于他们网站的类型,他们不需要许多写数据库。缓冲系统控制着这些读数据库。他们发现PostgreSQL并不擅长处理写操作。因此Justin.TV就是用MemcachedDB去处理那些经常要写的数据,例如计数器。
7.他们有一个聊天服务器集群,专门用来为聊天功能服务。如果用户进入了一个频道,用户就会有5个不同的聊天服务器为他服务。扩展聊天功能要比扩展视频功能简单的多。用户可以被划分到不同的房间,这些房间又由不同的服务器负载。他们也不会让100,000个人同时在一起聊天。他们限制每个房间200人,这样就可以在一个小组里进行更有意义的交谈。这同时对扩展也很有帮助,这真的是一个很聪明的策略。
8.AWS用于存储文档镜像。他们没有为存储许多小镜像而开发专门的系统,他们使用了S3。它非常方便,而且很便宜,这就不用在他们上面花更多的时间了。他们的镜像使用频率很高,所有他们是可缓冲的,也没有留下什么后续问题。
网络拓扑结构设计
网络拓扑结构非常简单。每个服务器机架顶都有一对1G的卡。每个机架都有多个10G的接口,接口连接到外部的核心路由器。他们使用Dell Power Edge交换机,这些交换机对L3(TCP/IP)并不是完全支持,但是比L2(ethernet)要好的多。每个交换机每天要传输20G的数据,而且很便宜。核心路由器是思科的6500的系列。Justin.TV想要将节点最小化,从而让延迟降低,并且降低每个packet的处理时间。Usher管理着所有的接入控制和其他的逻辑,而不仅仅限于网络硬件。
使用多个数据中心可以充分利用对等网的优势,把流量转移到离用户最近的地方。和其他的网络和节点的连接非常多。这样就有多个可选的传输途径,所以可以使用最好的那个路径。如果他们遇到了网络的拥塞,就可以选择一条别的路。他们可以通过IP地址和时间,找到对应的ISP。
开发和部署
他们使用Puppet服务器主机,有20中不同种类的服务器。从数据库中出来的任何东西都要经过缓存器。使用Puppet他们可以把这个缓存器变成他们想要的任何东西。
他们有两个软件队伍。一个是产品队伍,另一个是硬件基础设施队伍。他们的队伍非常小,大概每个队伍只有7-8个人。每个队伍都有一个产品经理。他们雇佣一般的技术员,但却雇佣了网络结构和数据库相关的专家。
他们使用了基于网络的开发系统,所以每个新的改动都会在几分钟内完成。QA必须在变成产品之前完成,在这里通常需要5-10分钟。
Justin.TV使用Git管理源代码。Justin.TV喜欢Git的这个功能,你可以写一个程序副本,20-30行,然后它可以融合到其他人手里正在修改的副本。这个工作是独立的,模块化的。在你不得不撤销你提交的副本时,你可以很容易就修改或者撤销你的代码。每过几天每个人都会试着将自己的代码副本融入到主代码中去消除冲突。他们每天对软件做5-15个修改。范围从1行代码中的bug到大范围的测试都有。
数据库模式通过手动更新完成。将他们复制的数据库副本迁移到一起就会形成一个最新的动态记录的版本。在把改动最终应用到产品之前会在许多不同的环境下对其进行测试。
Puppet管理配置文件。每个小的改动基本上就是一个实验。他们会追踪每个对核心文件的改动的影响和之前的版本。这些测试很重要,因为通过它他们可以找出哪些改动是真正提高他们关心的指标。
Justin.TV的未来
他们的目标是增加一个数量级。首先要切分他们的视频元数据系统。由于流数据和服务器的大幅增长,他们的元数据负载也指数级的爆发增长,因此,他们需要将其大范围进行切分。对于网络数据库,将使用Cassandra对其进行拆分。其次,为了灾后恢复,要对核心数据中心进行备份。
学到的东西
