操作系统、网络重要知识点
(一)并发和并行的区别
并发行和并行性的区别可以用馒头做比喻。前者相当于一个人同时吃三个馒头和三个人同时吃一个馒头。
并发性(Concurrence):指两个或两个以上的事件或活动在同一时间间隔内发生。并发的实质是一个物理CPU(也可以多个物理CPU) 在若干道程序之间多路复用,并发性是对有限物理资源强制行使多用户共享以提高效率。
并行性(parallelism)指两个或两个以上事件或活动在同一时刻发生。在多道程序环境下,并行性使多个程序同一时刻可在不同CPU上同时执行。
区别:
一个处理器同时处理多个任务和多个处理器或者是多核的处理器同时处理多个不同的任务。
前者是逻辑上的同时发生(simultaneous),而后者是物理上的同时发生。
两者的联系:
并行的事件或活动一定是并发的,但反之并发的事件或活动未必是并行的。并行性是并发性的特例,而并发性是并行性的扩展。
(二)管程机制浅析
一、 管程的概念
1. 管程可以看做一个软件模块,它是将共享的变量和对于这些共享变量的操作封装起来,形成一个具有一定接口的功能模块,进程可以调用管程来实现进程级别的并发控制。
2. 进程只能互斥得使用管程,即当一个进程使用管程时,另一个进程必须等待。当一个进程使用完管程后,它必须释放管程并唤醒等待管程的某一个进程。
3. 在管程入口处的等待队列称为入口等待队列,由于进程会执行唤醒操作,因此可能有多个等待使用管程的队列,这样的队列称为紧急队列,它的优先级高于等待队列。
二、 管程的特征
1. 模块化。
管程是一个基本的软件模块,可以被单独编译。
2. 抽象数据类型。
管程中封装了数据及对于数据的操作,这点有点像面向对象编程语言中的类。
3. 信息隐藏。
管程外的进程或其他软件模块只能通过管程对外的接口来访问管程提供的操作,管程内部的实现细节对外界是透明的。
4. 使用的互斥性。
任何一个时刻,管程只能由一个进程使用。进入管程时的互斥由编译器负责完成。
三、 enter过程、leave过程、条件型变量c、wait(c) 、signal(c)
1. enter过程
一个进程进入管程前要提出申请,一般由管程提供一个外部过程--enter过程。如Monitor.enter()表示进程调用管程Monitor外部过程enter进入管程。
2. leave过程
当一个进程离开管程时,如果紧急队列不空,那么它就必须负责唤醒紧急队列中的一个进程,此时也由管程提供一个外部过程—leave过程,如Monitor.leave()表示进程调用管程Monitor外部过程leave离开管程。
3. 条件型变量c
条件型变量c实际上是一个指针,它指向一个等待该条件的PCB队列。如notfull表示缓冲区不满,如果缓冲区已满,那么将要在缓冲区写入数据的进程就要等待notfull,即wait(notfull)。相应的,如果一个进程在缓冲区读数据,当它读完一个数据后,要执行signal(notempty),表示已经释放了一个缓冲区单元。
4. wait(c)
wait(c)表示为进入管程的进程分配某种类型的资源,如果此时这种资源可用,那么进程使用,否则进程被阻塞,进入紧急队列。
5. signal(c)
signal(c)表示进入管程的进程使用的某种资源要释放,此时进程会唤醒由于等待这种资源而进入紧急队列中的第一个进程。
四、 应用实例
案例一:生产者消费者问题。生产者进程将产品放入某一缓冲区,消费者进程到此缓冲区中取产品。这个过程必须保证:1. 当缓冲区有剩余空间时,生产者才能在其中放入产品;2. 当缓冲区有数据时,消费者才能在其中取出产品。
解决方案:使用管程机制来实现生产者和消费者之间的同步互斥问题
1. 假设有一基本管程monitor,提供了enter、leave、signal、wait等操作;
2. 条件变量notfull表示缓冲区不满,条件变量notempty表示缓冲区不空;
3. 缓冲区buff[0...n-1]用来存放产品,最大可放n件产品;
