支付宝中当面付的通过音频传输数据的研究(1)
近日公司提出了一个需求,要求做一个类似当面付中通过音频传输用户ID的方法。
拿到任务后马上祭起GOOGLE大法去查找。(此处再次吐槽一下GWF——我去年买了个表,超耐磨)
首先找到的是一个开源的软件 https://github.com/JesseGu/SinVoice 是Android的 。
首先试用,但是发现这个软件在传输过程中会有很多尖锐的声音产生,而支付宝就没有。
不管了,先看代码。。
里面有2个重要的类,SinGenerator(正弦生成)、VoiceRecognition(声音识别)。
经过研究 其原理就是通过SinGenerator将数据转换为不同频率的音频, 然后播放出去,接受方收到数据后查找从整数到负数变化的点,标记好后先后继续查找,当再找找到从整数到负数的变化点后,用新的变化点减去标记的变化点,就得出了一个时间,然后就可以算出这个正弦音频的频率。
生成音频的主要过程(
public void gen(int genRate, int duration) {
if (STATE_START == mState) {
mGenRate = genRate;
mDuration = duration;
if (null != mListener) {
mListener.onStartGen();
}
int n = mBits/2;
int totalCount = (mDuration * mSampleRate) / 1000; //441个采样点
double per = ( 2 * Math.PI * (double)mGenRate / (double) mSampleRate) ;
double d =0;
LogHelper.d(TAG, "genRate:" + genRate);
if (null != mCallback) {
mFilledSize = 0;
BufferData buffer = mCallback.getGenBuffer();
if (null != buffer) {
for (int i = 0; i < totalCount; ++i) {
if (STATE_START == mState) {
int out = (int) (Math.sin(dh)*n) ;
if (mFilledSize >= mBufferSize - 1) {
// free buffer
buffer.setFilledSize(mFilledSize);
mCallback.freeGenBuffer(buffer);
mFilledSize = 0;
buffer = mCallback.getGenBuffer();
if (null == buffer) {
LogHelper.d(TAG, "get null buffer");
break;
}
}
buffer.mData[mFilledSize++] = (byte) (out & 0xff);
if (BITS_16 == mBits) {
buffer.mData[mFilledSize++] = (byte) ((out >> 8) & 0xff);
}
d +=per;
} else {
LogHelper.d(TAG, "sin gen force stop");
break;
}
}
} else {
LogHelper.d(TAG, "get null buffer");
}
if (null != buffer) {
buffer.setFilledSize(mFilledSize);
mCallback.freeGenBuffer(buffer);
}
mFilledSize = 0;
if (null != mListener) {
mListener.onStopGen();
}
}
}
}
识别的主要函数
private void process(BufferData data) {
int size = data.getFilledSize() - 1;
short sh = 0;
for (int i = 0; i < size; i++) {
short sh1 = data.mData[i];
sh1 &= 0xff;
short sh2 = data.mData[++i];
sh2 <<= 8;
sh = (short) ((sh1) | (sh2));
if (!mIsStartCounting) {
if (STATE_STEP1 == mStep) {
if (sh < 0) {
mStep = STATE_STEP2;
}
} else if (STATE_STEP2 == mStep) {
if (sh > 0) {
mIsStartCounting = true;
mCirclePointCount = 0;
mStep = STATE_STEP1;
}
}
} else {
++mCirclePointCount;
if (STATE_STEP1 == mStep) {
if (sh < 0) {
mStep = STATE_STEP2;
}
} else if (STATE_STEP2 == mStep) {
if (sh > 0) {
// preprocess the circle
int circleCount = preReg(mCirclePointCount);
// recognise voice
reg(circleCount);
mCirclePointCount = 0;
mStep = STATE_STEP1;
}
}
}
}
}
后面的事情就是移植的IOS上,很简单,基本上就是把代码复制过去就可以了。
然后给领导看~~~ 领导一句话就将所有的努力变成了狗屎——声音太刺耳。。。。。。。。。
没有办法了,只好去研究当面付
1)录音。 用CoolEdit录音

这就是支付宝产生的音频 其中"咻"的一声是红色的部分,但是我们看到字两个咻之间还是有音频波形,但是听不见,所有由此判断 ,这部分数据肯定是在人的听力范围之外。也就是说, 不是次声波就是超声波。
放大这部分数据

放大的波形还是没有什么特点,而且频率都一样,接近50Hz(次声波),所以由此判断数据还是不对,只有继续放大。

好了到此我们可以肯定 支付宝应该是使用2个正弦的乘积产生的波形 sin(2*PI*超声频率/采样率)*sin(2*PI*次声频率/采样率)——很像调频的公式。
好了 我们可以修改SinGenerator这个类进行来产生类似支付宝的音频。结果很理想,播放出啦后听不见, 用CoolEdit可以采集到类似支付宝的数据。
为题出来了 怎么判断高频啊~~ 因为手机的采样最高为44100,也就是说 最多能表达22050Hz的波形, 而我们的差生的数据有20000Hz,基本上每个采样周期都其数据都回产生呢跨过基线的数据, 素以 已经不能SinVoice的方法判断频率了,太快了。
开始重点了
使用CoolEdit查看支付宝音频的频谱。。。。。。
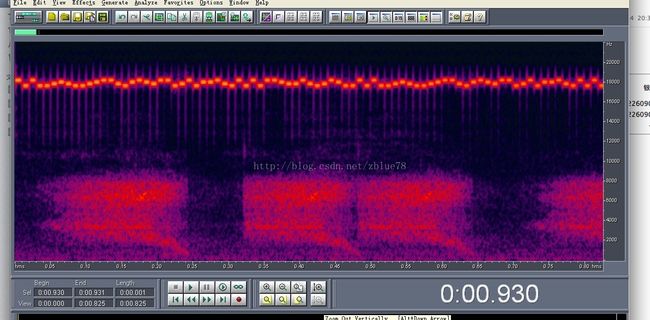
看到了什么,上面的粗线。。。。原来支付使用超声波频率并不一样,明显是一段一段的,由此判断 数据肯定就是这些。。而且每段都大概是20ms,吼吼。。数据出来了
仔细观察,支付宝的数据都是意48段重复播放的。
既然用CoolEdit的频谱能看到数据 我们用手机算出来这个频谱吧。。。(继续Google大法——再次吐槽GWF)(频谱的计算方法)
搜索后 悲剧了....真心看不懂啊用FFT计算连续信号的频谱.......好吧 怎么说有个关键词了 “FFT” 。什么是FFT呢 ——快速傅里叶变换-,继续不懂。。。。
哥是学计算机的 貌似没有学过这个啊,好吧就算是学过,毕业小20年了,早还给老师了。。。。。
没有办法 学习吧。。。 苦逼。。。。。
下面几篇文章,很不错
http://blog.csdn.net/lhfslhfs/article/details/7684494
http://blog.csdn.net/xuexiang0704/article/details/8295425
http://blog.csdn.net/v_JULY_v/article/details/6196862
好了有目标了 后边慢慢进行吧。。。。