NETDEV 协议 五
ip_rcv进入IP层报文接收函数
丢弃掉不是发往本机的报文,skb->pkt_type在网卡接收报文处理以太网头时会根据dst mac设置,协议栈的书会讲不是发往本机的广播报文会在二层被丢弃,实际上丢弃是发生在进入上层之初。
在取IP报头时要注意可能带有选项,因此报文长度应当以iph->ihl * 4为准。这里就需要尝试两次,第一次尝试sizeof(struct iphdr),只是为了确保skb还可以容纳标准的报头(即20字节),然后可以ip_hdr(skb)得到报头;第二次尝试ihl * 4,这才是报文的真正长度,然后重新调用ip_hdr(skb)来得到报头。两次尝试pull后要重新调用ip_hdr()的原因是pskb_may_pull()可能会调用__pskb_pull_tail()来改现现有的skb结构。
if (!pskb_may_pull(skb, sizeof(struct iphdr))) goto inhdr_error; iph = ip_hdr(skb); …… if (!pskb_may_pull(skb, iph->ihl*4)) goto inhdr_error; iph = ip_hdr(skb);
获取到IP报头后经过一些检查,获取到报文的总长度len = iph->tot_len,此时调用pskb_trim_rcsum()去除多余的字节,即大于len的。
然后调用ip_rcv_finish()继续IP层的处理,ip_rcv()可以看成是查找路由前的IP层处理,接下来的ip_rcv_finish()会查找路由表,两者间调用插入的netfilter
进入ip_rcv_finish函数
ip_rcv_finish()主要工作是完成路由表的查询,决定报文经过IP层处理后,是继续向上传递,还是进行转发,还是丢弃。
刚开始没有进行路由表查询,所以还没有相应的路由表项:skb_dst(skb) == NULL。则在路由表中查找ip_route_input(),
if (skb_dst(skb) == NULL) {
int err = ip_route_input(skb, iph->daddr, iph->saddr, iph->tos,
skb->dev);
if (unlikely(err)) {
if (err == -EHOSTUNREACH)
IP_INC_STATS_BH(dev_net(skb->dev),
IPSTATS_MIB_INADDRERRORS);
else if (err == -ENETUNREACH)
IP_INC_STATS_BH(dev_net(skb->dev),
IPSTATS_MIB_INNOROUTES);
goto drop;
}
}
通过路由表查找,我们知道:
- 如果是丢弃的报文,则直接drop;
- 如果是不能接收或转发的报文,则input = ip_error
- 如果是发往本机报文,则input = ip_local_deliver;
- 如果是广播报文,则input = ip_local_deliver;
- 如果是组播报文,则input = ip_local_deliver;
- 如果是转发的报文,则input = ip_forward;
在ip_rcv_finish()最后,会调用查找到的路由项_skb_dst->input()继续向上传递:
具体看下各种情况下的报文传递,如果是丢弃的报文,则报文被释放,并从IP协议层返回,完成此次报文传递流程。
drop: kfree_skb(skb); return NET_RX_DROP;
如果是不能处理的报文,则执行ip_error,根据error类型发送相应的ICMP错误报文。
如果是主机可以接收报文,则执行ip_local_deliver。ip_local_deliver在向上传递前,会对分片的IP报文进行组包,因为IP层协议会对过大的数据包分片,在接收时,就要进行重组,而重组的操作就是在这里进行的。IP报头的16位偏移字段frag_off是由3位的标志(CE,DF,MF)和13的偏移量组成。如果收到了分片的IP报文,如果是最后一片,则MF=0且offset!=0;如果不是最后一片,则MF=1。
在这种情况下会执行ip_defrag来处理分片的IP报文,如果不是最后一片,则将该报文添加到ip4_frags中保留下来,并return 0,此次数据包接收完成;如果是最后一片,则取出之前收到的分片重组成新的skb,此时ip_defrag返回值为0,skb被重置为完整的数据包,然后继续处理,之后调用ip_local_deliver_finish处理重组后的数据包。
下面来看下ip_defrag()函数,主体就是下面的代码段。它首先用ip_find()查找IP分片,并返回(如果没有则创建),然后用ip_frag_queue()将新分片加入,关于IP分片的处理,在后面的IP分片中有详细描述。
然后会调用ip_local_deliver_finish()完成IP协议层的传递,两者调用间依然有netfilter,这是查找完路由表继续向上传递的中间点。