4. 定义整型变量count表示缓冲区当前的产品数,指针in指向缓冲区当前第一个空的位置,指针out指向缓冲区当前第一个不空的位置;
5. 定义过程add(ItemType item)
add(ItemTypeitem) //生产者进程在缓冲区放入产品
{
if(count==n) wait(notfull);
//如果此时缓冲区已满,那么进程必须等待notfull,这意味着进程已经被阻塞到紧急队列里
buff[in]=item; //否则在第一个空的位置放入产品
in=(in+1)%n; //指针循环加1
count++;
signal(notempty);
//此时缓冲区已经多了一个产品,也就是说生产者进程去唤醒因取不到产品被阻塞的消费者进程
}
6. 定义过程ItemType remove()
ItemType remove() //消费者进程在缓冲区取出产品
{
if(count==0) wait(notempty);
//如果缓冲区没有产品,那么消费者必须等待notempty,也就是被阻塞到紧急队列中去
item=buff[out]; //消费者从第一个不空的位置取出产品
out=(out+1)%n;
signal(notfull);
//此时缓冲区多了一个空的单元,也就是消费者进程去唤醒因缓冲区已满而不能放入产品的生产者进程
return item;
}
7. 生产者进程代码段
while(true)
{
produce(&item); //生成出一件产品
monitor. enter(); //进入管程
monitor. add(); //调用add方法,放入产品
monitor. leave(); //离开管程
}
8. 消费者进程代码段
while(true)
{
monitor. enter();
item=monitor. remove(); //取出产品
monitor. leave();
consumer(&item); //进行消费
}
案例二:读者—写者问题。现有一个缓冲区,有若干读者进程和若干写者进程。读者进程在缓冲区读数据,写者进程在缓冲区写入数据。这个过程必须保证:1. 读者进程之间不需要互斥;2.写者进程之间必须互斥,即当一个写者进程在缓冲区写入数据时,别的写者进程必须被阻塞;3. 读者进程和写者进程必须互斥,即当有读者进程在读数据,写者进程必须被阻塞,有写者进程在写数据时,读者进程必须被阻塞。
解决方案:采用管程机制来解决读者—写者问题
1. 假设已经有一个基本管程Monitor提供了enter、leave、signal、wait等操作;
2. 定义条件变量r表示可以对缓冲区读,条件变量w表示可以对缓冲区写;
3. 定义布尔类型变量IsWriting表示当前有写者进程在缓冲区写数据;
4. 整型变量read_count表示读数据的个数;
5. 定义过程startRead()
void startRead()
{
if(IsWriting) wait(r);
//此时缓冲区有写者进程在写数据,那么读者进程等待r,也就是读者进程被阻塞到紧急队列中
read_count++; //否则,读出数据
signal(r); //唤醒被阻塞的读者进程
}
6. 定义过程endRead()
void endRead()
{
read_count--;
if(read_count= =0) signal(w);
// 此时表示所有读者进程都已经读完数据,那么唤醒被阻塞的写 者进程
}
7. 定义过程startWrite
void startWrite()
{
if(read_count!=0 || IsWriting) wait(w);
//此时表示如果有读者进程存在或者其他写者进程存在,那么将要写数据的写者进程被阻塞
IsWriting=true;
}
8. 定义过程endWrite()
void endWrite()
{
IsWriting=false;
