Unicode 东亚字符
本文主要参考Unicode 6.2的文档ch12.pdf. 由于文档内容实在太多,仅摘出我理解的部分。
基本思想就是Unicode中的东亚字符有一个统一的名称:CJK规范。而CJK的字符集合就是汉语象形字符集合,在Unicode中,汉语象形字符集已经包括了中,日,韩,越南,彝族等语言,规范来源子多个已经存在的字符集,比如中国的GB2312,香港,台湾,日本等。
概述:
1.在Unicode标准中,东亚字体也被称为汉字。汉字从公元2000年前沿用至今。中国周围的文明,经常对汉字进行修改用来书写他们自己的语言。日本,韩国和越南都借鉴并修改了汉字。2.在日本,除了仍在使用汉字外,还增加了平甲名和片甲名。
3.在朝鲜,一开始也是使用汉字,后来发明了韩文。现在是同时使用汉字和韩文。
4.在越南,用汉字的规则创造了一些本地文字。这些文字在20世纪初开始使用,也偶尔用于标志和有限的上下文环境中。
5.彝族一开始模仿汉字发明了一些文字。现代彝族语言是从这个基础上派生出来的。
6.中文也发明了汉语拼音,用来表示中文的发音。
7.上述东亚语言,都将字符书写在一个矩形内(通常是正方形)。汉字传统书写方向是至上而下,从右至左。受西方印刷技术的影响,现在多数是水平的,从左到右书写。很多老字符集包含了简化东亚语言的一些字符,比如标点符号的各种形式,半宽度和全宽度字符。Unicode规范包含了这些以兼容旧的标准。
汉语:
CJK统一文字
由于汉字使用的时候常常混合其他语言的字符,比如拉丁文和其他。如果包含早期的越南文字,名称用CJKV更合适。
英文中汉语表述为:"Han ideograph",字面上看ideograph指的是古老的象形文字,而汉语很大一部分后来发展出来的文字是通过组合,借鉴和其他非象形的方法得来的。但是英语中仍然使用了"Han ideograph"这个术语。汉语字符使用悠久,数量巨大,超过10,000。
CJK 规范描述了汉语字符在Unicode中的字符集合,而Unicode又把CJK字符集切分成了多个块(blocks)。
CJK规范
该规范由IRG制定。
Unicode从一些其他的字符集标准中获取并指定了自己的标准,一共有75,215个字符。它们被分成9个源(sources).
这样就可以解释U4E00.pdf文档中经常出现的G0, K0等。比如中文字符'一',

HEX值是4E00, 同时还显示了来源有多处:G0-523B, HB1-A440, T1-4421, J0-306C, K0-6069, V1-4A21,
G0 指的是GB-2312-80H指的是香港的字符集
其他都可以在ch12.pdf文档的第3和4页的表格Sources for Unified Han中找到。
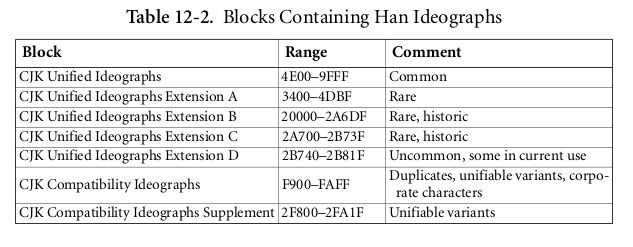
CJK的字符又被分成7个块中。每个块对应不同的取值范围。
最常用的块就是CJK Unified Ideographs ,取值范围是:4E00–9FFF