亚马逊、谷歌、苹果云端宕机背后的故事
亚马逊、谷歌、苹果云端宕机背后的故事
在10月22日(上周一),Amazon云服务AWS东部地区又出宕机问题,对Reddit, Airbnb, Flipboard, GetGlue, Coursera等多家知名网站造成了影响,不过在受到影响区域以外的EC2和EBS都显示正常,客户还可以进行迁移。此次事件的阴霾还未散尽,在10月26日(上周五),Google App Engine宕机,10月30日,苹果iCloud也出现了一点点小麻烦。作为云计算行业的领军人物,三巨头最近的日子都不是太顺。不过这也侧面反映了云计算对我们生活、工作的影响力越来越大。
亚马逊宕机事件
尽管2011年亚马逊AWS也出现了一些问题,但远远没有2012年这么频繁。从之前6月份由于电力系统的故障,进而影响了AWS的客户之后(2012年6月14日Amazon云服务故障分析),在7月份因为雷击再次造成数据中心宕机,又影响了一批客户的正常使用,(风暴击倒亚马逊数据中心,舆论一边倒?),此次事件发生之后,AWS官方网站对本次宕机事件做出了解释,而且告诉用户AWS正在做的工作,以防止未来再次发生类似的问题。

周一 10:00 AM PDT:美国东部地区的亚马逊弹性块存储(EBS)的性能发生下降,在某些情况下,无法进一步处理I / O请求。问题的根源是运行在EBS存储服务器上的数据收集代理有一个潜在的Bug。每一个EBS存储服务器的代理都关联着一组数据收集服务器和用来维护的报告信息。该数据收集系统的数据是非常重要的,但是对时间却不敏感,因为该系统的设计仅仅容忍延迟或者丢失的数据。
上周,该地区的一个数据收集服务器因为硬件故障被换下。不过替换该服务器部分的一个DNS记录已更新,删除了故障服务器并且添加来了替换服务器。不过在那个时候没有注意到,DNS更新没有成功地传播到所有的内部DNS服务器之上,结果,存储服务器的一小部分并得到没有更新的服务器地址,而且继续尝试联系原来的数据收集服务器。但是由于设计的数据收集服务容忍丢失数据,显然这并不会造成任何直接的问题而且没有发出何报警。然而,因为无法联系到的数据收集服务器,存储服务器上的报告代理引发了潜在的内存泄漏错误:报告代理并没有处理连接失败的问题,而是继续以尝试联系数据收集服务器的方式,慢慢地消耗系统内存。
尽管AWS监控着每个EBS服务器的总内存消耗,但是监控系统没有对此内存的泄漏进行报警。而且EBS服务器动态地使用所有的可用内存用于管理客户数据,因此很难对内存的使用和释放内存进行准确的警报设置。星期一早上,内存消耗的速度已经非常高了,直接影响到存储服务器,它们无法跟上正常的请求处理。
到目前为止,亚马逊已经部署了监测预警系统,对内存泄漏问题进行重点关注。与此同时,也修正了EBS存储服务器上的系统内存监控,从而保证对每个进程的内存消耗进行监控和预警,AWS还将部署资源限制,以防止低优先级的进程消耗过多的主机资源。很关键的部分,AWS更新了内部的DNS配置,以进一步确保DNS的信息更改被可靠的传播,最重要的是,确保AWS的监管的完善性,这些行动完全解决了引发这次事件的问题。此外,AWS正在评估在事件的迅速恶化之前,如何更改EBS故障转移逻辑。亚马逊相信,他们有能力作出调整,从而减少任何类似的相关EBS服务器故障或退化的影响。(原文)
亚马逊在最后表达了深深的歉意:“给您带来不便以及造成的影响,我们深表歉意。我们知道AWS服务对客户业务来说是多么的重要,我们将会更加努力的工作,从本次事件中认真吸取教训,我们看到先前的改变也减轻了本次事件一些影响,而且我们也了解了新的故障模式,在未来的日子里,我们会花很多时间改善我们的服务。”
在亚马逊宕机事件发生后,一位国外网友打趣说:亚马逊又宕机了呀,为什么亚马逊不把Amazon.com放在自己的云服务器上呢?另一位专业网友则在网上留言指责亚马逊无法提供风险预警服务,导致大量网站屡次在毫无征兆的情况下经历长时间的宕机,给网站造成重大损失。
为什么亚马逊频频出现这么多问题,我们依然还会选择它?因为我们知道,AWS目前是最好的云服务,对于大多数用户来说,无论他们遭受到了多么严重的影响,他们还是会选择亚马逊,因为亚马逊帮助他们用较少的成本和精力运营着一个强大的基础架构。许多人在批评亚马逊之前都会首先感谢亚马逊帮助他们做到的事情。因为到目前为止,还没有一家公司能够取代亚马逊!我们也很欣喜地看到OpenStack的蓬勃发展,但是在商用平台始终还是一大软肋,目前绝对不是亚马逊的对手。
谷歌宕机事件
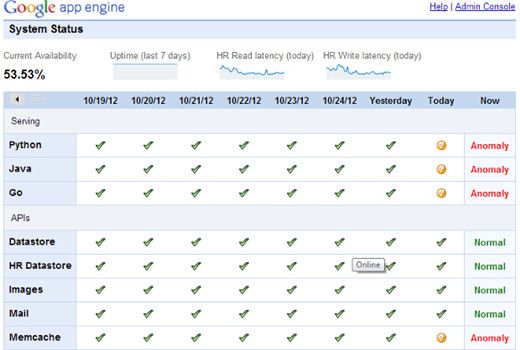
