Solr云(SolrCloud)
SolrCloud只是作为Solr的一个突出特性,这个特殊的特性能够实现分布式功能。利用这个功能,你能建立高效、容错的Solr服务器群。这对于访问量规模巨大的企业级应用来说,使用SolrCloud能实现高有效性、容错性、分布式索引和搜索功能。
1 了解SolrCloud
千呼万唤,始出来。期待已久,Solr4.1的版本终于发布了。Solr4包含的突出特性SolrCloud, 真的让人眼前一亮。下面,让就来探究一下SolrCloud。
1.1 了解SolrCores 与集合(Collections)
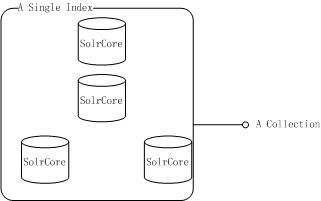
在一个简单的实例中,Solr有一些东西被称作一个SolrCore,其本质上视由于它就是一个单一的索引(Singlle Index)。当你想要多个索引(multiple indexes),你就不等不创建多个SolrCores。使用SolrCloud,一个简单的索引能够跨越多个Solr索引实例。我们称所有这些在逻辑上的索引(Index)的SolrCores为一个集合( A Collection),而一个集合( a collection)本质上是一个单一的索引,区别在于它能够跨越多个SolrCore‘s(Solr实例),而二者都是针对索引的缩放比例,也包括索引的冗余。比如说,你想将4个SolrCore的Solr移动到SolrCloud上去,你将会有4个集合(4 collections),而每一个集合是由多个独特的SolrCores组成。这就意味着,一个单一的索引(Single Index)能够由在不同机器上的多个SolrCores组成。
1.2 准备工作
下载最新的Solr稳定版本包(最新的是Solr 4.1,下载地址http://lucene.apache.org/solr/downloads.html)。为了便于演示,笔者采用实用cygwin (更多的信息,请参考http://cygwin.com/ )工具来执行脚本命令。
2 熟悉Solr Cloud
如果你对Solr还不太熟悉,建议先到Solr官网上查看一下具体的简单介绍(Simple Tutorial)。在对于Solr有一定了解后,删除Sample目录下的你测试产生的相关数据。这样能避免产生意外的错误,保证Demo能顺利进行。
对于分布式配置和协调,Solr嵌入和使用了Zookeeper(更详细的信息,请参考文档http://zookeeper.apache.org/)作为一个仓库--考虑到Zookepper能够包含所有Solr服务器的信息的分布式文件系统。
2.1 简单两个片集群(ShardCluster)
这个例子简单地创建了由两个Solr服务器组成的集群,Solr服务器实现了一个集合(A Collection)的两个不同片(shard).下面,展示了有关的实现步骤。
需要两台Solr服务器,可以复制一下已有example(下载的Solr4.2包,可以查看到这个目录)。进入解压后的目录后,在cygwin窗口执行命令。
cp -r example example01
下面这个命令将会启动Solr服务器以及启动一个新的Solr集群。
java -Djetty.port=8800 -Dbootstrap_confdir=./solr/collection1/conf
-Dcollection.configName=myconf-DzkRun -DnumShards=2 -jar start.jar
· -DzkRun 触发嵌入在Solr服务器中的Zookeeper运行。
· -Dbootstrap_confdir=./solr/collection1/conf 既然我们还没在Zookeeper中进行配置,这个参数引起本地的配置目录./solr/上传并且作为“myconfig”配置。这个名字“myconfig”是来自"collection.configName"得参数值。
· -Dcollection.configName=myconf setsthe config to use for the new collection. Omitting this param will cause theconfig name to default to "configuration1". 设置新的集合(Collection)的配置去使用,忽略这个配置将会引起配置名默认为"configuration1"。
· -DnumShards=2我们计划分离索引到几个逻辑分区,这个指定了对应数量。
· -Djetty.port=8800设置Jetty服务器运行的端口,默认是8983。
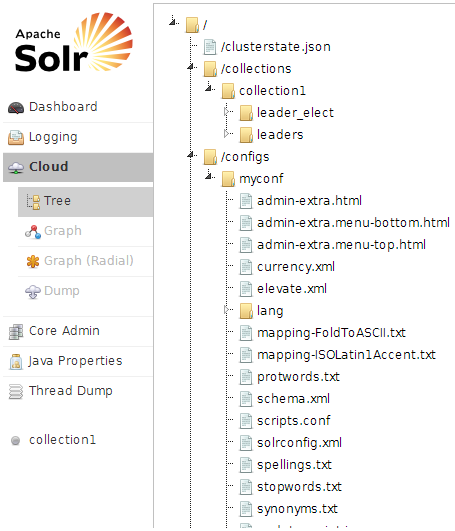
浏览http://localhost:8800/solr/#/~cloud?view=rgraph,可以看到集群的状态。点击Tree,会发现我们的配置文件目录已经上传上去了,对应的config目录也生产了。
现在,然我们启动第二个Solr服务器。它将会自动地赋给shard2,原因是我们没有具体指定这个shard id值。
java-Djetty.port=7800 -DzkHost=localhost:9983 -jar start.jar
当我们指定-DzkHost=localhost:9800,是更具shard的Zookeeper的值来指定的。在没
有指定Zookeeper端口的情况,嵌入在Solr中的Zookeeper默认为Sorl端口+1000,所以这里的Zookeeper的端口应该是9800。
接下来,建立一些索引文件。为了匆忙地完成,我们才采用 CloudSolrServer实现。
cd exampledocs
java-Durl=http://localhost:8800/solr/collection1/update -jar post.jar *.xml
在浏览器中输入:http://localhost:8800/solr/collection1/select?q=*:*&wt=xml,可以得到以下结果。