if(r!=null) signal(r);
//如果有读者进程存在,那么唤醒读者进程
else signal(w); //否则唤醒写者进程
}
9. 读者进程代码段
while(true)
{
Monitor. enter();
Monitor. startRead();
read();
Monitor. endRead();
Monitor. leave();
}
10. 写者进程代码段
while(true)
{
Monitor. enter();
Monitor. startWrite();
write();
Monitor. endWrite();
Monitor. leave();
}
注:需要互斥的操作放在管程之间
(三) 磁道、柱面、扇区、磁盘簇、寻道时间、旋转延迟、存取时间

1.磁道
以盘片中心为圆心,用不同的半径,划分出不同的很窄的圆环形区域,称为磁道。
2.柱面
上下一串盘片中,相同半径的磁道所组成的一个圆柱型的环壁,就称为柱面。
3.扇区
磁盘上的每个磁道被等分为若干个弧段,这些弧段便是磁盘的扇区.扇区是磁盘最小的物理存储单元
4.磁盘簇(windows)
windows将相邻的扇区组合在一起,形成一个簇,然后再对簇进行管理
5.寻道时间
磁头从开始移动到移动到数据所在磁道所需要的时间
6.旋转延迟

首先,读写头(磁头)沿径向移动,移到要读取的扇区所在磁道的上方,这段时间称为寻道时间(seek time)。
然后,通过盘片的旋转,使得要读取的扇区转到读写头的下方,这段时间称为旋转延迟时间(rotational latency time)。
例:一个7200(转 /每分钟)的硬盘,每旋转一周所需时间为60×1000÷7200=8.33毫秒,则平均旋转延迟时间为8.33÷2=4.17毫秒
(最多旋转1圈,最少不用旋转,平均情况下,需要旋转半圈)。
7.存取时间
平均寻道时间与平均旋转延迟时间之和称为平均存取时间(average access time)
8 硬盘与磁盘
磁盘=硬盘=驱动器 他们指的是同一个外存储器。 你的计算机上装的操作系统和软件都是装在它里面的
二者都是存储介质,有的是只读性的(光盘,也算磁盘),有的可读可写(硬盘),没有必要知道他们的定义,理解了就可以了
主存存取原理
目前计算机使用的主存基本都是随机读写存储器(RAM),现代RAM的结构和存取原理比较复杂,这里本文抛却具体差别,抽象出一个十分简单的存取模型来说明RAM的工作原理。
图5
从抽象角度看,主存是一系列的存储单元组成的矩阵,每个存储单元存储固定大小的数据。每个存储单元有唯一的地址,现代主存的编址规则比较复杂,这里将其简化成一个二维地址:通过一个行地址和一个列地址可以唯一定位到一个存储单元。图5展示了一个4 x 4的主存模型。
主存的存取过程如下:
当系统需要读取主存时,则将地址信号放到地址总线上传给主存,主存读到地址信号后,解析信号并定位到指定存储单元,然后将此存储单元数据放到数据总线上,供其它部件读取。
写主存的过程类似,系统将要写入单元地址和数据分别放在地址总线和数据总线上,主存读取两个总线的内容,做相应的写操作。
这里可以看出,主存存取的时间仅与存取次数呈线性关系,因为不存在机械操作,两次存取的数据的“距离”不会对时间有任何影响,例如,先取A0再取A1和先取A0再取D3的时间消耗是一样的。
磁盘存取原理
上文说过,索引一般以文件形式存储在磁盘上,索引检索需要磁盘I/O操作。与主存不同,磁盘I/O存在机械运动耗费,因此磁盘I/O的时间消耗是巨大的。
图6是磁盘的整体结构示意图。
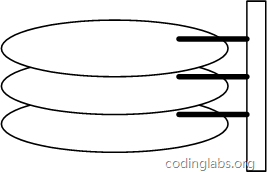
图6
一个磁盘由大小相同且同轴的圆形盘片组成,磁盘可以转动(各个磁盘必须同步转动)。在磁盘的一侧有磁头支架,磁头支架固定了一组磁头,每个磁头负责存取一个磁盘的内容。磁头不能转动,但是可以沿磁盘半径方向运动(实际是斜切向运动),每个磁头同一时刻也必须是同轴的,即从正上方向下看,所有磁头任何时候都是重叠的(不过目前已经有多磁头独立技术,可不受此限制)。