在ip_local_deliver_finish()中会完成IP协议层处理,再交由上层协议模块处理:ICMP、IGMP、UDP、TCP。在ip_local_deliver_finish函数中,由于IP报头已经处理完,剔除IP报头,并设置skb->transport_header指向传输层协议报头位置。
__skb_pull(skb, ip_hdrlen(skb)); skb_reset_transport_header(skb);
protocol是IP报头中的的上层协议号,以它在inet_protos哈希表中查找处理protocol的协议模块,取出得到ipprot。
而关于inet_protos,它的数据结构是哈希表,用来存储IP层上的协议,包括传输层协议和3.5层协议,它在IP协议模块加载时被添加。
然后通过调用handler交由上层协议处理,至此,IP层协议处理完成。
ret = ipprot->handler(skb);
IP分片
在收到IP分片时,会暂时存储到一个哈希表ip4_frags中,它在IP协议模块加载时初始化,inet_init() -> ipfrag_init()。要留意的是ip4_frag_match用于匹配IP分片是否属于同一个报文;ip_expire用于在IP分片超时时进行处理。
当收到一个IP分片,首先用ip_find()查找IP分片,实际上就是从ip4_frag表中取出相应项。这里的哈希值是由IP报头的(标识,源IP,目的IP,协议号)得到的。
inet_frag_find实现直正的查找
根据hash值取得ip4_frag->hash[hash]项 – inet_frag_queue,它是一个队列,然后遍历该队列,当net, id, saddr, daddr, protocol, user相匹配时,就是要找的IP分片。如果没有匹配的,则调用inet_frag_create创建它。
inet_frag_create创建一个IP分片队列ipq,并插入相应队列中。
首先分配空间,真正分配空间的是inet_frag_alloc中的q = kzalloc(f->qsize, GFP_ATOMIC);其中f->qsize = sizeof(struct ipq),也就是说分配了ipq大小空间,但返回的却是struct inet_frag_queue q结构,原因在于inet_frag_queue是ipq的首个属性,它们两者的联系如下图。

在分配并初始化空间后,由inet_frag_intern完成插入动作,首先还是根据(标识,源IP,目的IP,协议号)先成hash值,这里的qp_in即之前的q。
然后新创建的队列qp(即上面的qp_in)插入到hash表(即ip4_frags->hash)和net->ipv4.frags中,并增加队列qp的引用计数,net中的队列nqueues统计数。至此,IP分片的创建过程完成。
ip_frag_queue实现将IP分片加入队列中
首先获取该IP分片偏移位置offset,和IP分片偏移结束位置end,其中skb->len – ihl表示IP分片的报文长度,三者间关系即为end = offset + skb->len – ihl。
如果该IP分片是最后一片(MF=0,offset!=0),即设置q.last_iin |= INET_FRAG_LAST_IN,表示收到了最后一个分片,qp->q.len = end,此时q.len是整个IP报文的总长度。
如果该IP分片不是最后一片(MF=1),当end不是8字节倍数时,通过end &= ~7处理为8字节整数倍(但此时会忽略掉多出的字节,如end=14 => end=8);然后如果该分片更靠后,则q.len = end。
查找q.fragments链表,找到该IP分片要插入的位置,这里的q.fragments就是struct sk_buff类型,即各个IP分片skb都会插入到该链表中,插入的位置按偏移顺序由小到大排列,prev表示插入的前一个IP分片,next表示插入的后一个IP分片。
然后将skb插入到链表中,要注意fragments为空和不为空的情形,在下图中给出。
skb->next = next; if (prev) prev->next = skb; else qp->q.fragments = skb;

增加q.meat计数,表示已收到的IP分片的总长度;如果offset为0,则表明是第一个IP分片,设置q.last_in |= INET_FRAG_FIRST_IN。
最后当满足一定条件时,进行IP重组。当收到了第一个和最后一个IP分片,且收到的IP分片的最大长度等于收到的IP分片的总长度时,表明所有的IP分片已收集齐,调用ip_frag_reasm重组包。具体的,当收到第一个分片(offset=0且MF=1)时设置q.last_in |= INET_FRAG_FIRST_IN;当收到最后一个分片(offset != 0且MF=0)时设置q.last_in |= INET_FRAG_LAST_IN。meat和len的区别在于,IP是不可靠传输,到达的IP分片不能保证顺序,而meat表示到达IP分片的总长度,len表示到达的IP分片中偏移最大的长度。所以当满足上述条件时,IP分片一定是收集齐了的。