2.2 简单带有片重复(shard replicas)的两个片集群
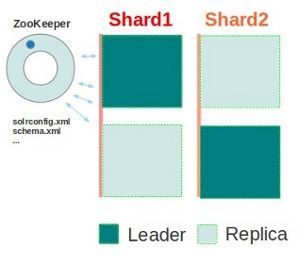
这个例子将会通过复制shard1和shard2来构建先前的例子,额外的备份的shard被用做来实现高有效性和容错性,或是简单地提升分布式查询能力。
首先,保持先前的例子处于运行中。使用命令,复制这两个实例。
cp -r example01example01_replica
cp -r example02example02_replica
在每个彼此的窗口中开启这两个新的不同端口的服务器。
java -Djetty.port=8801-DzkHost=localhost:9800 -jar start.jar
java -Djetty.port=7801-DzkHost=localhost:9800 -jar start.jar
浏览Zookeeper窗口http://localhost:8800/solr/#/~cloud,发现有效shard上图所示。此刻,窗口的查询日子和有关节点信息如下图。

你可以尝试去关闭一个节点,看看查询是否失效。一旦一个服务器中断了,发送请求将会发送到剩余启动的服务器。这时,你会继续看到整个一样的结果。如果我们停掉某个几点的所有服务器,这个请求对于这些服务器将会得到503错误。在shards中,返回仅仅这些存在于有效剩余有效shards的文档,添加跟随的查询参数便可以生效。
shards.tolerant=true
SolrCloud使用的是实施细节的领导(Leader)和监督者。这意味着,一些nodes/replicas能够扮演特殊的角色。你没有必要担心是否这个失效的服务器是领导者还是分布式的监督者—如果你碰巧是他们中的一个失效,他们自动透明地选择新的领导者或者新的监督者来回复使用者以及能无缝地负责他们各自的工作。任何Solr实例都能提升作为他们对于角色之一。

(Note:从Word文档中复制过来的,可以有些排版不太美观,请谅解。)