其实,谷歌可以真正算得上一个“云计算”公司,因为云计算的最早提出者是Google公司的高级工程师,克里斯托夫·比希利亚。2006年秋,他向谷歌董事长兼CEO施密特提出了“云计算”这一计划。如果提及谷歌的云计算,那么不得不说GAE(Google App Engine)。Google App Engine 提供一整套开发组件让用户轻松地在本地构建和调试网络应用,之后能让用户在Google强大的基础设施上部署和运行网络应用程序,并自动根据应用所承受的负载对应用进行扩展,免去用户对应用和服务器等的维护工作。同时提供大量的免费额度和灵活的资费标准。不过很不幸,上周五Google App Engine 也宕机了!虽然在8个小时后,谷歌服务恢复正常。但是影响还是存在的。不过让人惊奇的是,谷歌公司很少谈及“云计算”,作为云计算的“鼻祖”,貌似有点太低调了,按照谷歌的说法:“Internet将永生,我们将无处不在。”虽然宕机事件发生,似乎对谷歌影响甚微,相信没有人敢否认谷歌在云计算中的地位。
苹果iCloud出了点小麻烦
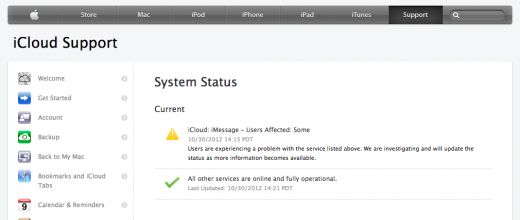

毋庸置疑,iCloud是苹果未来愿景的核心部分:“它不仅仅是一个产品,它是未来十年苹果的重点战略!”苹果公司的首席执行官库克在1月宣布:未来所有的设备都应该实现与iCloud无缝地协作,而且iCloud也是最重要的部分。在任何地方,它都能将用户连接到他们的设备,服务和内容。iCloud拥有超过190万用户,而且还在继续增长之中,任何宕机都会影响到很多人。更重要的是,这个问题同时影响着所有的苹果iOS设备,包括iPad,iPhone,甚至苹果电脑,因为iCloud在所有的这些平台上被广泛的使用。在10月30日,苹果的iCloud也遇到了一点点麻烦!用户表示他们在访问iMessage,Apps Store,Game Center以及可能更多地方的时候出现了一些问题。苹果公司的系统状态网页也已经确认该消息,他们正在进行调查。不过似乎也没有人对苹果iCloud的宕机做出太大的反应,虽然乔布斯已经挂帆仙逝,但是苹果似乎没有任何的颓废之势,反而在库克的领导下,发展的很平稳,即使少了一些创新,但是也没人敢小窥这个“庞然大物”。
国内平台更不让人放心
其实云计算目前还存在的问题,云计算巨头的三次宕机事件,其实也给我们敲响了警钟,云计算不是万能的,它本身也存在着很多问题,但是我们绝对不能以此否定云计算的发展。而且在保证应用程序的高可用性和数据的安全性上,极少有一家公司可以拥有像亚马逊、谷歌和苹果这些云计算服务供应商那样的实力,这根本不是一个数量级上的比较。我们对亚马逊、谷歌以及苹果宕机反应强烈只不过是我们对云计算抱有不切实际的期望(100%高可用性)。殊不知我们对自己公司的服务器经常宕机已经习以为常了。我们可以看看国内的平台问题:
- 京东商城网站出现漏洞,损失2亿多:京东商城充值平台(chongzhi.360buy.com)出现漏洞,积分可以无限制刷Q币话费,有人甚至充了36万话费,还有包括套Q币,彩票等损失惨重,预计京东亏损2个亿左右。据说京东已报案,具体处理措施还没出来。目前漏洞已修复!
- 2012年10月30日下午16:40开始,阿里巴巴集团旗下的著名的云计算服务商阿里云发生了电力故障,有客户反映其造成了宕机。
- 盛大,国内云供应商巨头。其产品一直保持着节约成本、弹性扩展、提高效能、安全可靠等特色。然而继4月“麦库记事本”发生故障后,在8月6日发生了机房服务器磁盘损坏,直接导致用户资料丢失。这无疑在云安全上给国内云供应商敲响了警钟。
云计算并不可能万无一失,“出来混,迟早要还的!”
云服务用户首先要承认云服务提供商在保证高可用性上还要继续努力,但是它也不应该成为质疑或反对云计算的理由。另外一点就是高可用性不是与生俱来的,而是要求用户必须做好系统的设计,充分利用云计算提供的机制,而不是把应用程序扔到云端就万事大吉了。其实云计算和其他基础设施一样,不可能是万无一失的,系统和应用在设计时本来就应该为故障做好准备,这点云计算企业应该向一些大公司学习。不过也有很牛的公司并没有受到影响,在上一年4月份,亚马逊的宕机中,Twilio并没有受到影响,当时他们还写了一篇博客文章,分享了自己的经验,文章会在后续推出,敬请期待!(编译/@CSDN王鹏,审校/包研)
亚马逊宕机事件新浪微博热点评论:
@ztyan: 简单的汇总:1. 减少依赖,使得服务能够简单的部署在一个盒子上。 2. 快速的失败侦测以及重试。3. 幂等的服务。4. 将业务逻辑分解成小的无状态服务。5. 如果没有强一致性要求, 读写分离。
@Syupei 艺龙网平台总监:我有一个观点是,“系统中总有一处单点是你永远也无法消除的”。不把这些托付给云,意味着你仍要去搭建一套差不多的体系,以及在这套体系出现问题时如何去快速响应的机制。所以,如果需要在此做出取舍衡量的话,那就仅仅是谈成本而已了。