以下图为例,原始IP报文分成了4片发送,假设收到了1, 3, 4分片,则此时q.last_in = INET_FRGA_FIRST_IN | INET_FRAG_LAST_IN,q.meat = 30,q.len = 50。表明还未收齐IP分片,等待IP分片2的到来。

这里还有一些特殊情况需要处理,它们可能是重新分片或传输时错误造成的,那就是IP分片互相间有重叠。为了避免这种情况发生,在插入IP分片前会处理掉这些重叠。
第一种重叠是与前个分片重叠,即该分片的的偏移是从前个分片的范围内开始的,这种情况下i表示重叠部分的大小,offset+=i则将该分片偏移后移i个长度,从而与前个分片隔开,而且减少len,pskb_pull(skb, i),见下图图示。

第二种重叠是与后个分片重叠,即该分片的的结束位置在后个分片的范围内,这种情况下i表示重叠部分的大小。后片重叠稍微复杂点,被i重叠的部分都要删除掉,如果i比较大,超过了分片长度,则整个分片都被覆盖,从q.fragments链表中删除。使用while处理i覆盖多个分片的情况。
当整个分片被覆盖掉,从q.fragments中删除,并且由于减少了分片总长度,所以q.meat要减去删除分片的长度。
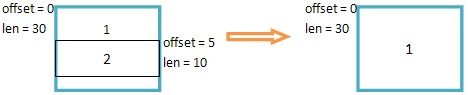
当只覆盖分片一部分时,offset+=i则将后个分片偏移后移i个长度,从而与该分片隔开,同时这样相当于减少了IP分片的长度,所以q.meat -= i;见下图图示,

ip_frag_reasm函数实现IP分片的重组
ip_frag_reasm传入的参数是prev,而重组完成后ip_defrag会将skb替换成重组后的新的skb,而在之前的操作中,skb插入了qp->q.fragments中,并且prev->next即为skb,因此第一步就是让skb变成qp->q.fragments,即IP分片的头部。
下面图示说明了上面代码段作用,skb是IP分片3,通过skb_clone拷贝一份3_copy替代之前的分片3,再通过skb_morph拷贝q.fragments到原始IP分片3,替代分片1,并释放分片1:

获取IP报头长度ihlen,head就是ip_defrag传入参数中的skb,并且它已经成为了IP分片队列的头部;len为整个IP报头+报文的总长度,qp->q.len是未分片前IP报文的长度。
此时head就是skb,并且它的skb->data存储了第一个IP分片的内容,其它IP分片的内容将存储在紧接skb的空间 – frag_list;skb_push将skb->data回归原位,即未处理IP报头前的位置,因为之前的IP分片处理会调用skb_pull移走IP报头,将它回归原位是因为skb即将作为重组后的报文而被处理,那里会真正的skb_pull移走IP报头,再交由上层协议处理。
上面所说的frag_list是struct skb_shared_info的一个属性,在分配skb时分配在其后空间,通过skb_shinfo(skb)进行引用。下面分配skb大小size和skb_shared_info大小的代码摘自[net/core/skbuff.c]
这里要弄清楚sk_buff中线性存储区和paged buffer的区别,线性存储区就是存储报文,如果是分片后的,则只是第一个分片的内容;而paged buffer则存储其余分片的内容。而skb->data_len则表示paged buffer中内容长度,而skb->len则是paged buffer + linear buffer。下面这段代码就是根据余下的分片增加data_len和len计数。
for (fp=head->next; fp; fp = fp->next) {
head->data_len += fp->len;
head->len += fp->len;
……
}
IP分片已经重组完成,分片从q.fragments链表移到了frag_list上,因此head->next和qp->q.fragments置为NULL。偏移量frag_off置0,总长度tot_len置为所有分片的长度和,这样,skb就相当于没有分片的完整的大数据包,继续向上传递。
head->next = NULL; head->dev = dev; …… iph = ip_hdr(head); iph->frag_off = 0; iph->tot_len = htons(len); IP_INC_STATS_BH(net, IPSTATS_MIB_REASMOKS); qp->q.fragments = NULL;
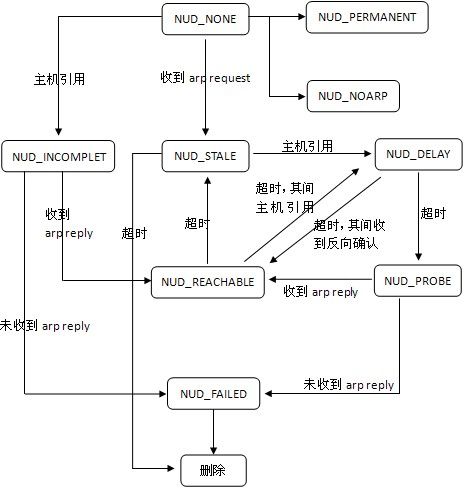
这部分的重点是三个核心的数据结构-邻居表、邻居缓存、代理邻居表,以及NUD状态转移图。