图7是磁盘结构的示意图。

图7
盘片被划分成一系列同心环,圆心是盘片中心,每个同心环叫做一个磁道,所有半径相同的磁道组成一个柱面。磁道被沿半径线划分成一个个小的段,每个段叫做一个扇区,每个扇区是磁盘的最小存储单元。为了简单起见,我们下面假设磁盘只有一个盘片和一个磁头。
当需要从磁盘读取数据时,系统会将数据逻辑地址传给磁盘,磁盘的控制电路按照寻址逻辑将逻辑地址翻译成物理地址,即确定要读的数据在哪个磁道,哪个扇区。为了读取这个扇区的数据,需要将磁头放到这个扇区上方,为了实现这一点,磁头需要移动对准相应磁道,这个过程叫做寻道,所耗费时间叫做寻道时间,然后磁盘旋转将目标扇区旋转到磁头下,这个过程耗费的时间叫做旋转时间。
局部性原理与磁盘预读-----------------好
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:
当一个数据被用到时,其附近的数据也通常会马上被使用。
程序运行期间所需要的数据通常比较集中。
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
四 Linux/windows 进程/线程间通信机制
(1 ) Linux进程间通信
linux下进程间通信的几种主要手段简介:
一。管道(pipe)
管道是Linux支持的最初IPC方式, 管道可分为无名管道,有名管道等。(一)无名管道,它具有几个特点:
1) 管道是半双工的,只能支持数据的单向流动;两进程间需要通信时需要建立起两个管道;2) 无名管道使用pipe()函数创建,只能用于父子进程或者兄弟进程之间;
3) 管道对于通信的两端进程而言,实质上是一种独立的文件,只存在于内存中;
4) 数据的读写操作:一个进程向管道中写数据,所写的数据添加在管道缓冲区的尾部;另一个进程在管道中缓冲区的头部读数据。
(二)有名管道
有名管道也是半双工的,不过它允许没有亲缘关系的进程间进行通信。具体点说就是,有名管道提供了一个路径名与之进行关联,以FIFO(先进先出)的形式存在于文件系统中。这样即使是不相干的进程也可以通过FIFO相互通信,只要他们能访问已经提供的路径。值得注意的是,只有在管道有读端时,往管道中写数据才有意义。否则,向管道写数据的进程会接收到内核发出来的SIGPIPE信号;应用程序可以自定义该信号处理函数,或者直接忽略该信号。
因此,除具有管道所具有的功能外,它还允许无亲缘关系进程间的通信;
二。信号量(semophore)
信号量是一种计数器,可以控制进程间多个线程或者多个进程对资源的同步访问,它常实现为一种锁机制。实质上,信号量是一个被保护的变量,并且只能通过初 始化和两个标准的原子操作(P/V)来访问。(P,V操作也常称为wait(s),signal(s))。主要作为进程间以及同一进程不同线程之间的同步手段。三。信号(Signal)
信号是Unix系统中使用的最古老的进程间通信的方法之一。操作系统通过信号来通知某一进程发生了某一种预定好的事件;接收到信号的进程可以选择不同的方式处理该信号,一是可以采用默认处理机制-进程中断或退出,一是忽略该信号,还有就是自定义该信号的处理函数,执行相应的动作。内核为进程生产信号,来响应不同的事件,这些事件就是信号源。 信号源可以是:异常,其他进程,终端的中断(Ctrl-C,Ctrl+\等),作业的控制(前台,后台进程的管理等),分配额问题(cpu超时或文件过大等),内核通知(例如I/O就绪等),报警(计时器)。
除了用于进程间通信外,进程还可以发送信号给进程本身;linux除了支持Unix早期信号语义函数sigal外,还支持语义符合Posix.1标准的信号函数sigaction(实际上,该函数是基于BSD的,BSD为了实现可靠信号机制,又能够统一对外接口,用sigaction函数重新实现了signal函数.