- 自己开发还是购买。他们在这个问题上已经做了很多错误的决策。例如,他们起初应该买一台视频服务器而不是自己去做了一台。软件工程师喜欢将软件做的个性化,然后使用开源社区维护的东西却有很多益处。因此他们提出了一个更好的流程去做这个决定:1.这个项目是活动?还是维护?还是修补漏洞?2.有其他的人要用它么?你能向别人请教下该如何定义它?3.扩展性的问题。他们必须去做改变。4.如果我们自己开发,我们可以做到更快,更好,还是我们可以获得更多我们需要的特性呢? 就像使用Usher,他们考虑他们可否创造一个新的外部特性,并且和另外一个系统交互。把Usher做为视频扩展性的核心针对相对笨拙的视频服务器来说是一个非常好的决策的例子。
- 关注自己做的事情,不要在意别人怎么干。他们的目标是有用最好的系统,最多的服务时间和最完美的扩展性。他们用了3年去开发能管理百万个广播并发的技术。
- 不要外包。你学到的核心价值在于经验,而不是代码或者硬件。
- 把一切都当做实验来做。对所有的东西都进行测量。局部测试,追踪,测量。这很划算。从一开始就做。使用优秀的测量工具。例如,他们在复制的URL上附加一个标签,然后就可以知道你是否分享了这个链接。他们从不测量的一段时间走到了如今高度测量。通过重写广播进程,使得他们的会话数量增长了700%。他们想要网站运行更快,响应更快,网页装载更快,视频服务更好。系统挤出的每一毫秒的延迟都带来了更多的广播者。他们有40个实验,如果他们希望让一个用户变成一个广播者。对每个实验他们都想要看一下广播后的留存率,广播的可用性,会话率,然后对每个改动都做一个明智的决策。
- 最重要的一件事是理解你的网站如何共享服务,怎么优化它。他们通过减少共享的链接在菜单中的深度,成功的提高了500%的分享率。
- 使用公共的构建模块和基础设施意味着系统将立刻识别什么是重要的,然后执行。具有网络能力很重要,这也是他们应该从开始就关注的地方。
- 让系统忙起来。使用系统的所有能力。为什么要把钱放在桌子上呢?构建可以通过应答对系统进行合理的分配的系统。
- 对不重要的事情不要浪费时间。如果它非常方便并且不用花费多少,就没有必要在它上面花费时间。使用S3去存储镜像就是一个很典型的例子。
- 试着为用户想做的事情提供支持,而不是做你认为用户该这样使用的东西。Justin.TV的终极目标似乎是把所有人都变成一个广播点。在用户实验时,通过尽可能的走出用户的使用方式,他们试着让这个过程变得尽可能简单。在这过程中,他们发现,游戏是一个巨大的用力。用户喜欢将Xbox截图出来,并且与大家分享,讨论它。很有可能有些东西是你没想过要放在商务计划里的。
- 为负载峰值做设计。如果你只为了静态的状态做了设计,之后你的网站将会在峰值来临时垮掉。在直播时,这通常是一个大事,如果你陷入了这个麻烦,很快人们就开始传播对你不利的话。为峰值负载进行设计需要使用一个所有层次的技术。
- 让网络结构保持简单。使用多数据中心。使用点对点网络连接结构。
- 不要担心将东西划分到更多的可扩展块中去。例如,与其使用一个100,000人的频道,不如将他们划分到更多的社会和可扩展的频道去。
- 实时系统不能隐藏来自用户的任何问题,这就是的说服用户你的网站很可靠变的很困难。由于他们和实时系统之间的联系是固定的,这会使的系统的每个问题和故障都让大家知道。你藏不住。每个人都会发现。并且每个人都会通过交流传播发生了什么。很快,用户就会有一个你的网站有很多问题的感觉。在这种情况下,和你的用户交流就变得很重要,从一开始就构建一个可信赖的,高质量的,可扩展的,高性能的系统,设计一个用户用起来尽可能简单和舒服的系统。(编译:@康文博/审校:仲浩)
原文:Gone Fishin': Justin.Tv's Live Video Broadcasting Architecture