总的来说,要成功添加一条邻居表项,需要满足两个条件:1. 本机使用该表项;2. 对方主机进行了确认。同时,表项的添加引入了NUD(Neighbour Unreachability Detection)机制,从创建NUD_NONE到可用NUD_REACHABLE需要经历一系列状态转移,而根据达到两个条件顺序的不同,可以分为两条路线:
先引用再确认- NUD_NONE -> NUD_INCOMPLETE -> NUD_REACHABLE
先确认再引用- NUD_NONE -> NUD_STALE -> NUD_DELAY -> NUD_PROBE -> NUD_REACHABLE
下面还是从接收函数入手,当匹配号协议号是0x0806,会调用ARP模块的接收函数arp_rcv()。
arp_rcv() ARP接收函数
首先是对arp协议头进行检查,比如大小是否足够,头部各数值是否正确等,这里略过代码,直接向下看。每个协议处理都一样,如果被多个协议占有,则拷贝一份。
NEIGH_CB(skb)实际就是skb->cb,在skb声明为u8 char[48],它用作每个协议模块的私有数据区(control buffer),每个协议模块可以根据自身需求在其中存储私有数据。而arp模块就利用了它存储控制结构neighbour_cb,它声明如下,占8字节。这个控制结构在代理ARP中使用工作队列时会发挥作用,sched_next代表下次被调度的时间,flags是标志。
函数最后调用arp_process,其间插入netfilter作为开始处理ARP报文的起点。
arp_process()
这个函数开始对报文进行处理,首先会从skb中取出arp报头部分的信息,如sha, sip, tha, tip等,这部分可查阅代码,这里略过。ARP不会查询环路地址和组播地址,因为它们没有对应的mac地址,因此遇到这两类地址,直接退出。
如果收到的是重复地址检测报文,并且本机占用了检测了地址,则调用arp_send发送响应。对于重复地址检测报文(ARP报文中源IP为全0),它所带有的邻居表项信息还没通过检测,此时缓存它显然没有意义,也许下一刻就有其它主机声明它非法,因此,重复地址检测报文中的信息不会加入邻居表中。
下面要处理的地址解析报文,并且要解析的地址在路由表中存在
第一种情况,如果要解析的是本机地址,则调用neigh_event_ns(),并根据查到的邻居表项n发送ARP响应报文。这里neigh_event_ns的功能是在arp_tbl中查找是否已含有对方主机的地址信息,如果没有,则进行创建,然后会调用neigh_update来更新状态。收到对方主机的请求报文,会导致状态迁移到NUD_STALE。
#NUD_INCOMPLETE也迁移到NUD_STALE,作何解释?
第二种情况,如果要解析的不是本机地址,则要判断是否支持转发,是否支持代理ARP(代理ARP是陆由器的功能,因此能转发是先决条件),如果满足条件,那么按照代理ARP流程处理。首先无论如何,主机得通了存在这样一个邻居,因此要在在arp_tbl中查找并(如果不存在)创建相应邻居表项;然后,对于代理ARP,这个流程实际上会执行两遍,第一遍走else部分,第二遍走if部分。第一次的else代码段会触发定时器,通过定时器引发报文重新执行arp_process函数,并走if部分。
-第一遍的else部分:调用pneigh_enqueue()将报文skb加入tbl->proxy_queue队列,同时设置NEIGH_CB(skb)的值,具体可看后见的代理表项处理。
-第二遍的if部分,发送ARP响应报文,行使代理ARP的功能。
补充:neigh_event_ns()与neigh_release()配套使用并不代表创建后又被释放,neigh被释放的条件是neigh->refcnt==0,但neigh创建时的refcnt=1,而neigh_event_ns会使refcnt+1,neigh_release会使-1,此时refcnt的值还是1,只有当下次单独调用neigh_release时才会被释放。
查找是否已存在这样一个邻居表项。如果ARP报文是发往本机的响应报文,那么neigh会更新为NUD_REACHABLE状态;否则,维持原状态不变。#个人认为,这段代码是处理NUD_INCOMPLETE/NUD_PROBE/NUD_DELAY向NUD_REACHABLE迁移的,但如果一台主机A发送一个对本机的ARP响应报文,那么会导致neigh从NUD_NONE直接迁移到NUD_REACHABLE,当然,按照正常流程,一个ARP响应报文肯定是由于本机发送了ARP请求报文,那样neigh已经处于NUD_INCOMPLETE状态了。
实际上,arp_process是接收到ARP报文的处理函数,它涉及到的是邻居表项在收到arp请求和响应的情况,下图反映了arp_process中所涉及的状态转移:收到arp请求,NUD_NONE -> NUD_STALE;收到arp响应,NUD_INCOMPLETE/NUD_DELAY/NUD_PROBE -> NUD_REACHABLE。根据之前分析,我认为还存在NUD_NONE -> NUD_REACHABLE和NUD_INCOMPLETE -> NUD_STALE的转移,作何解释?