四。消息队列(Message Queue)
消息队列就是消息的一个链表,它允许一个或者多个进程向它写消息,一个或多个进程向它读消息。Linux维护了一个消息队列向量表:msgque,来表示系统中所有 的消息队列。 具体包括Posix消息队列system V消息队列。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。消息队列克服了信号传递信息少,管道只能支持无格式字节流和缓冲区受限的缺点。
五。共享内存(shared memory)
共享内存映射为一段可以被其他进程访问的内存。该共享内存由一个进程所创建,然后其他进程可以挂载到该共享内存中。 共享内存是最快的IPC机制,但由于 linux本身不能实现对其同步控制,需要用户程序进行并发访问控制,因此它一般结合了其他通信机制实现了进程间的通信,例如信号量。六 套接字(socket)
socket也是一种进程间的通信机制,不过它与其他通信方式主要的区别是:它可以实现不同主机间的进程通信。一个套接口可以看做是进程间通信的端点(endpoint),每个套接口的名字是唯一的;其他进程可以访问,连接和进行数据通信。起初是由Unix系统的BSD分支开发出来的,但现在一般可以移植到其它类Unix系统上: Linux和System V的变种都支持套接字。(Socket是对TCP/IP层的封装,URL(java中的类)是对Socket的封装)
(2) Linux线程间通信:互斥体,信号量,条件变量
(3) Windows线程间通信:互斥量(Mutex)、信号量(Semaphore)、事件(Event)、临界区(Critical Section)
(4) Windows 进程间通信:管道、内存共享、消息队列、信号量、socket
Windows 进程和线程共同之处:信号量和消息(事件)
临界区(Critical section)与互斥体(Mutex)的区别
1、临界区只能用于对象在同一进程里线程间的互斥访问;互斥体可以用于对象进程间或线程间的互斥访问。
2、临界区是非内核对象,只在用户态进行锁操作,速度快;互斥体是内核对象,在核心态进行锁操作,速度慢。
3、临界区和互斥体在Windows平台都下可用;Linux下只有互斥体可用
Windows线程间通信的区别:
1.互斥量与临界区的作用非常相似,但互斥量是可以命名的,也就是说它可以跨越进程使用。所以创建互斥量需要的资源更多,所以如果只为了在进程内部是用的话使用临界区会带来速度上的优势并能够减少资源占用量。因为互斥量是跨进程的互斥量一旦被创建,就可以通过名字打开它。互斥体不仅能实现同一应用程序的公共资源安全共享,还能实现不同应用程序的公共资源安全共享 .互斥量比临界区复杂
2. 互斥量(Mutex),信号灯(Semaphore),事件(Event)都可以被跨越进程使用来进行同步数据操作,而其他的对象与数据同步操作无关,但对于进程和线程来讲,如果进程和线程在运行状态则为无信号状态,在退出后为有信号状态。所以可以使用WaitForSingleObject来等待进程和线程退出。五 详解公钥、私钥、数字证书的概念
加密和认证
首先我们需要区分加密和认证这两个基本概念。加密是将数据资料加密,使得非法用户即使取得加密过的资料,也无法获取正确的资料内容,所以数据加密可以保护数据,防止监听攻击。 其重点在于数据的安全性。身份认证是用来判断某个身份的真实性,确认身份后,系统才可以依不同的身份给予不同的权限。 其重点在于用户的真实性。两者的侧重点是不同的。
公钥和私钥
公钥和私钥就是俗称的不对称加密方式,是从以前的对称加密(使用用户名与密码)方式的提高。在现代密码体制中加密和解密是采用不同的密钥(公开密钥),也就是非对称密钥密码系统,每个通信方均需要两个密钥,即公钥和私钥,这两把密钥可以互为加解密。公钥是公开的,不需要保密,而私钥是由个人自己持有,并且必须妥善保管和注意保密。
公钥私钥的原则:
- 一个公钥对应一个私钥。
- 密钥对中,让大家都知道的是公钥,不告诉大家,只有自己知道的,是私钥。
