python正则表达式:re模块
正则表达式(regular expression)提供了一个简单灵活的方式来描述和识别符合规则的一组字符串,例如特殊的字符、单词或一组字符,在linux下常用的grep命令,就可以用来找出文件中符合规则的字符串。在python中,负责处理正则表达式的是re模块。
正则表达式包含了普通字符和特殊含义字符。如‘A’、‘a’、‘0’等普通字符,这些可以简单的匹配自身,另外是一些含义强大的特殊字符,如‘.’匹配任何一个字符(换行符除外),‘*’匹配前面出现的正则表达式零次或多次,这和在windows下常用的通配符不是一个概念,两者有自己专有的规则。以下是常见的字符及其含义,更详细的字符介绍请参考http://en.wikipedia.org/wiki/Regular_expression。
匹配对象
group(num = 0)
返回全部匹配对象,或指定编号的子组。
groups()
返回包含全部匹配的子组的元组
常用函数
re.compile(pattern, flags=0)
将正则表达式编译成一个正则表达式编译对象,使用预编译代码对象要比执行字符串要快,提高程序效率。用法如下:
prog = re.compile( pattern )
result = prog.match( string )
等价于:
result = re.mtach(pattern, string)

re.match(pattern, string, flags=0)
从字符串的开始进行模式的匹配,成功则返回匹配对象,失败则返回为空。
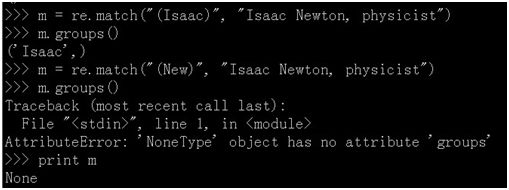
re.search(pattern, string, flags=0)
检查字符串中任意位置,成功则返回匹配对象,失败则返回为空。

注意问题
在进行正则表达式匹配的时候,默认是贪心匹配,即尽可能的得到满足匹配的最长字符串,可以通过操作符“?”实现非贪婪的匹配模式,即将*、+和?变为*?、+?和??。
如下所示,当不加?时,匹配结果为整个字符串,当加入?后,匹配结果为第一个小括号的内容。
refer
http://en.wikipedia.org/wiki/Regular_expression
http://docs.python.org/library/re.html