NUD状态
每个邻居表项在生效前都要经历一系列的状态迁移,每个状态都有不同的含义,在前面已经多次提到了NUD状态。要添加一条有效的邻居表项,有效途径有两条:
先引用再确认- NUD_NONE -> NUD_INCOMPLETE -> NUD_REACHABLE
先确认再引用- NUD_NONE -> NUD_STALE -> NUD_DELAY -> NUD_PROBE -> NUD_REACHABLE
其中neigh_timer_handler定时器、neigh_periodic_work工作队列会异步的更改NUD状态,neigh_timer_handler用于NUD_INCOMPLETE, NUD_DELAY, NUD_PROBE, NUD_REACHABLE状态;neigh_periodic_work用于NUD_STALE。注意neigh_timer_handler是每个表项一个的,而neigh_periodic_work是唯一的,NUD_STALE状态的表项没必要单独使用定时器,定期检查过期就可以了,这样大大节省了资源。
neigh_update则专门用于更新表项状态,neigh_send_event则是解析表项时的状态更新,能更新表项的函数很多,这里不一一列出。
neigh_timer_handler 定时器函数
当neigh处于NUD_INCOMPLETE, NUD_DELAY, NUD_PEOBE, NUD_REACHABLE时会添加定时器,即neigh_timer_handler,它处理各个状态在定时器到期时的情况。
当neigh处于NUD_REACHABLE状态时,根据NUD的状态转移图,它有三种转移可能,分别对应下面三个条件语句。neigh->confirmed代表最近收到来自对应邻居项的报文时间,neigh->used代表最近使用该邻居项的时间。
-如果超时,但期间收到对方的报文,不更改状态,并重置超时时间为neigh->confirmed+reachable_time;
-如果超时,期间未收到对方报文,但主机使用过该项,则迁移至NUD_DELAY状态,并重置超时时间为neigh->used+delay_probe_time;
-如果超时,且既未收到对方报文,也未使用过该项,则怀疑该项可能不可用了,迁移至NUD_STALE状态,而不是立即删除,neigh_periodic_work()会定时的清除NUD_STALE状态的表项。
下图是对上面表项处于NUD_REACHABLE状态时,定时器到期后3种情形的示意图:

当neigh处于NUD_DELAY状态时,根据NUD的状态转移图,它有二种转移可能,分别对应下面二个条件语句。
-如果超时,期间收到对方报文,迁移至NUD_REACHABLE,记录下次检查时间到next;
-如果超时,期间未收到对方的报文,迁移至NUD_PROBE,记录下次检查时间到next。
在NUD_STALE->NUD_PROBE中间还插入NUD_DELAY状态,是为了减少ARP包的数目,期望在定时时间内会收到对方的确认报文,而不必再进行地址解析。
当neigh处于NUD_PROBE或NUD_INCOMPLETE状态时,记录下次检查时间到next,因为这两种状态需要发送ARP解析报文,它们过程的迁移依赖于ARP解析的进程。
经过定时器超时后的状态转移,如果neigh处于NUD_PROBE或NUD_INCOMPLETE,则会发送ARP报文,先会检查报文发送的次数,如果超过了限度,表明对方主机没有回应,则neigh进入NUD_FAILED,被释放掉。
if ((neigh->nud_state & (NUD_INCOMPLETE | NUD_PROBE)) &&
atomic_read(&neigh->probes) >= neigh_max_probes(neigh)) {
neigh->nud_state = NUD_FAILED;
notify = 1;
neigh_invalidate(neigh);
}
检查完后,如果还未超过限度,则会发送ARP报文,neigh->ops->solicit在创建表项neigh时被赋值,一般是arp_solicit,并且增加探测计算neigh->probes。
实际上,neigh_timer_handler处理启用了定时器状态超时的情况,下图反映了neigh_timer_handler中所涉及的状态转移,值得注意的是NUD_DELAY -> NUD_REACHABLE的状态转移,在arp_process中也提到过,收到arp reply时会有表项状态NUD_DELAY -> NUD_REACHABLE。它们两者的区别在于arp_process处理的是arp的确认报文,而neigh_timer_handler处理的是4层的确认报文。

neigh_periodic_work NUD_STALE状态的定时函数
当neigh处于NUD_STALE状态时,此时它等待一段时间,主机引用到它,从而转入NUD_DELAY状态;没有引用,则转入NUD_FAIL,被释放。不同于NUD_INCOMPLETE、NUD_DELAY、NUD_PROBE、NUD_REACHABLE状态时的定时器,这里使用的异步机制,通过定期触发neigh_periodic_work()来检查NUD_STALE状态。
当初始化邻居表时,添加了neigh_periodic_work工作
neigh_table_init() -> neigh_table_init_no_netlink():
当neigh_periodic_work执行时,首先计算到达时间(reachable_time),其中要注意的是
因此,reachable_time实际取值是1/2 base ~ 2/3 base,而base = base_reachable_time,当表项处于NUD_REACHABLE状态时,会启动一个定时器,时长为reachable_time,即一个表项在不被使用时存活时间是1/2 base_reachable_time ~ 2/3 base_reachable_time。
然后它会遍历整个邻居表,每个hash_buckets的每个表项,如果在gc_staletime内仍未被引用过,则会从邻居表中清除。
for (i = 0 ; i <= tbl->hash_mask; i++) {
np = &tbl->hash_buckets[i];
while ((n = *np) != NULL) {
…..