- 如果用其中一个密钥加密数据,则只有对应的那个密钥才可以解密。
- 如果用其中一个密钥可以进行解密数据,则该数据必然是对应的那个密钥进行的加密。
用电子邮件的方式说明一下原理。
使用公钥与私钥的目的就是实现安全的电子邮件,必须实现如下目的:
1. 我发送给你的内容必须加密,在邮件的传输过程中不能被别人看到。
2. 必须保证是我发送的邮件,不是别人冒充我的。
要达到这样的目标必须发送邮件的两人都有公钥和私钥。
公钥,就是给大家用的,你可以通过电子邮件发布,可以通过网站让别人下载,公钥其实是用来加密/验章用的。私钥,就是自己的,必须非常小心保存,最好加上 密码,私钥是用来解密/签章,首先就Key的所有权来说,私钥只有个人拥有。公钥与私钥的作用是:用公钥加密的内容只能用私钥解密,用私钥加密的内容只能 用公钥解密。
比如说,我要给你发送一个加密的邮件。首先,我必须拥有你的公钥,你也必须拥有我的公钥。
首先,我用你的公钥给这个邮件加密,这样就保证这个邮件不被别人看到,而且保证这个邮件在传送过程中没有被修改。你收到邮件后,用你的私钥就可以解密,就能看到内容。
其次我用我的私钥给这个邮件加密,发送到你手里后,你可以用我的公钥解密。因为私钥只有我手里有,这样就保证了这个邮件是我发送的。
非对称密钥密码的主要应用就是公钥加密和公钥认证,而公钥加密的过程和公钥认证的过程是不一样的,下面我就详细讲解一下两者的区别。
基于公开密钥的加密过程
比如有两个用户Alice和Bob,Alice想把一段明文通过双钥加密的技术发送给Bob,Bob有一对公钥和私钥,那么加密解密的过程如下:
- Bob将他的公开密钥传送给Alice。
- Alice用Bob的公开密钥加密她的消息,然后传送给Bob。
- Bob用他的私人密钥解密Alice的消息。
Alice使用Bob的公钥进行加密,Bob用自己的私钥进行解密。
基于公开密钥的认证过程
身份认证和加密就不同了,主要用户鉴别用户的真伪。这里我们只要能够鉴别一个用户的私钥是正确的,就可以鉴别这个用户的真伪。
还是Alice和Bob这两个用户,Alice想让Bob知道自己是真实的Alice,而不是假冒的,因此Alice只要使用私钥密码学对文件签名发送给Bob,Bob使用Alice的公钥对文件进行解密,如果可以解密成功,则证明Alice的私钥是正确的,因而就完成了对Alice的身份鉴别。整个身份认证的过程如下:
- Alice用她的私人密钥对文件加密,从而对文件签名。
- Alice将签名的文件传送给Bob。
- Bob用Alice的公钥解密文件,从而验证签名。
Alice使用自己的私钥加密,Bob用Alice的公钥进行解密。
根证书
根证书是CA认证中心给自己颁发的证书,是信任链的起始点。安装根证书意味着对这个CA认证中心的信任。
总结
根据非对称密码学的原理,每个证书持有人都有一对公钥和私钥,这两把密钥可以互为加解密。公钥是公开的,不需要保密,而私钥是由证书持人自己持有,并且必须妥善保管和注意保密。
数字证书则是由证书认证机构(CA)对证书申请者真实身份验证之后,用CA的根证书对申请人的一些基本信息以及申请人的公钥进行签名(相当于加盖发证书机构的公章)后形成的一个数字文件。CA完成签发证书后,会将证书发布在CA的证书库(目录服务器)中,任何人都可以查询和下载,因此数字证书和公钥一样是公开的。
可以这样说,数字证书就是经过CA认证过的公钥,而私钥一般情况都是由证书持有者在自己本地生成的,由证书持有者自己负责保管。具体使用时,签名操作是发送方用私钥进行签名,接受方用发送方证书来验证签名;加密操作则是用接受方的证书进行加密,接受方用自己的私钥进行解密。
参考:
http://blog.csdn.net/willfcareer/article/details/6219544
http://pepa.javaeye.com/blog/250991
http://blog.csdn.net/wangzhicheng2013/article/details/7832237
http://my.oschina.net/xiangxw/blog/11288