if (atomic_read(&n->refcnt) == 1 &&
(state == NUD_FAILED ||
time_after(jiffies, n->used + n->parms->gc_staletime))) {
*np = n->next;
n->dead = 1;
write_unlock(&n->lock);
neigh_cleanup_and_release(n);
continue;
}
……
}
在工作最后,再次添加该工作到队列中,并延时1/2 base_reachable_time开始执行,这样,完成了neigh_periodic_work工作每隔1/2 base_reachable_time执行一次。
schedule_delayed_work(&tbl->gc_work, tbl->parms.base_reachable_time >> 1);
neigh_periodic_work定期执行,但要保证表项不会刚添加就被neigh_periodic_work清理掉,这里的策略是:gc_staletime大于1/2 base_reachable_time。默认的,gc_staletime = 30,base_reachable_time = 30。也就是说,neigh_periodic_work会每15HZ执行一次,但表项在NUD_STALE的存活时间是30HZ,这样,保证了每项在最差情况下也有(30 - 15)HZ的生命周期。
neigh_update 邻居表项状态更新
如果新状态是非有效(!NUD_VALID),那么要做的就是删除该表项:停止定时器neigh_del_timer,设置neigh状态nud_state为新状态new。除此之外,当是NUD_INCOMPLETE或NUD_PROBE状态时,可能有暂时因为地址没有解析而暂存在neigh->arp_queue中的报文,而现在表项更新到NUD_FAILED,即解析无法成功,那么这么暂存的报文也只能被丢弃neigh_invalidate。
中间这段代码是对比表项的地址是否发生了变化,略过。#个人认为NUD_REACHABLE状态时,新状态为NUD_STALE是在下面这段代码里面除去了,因为NUD_REACHABLE状态更好,不应该回退到NUD_STALE状态。但是当是NUD_DELAY, NUD_PROBE, NUD_INCOMPLETE时仍会被更新到NUD_STALE状态,对此很不解???
新旧状态不同时,首先删除定时器,如果新状态需要定时器,则重新设置定时器,最后设置表项neigh为新状态new。
如果邻居表项中的地址发生了更新,有了新的地址值lladdr,那么更新表项地址neigh->ha,并更新与此表项相关的所有缓存表项neigh_update_hhs。
if (lladdr != neigh->ha) {
memcpy(&neigh->ha, lladdr, dev->addr_len);
neigh_update_hhs(neigh);
if (!(new & NUD_CONNECTED))
neigh->confirmed = jiffies -
(neigh->parms->base_reachable_time << 1);
notify = 1;
}
如果表项状态从非有效(!NUD_VALID)迁移到有效(NUD_VALID),且此表项上的arp_queue上有项,表明之前有报文因为地址无法解析在暂存在了arp_queue上。此时表项地址解析完成,变为有效状态,从arp_queue中取出所有待发送的报文skb,发送出去n1->output(skb),并清空表项的arp_queue。
neigh_event_send
当主机需要解析地址,会调用neigh_resolve_output,主机引用表项明显会涉及到表项的NUD状态迁移,NUD_NONE->NUD_INCOMPLETE,NUD_STALE->NUD_DELAY。
neigh_event_send -> __neigh_event_send
只处理nud_state在NUD_NONE, NUD_STALE, NUD_INCOMPLETE状态时的情况:
不处于NUD_STALE和NUD_INCOMPLETE状态,则只能是NUD_NONE。此时主机要用到该邻居表项(注意是通过neigh_resolve_output进入的),但还没有,因此要通过ARP进行解析,并且此时没有收到对方发来的任何报文,要进行的ARP是广播形式。
在发送ARP报文时有3个参数- ucast_probes, mcast_probes, app_probes,分别代表单播次数,广播次数,app_probes比较特殊,一般情况下为0,当使用了arpd守护进程时才会设置它的值。如果已经收到过对方的报文,即知道了对方的MAC-IP,ARP解析会使用单播形式,次数由ucast_probes决定;如果未收到过对方报文,此时ARP解析只能使用广播形式,次数由mcasat_probes决定。
当mcast_probes有值时,neigh进入NUD_INCOMPLETE状态,设置定时器,注意此时neigh_probes(表示已经进行探测的次数)初始化为ucast_probes,目的是只进行mcast_probes次广播;当mcast_probes值为0时(表明当前配置不允许解析),neigh进入NUD_FAILED状态,被清除。
当neigh处于NUD_STALE状态时,根据NUD的状态转移图,主机引用到了该邻居表项,neigh转移至NUD_DELAY状态,设置定时器。
当neigh处于NUD_INCOMPLETE状态时,需要发送ARP报文进行地址解析,__skb_queue_tail(&neigh->arp_queue, skb)的作用就是先把要发送的报文缓存起来,放到neigh->arp_queue链表中,当完成地址解析,再从neigh->arp_queue取出报文,并发送出去。
邻居表的操作
neigh_create 创建邻居表项
首先为新的邻居表项struct neighbour分配空间,并做一些初始化。传入的参数tbl就是全局量arp_tbl,分配空间的大小是tbl->entry_size,而这个值在声明arp_tbl时初始化为sizeof(struct neighbour) + 4,多出的4个字节就是key值存放的地方。
拷贝key(即IP地址)到primary_key,而primary_key就是紧接neighbour的4个字节,看下struct neighbor的声明 - u8 primary_key[0];设置n->dev指向接收到报文的网卡设备dev。
哈希表是牺牲空间换时间,保证均匀度很重要,一旦某个表项的值过多,链表查找会降低性能。因此当表项数目entries大于初始分配大小hash_mask+1时,执行neigh_hash_grow将哈希表空间倍增,这也是内核使用哈希表时常用的方法,可变大小的哈希表。
通过pkey和dev计算哈希值,决定插入tbl->hash_buckets的表项。
搜索tbl->hash_buckets[hash_val]项,如果创建的新ARP表项已存在,则退出;否则将其n插入该项的链表头。
附一张创建ARP表项并插入到hash_buckets的图:

neigh_lookup 查找ARP表项
查找函数很简单,以IP地址和网卡设备(即pkey和dev)计算哈希值hash_val,然后在tbl->hash_buckets查找相应项。
代理ARP
代理ARP的相关知识查阅google。要明确代理ARP功能是针对陆由器的(或者说是具有转发功能的主机)。开启ARP代理后,会对查询不在本网段的ARP请求包回应。
回到之前的arp_process代码,处理代理ARP的情况,这实际就是进行代理ARP的条件,IN_DEV_FORWARD是支持转发,RTN_UNICAST是与路由直连,arp_fwd_proxy表示设备支持代理行为,arp_fwd_pvlan表示支持代理同设备进出,pneigh_lookup表示目的地址的代理。这两种arp_fwd_proxy和arp_fwd_pvlan都只是网卡设备的一种性质,pneigh_lookup则是一张代理邻居表,它的内容都是手动添加或删除的,三种策略任一一种满足都可以进行代理ARP。
pneigh_lookup 查找或添加代理邻居表项[proxy neighbour]
以[pkey=tip, key_len=4]计算hash值,执行__pneigh_lookup_1在phash_buckets中查找。
如果在phash_buckets中查找到,或者不需要创建新表项,则函数返回,此时它的功能仅仅是lookup。
而当传入参数create=1时,则它的功能不仅是lookup,还会在表项不存在时create。同neighbour结构一样,键值pkey存储在pneigh结构的后面,这样当pkey变化时,修改十分容易。创建操作很直观,为pneigh和pkey分配空间,初始化些变量,最后插入phash_buckets。
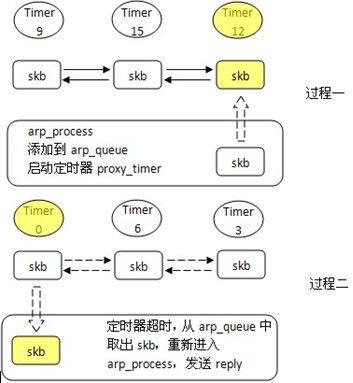
pneigh_enqueue 将报文加入代理队列
首先计算下次调度的时间,这是一个随机值,记录到sched_next中;设置flags|=LOCALLY_ENQUEUED表明报文是本地加入的。
然后将报文加入proxy_queue,并设置定时器proxy_timer,下次超时时间为刚计算的值sched_next,这样,下次超时时就会处理proxy_queue队列中的报文。
这里的tbl当然是arp_tbl,它的proxy_timer是在初始化时设置的arp_init() -> neigh_table_init_no_netlink()中:
neigh_proxy_process 代理ARP的定时器
skb_queue_walk_safe如同for循环一样,它遍历proxy_queue,一个个取出其中的报文skb,查看报文的调度时间sched_next与当前时间now的差值。
如果tdif<=0则表明调度时间已到或已过,报文要被处理了,从proxy_queue上取出该报文,调用tbl->proxy_redo重新发送报文,tbl->proxy_redo也是在arp初始化时赋值的,实际上就是arp_process()函数。结合上面的分析,它会执行arp_process中代理ARP处理的else部分,发送响应报文。
如果tdif>0则表明调度时间还未到,else if部分的功能就是记录下最近要过期的调度时间到sched_next。
重新设置proxy_timer的定时器,下次超时时间为刚刚记录下的最近要调度的时间sched_next + 当前时间jiffies。
以一张简单的图来说明ARP代理的处理过程,过程一是入队列等待,过程二是出队列发送。不立即处理ARP代理请求报文的原因是为了性能,收到报文后会启动定时器,超时时间是一个随机变量,保证了在大量主机同时进行此类请求时不会形成太大的负担。
邻居表缓存
邻居表缓存中存储的就是二层报头,如果缓存的报头正好被用到,那么直接从邻居表缓存中取出报文就行了,而不用再额外的构造报头,加快了协议栈的响应速度。
neigh_hh_init 创建新的邻居表缓存
当发送报文时,如果还没有对方主机MAC地址,则调用neigh_resove_output进行地址解析,此时会判断dst->hh为NULL时,就会调用neigh_hh_init创建邻居表缓存,加速下次的报文发送。
首先在邻居表项所链的所有邻居表缓存项n->hh匹配协议号protocol,找到,则说明已有缓存,不必再创建,neigh_hh_init会直接返回;未找到,则会创建新的缓存项hh。
下面代码段创建了新的缓存项hh,并初始化了hh的内容,其中dev->header_ops->cache会赋值hh->hh_data,即[SRCMAC, DSTMAC, TYPE]。如果赋值失败,释放掉刚才分配的hh;如果赋值成功,将hh链入n->hh的链表,并根据NUD状态赋值hh->hh_output。
最后,创建成功的hh,陆由缓存dst->hh指向新创建的hh。
从hh的创建过程可以看出,通过邻居表项neighbour的缓存hh可以遍历所有的与neighbour相关的缓存(即目的MAC相同,但协议不同);通过dst的缓存hh只能指向相关的一个缓存(尽管dst->hh->hh_next也许有值,但只会使用dst->hh)。
这里解释了为什么neighbour和dst都有hh指针指向缓存项,可以这么说,neighbour指向的hh是全部的,dst指向的hh是特定一个。两者的作用:在发送报文时查找完陆由表找到dst后,会直接用dst->hh,得到以太网头;而当远程主机MAC地址变更时,通过dst->neighbour->hh可以遍历所有缓存项,从而全部更改,而用dst->hh得一个个查找,几乎是无法完成的。可以这么说,dst->hh是使用时用的,neigh->hh是管理时用的。

neigh_update_hhs 更新缓存项
更新缓存项更新的实际就是缓存项的MAC地址。比如当收到一个报文,以它源IP为键值在邻居表中查找到的neighbour表项的n->ha与报文源MAC值不同时,说明对方主机的MAC地址发生了变更,此时就需要更新所有以旧MAC生成的hh为新MAC。
邻居表项是以IP为键值查找的,因此通过IP可以查找相关的邻居表项neigh,前面说过neigh->hh可以遍历所有以之相关的缓存项,所以遍历它,并调用update函数。以以太网卡为例,update = neigh->dev->header_ops->cache_update ==> eth_header_cache_update,而eth_header_cache_update函数就是用新的MAC地址覆盖hh->data中的旧MAC地址。
neigh_update_hhs函数也说明了neighbour->hh指针的作用。
补充:缓存项hh的生命期从创建时起,会一直持续到邻居表项被删除,也就是调用neigh_destroy时,删除neigh->hh指向的所有缓存项。
参考:《Understanding Linux Network Internals》