CDH5.0.0使用hue中的oozie编辑器创建一个wordcount的mapreduce job
<workflow-app name="test4" xmlns="uri:oozie:workflow:0.4">
<start to="test4"/>
<action name="test4">
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}${outputDir}"/>
</prepare>
<job-xml>/shareScripts/xxmapred-site.xml</job-xml>
<configuration>
<property>
<name>mapreduce.job.map.class</name>
<value>com.besttone.hbase.demo.WordCount$TokenizerMapper</value>
</property>
<property>
<name>mapreduce.job.reduce.class</name>
<value>com.besttone.hbase.demo.WordCount$IntSumReducer</value>
</property>
<property>
<name>mapreduce.job.combine.class</name>
<value>com.besttone.hbase.demo.WordCount$IntSumReducer</value>
</property>
<property>
<name>mapreduce.job.output.key.class</name>
<value>org.apache.hadoop.io.Text</value>
</property>
<property>
<name>mapreduce.job.output.value.class</name>
<value>org.apache.hadoop.io.IntWritable</value>
</property>
<property>
<name>mapreduce.input.fileinputformat.inputdir</name>
<value>${inputDir}</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.outputdir</name>
<value>${outputDir}</value>
</property>
<property>
<name>mapred.mapper.new-api</name>
<value>true</value>
</property>
<property>
<name>mapred.reducer.new-api</name>
<value>true</value>
</property>
<property>
<name>mapreduce.job.reduces</name>
<value>1</value>
</property>
</configuration>
</map-reduce>
<ok to="end"/>
<error to="kill"/>
</action>
<kill name="kill">
<message>Action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
配置文件要注意的地方:
mapred.mapper.new-api和mapred.reducer.new-api这两个属性设置成true,表示使用新的api接口。老的API接口的配置属性和新的配置属性是不一样的,mapreduce打头的属性都是新接口属性,老接口属性是mapred打头的。
下面用图形化的方式来描述如何创建一个workflow
1 新建一个workflow: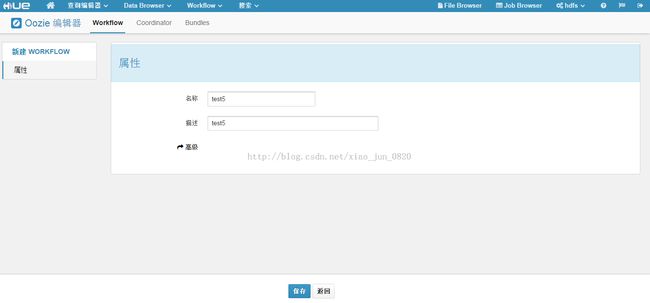
这里我们新建了一个workflow叫test5,然后点击保存。
2 查看一下这个workflow的工作目录在哪:

可以看到如图所示的工作目录,现在工作目录下面是空的,等提交了workflow后,在工作目录下面就会生成workflow.xml还有lib目录,里面存放相应的依赖包.
3 编辑这个workflow,拖一个mapreduce action到start和end之间:
转到mapreduce action的编辑界面,
Jar名称选择你自己编写的wordcount类打成的jar包,这个JAR包必须上传到HDFS上,我这里存放在HDFS的/sharelib目录下面。
准备阶段新增一个“添加删除”动作,填写删除的目录,因为mapreduce输出目录如果存在的话,提交JOB的时候会报错无法提交,所以在提交JOB之前需要删除输出目录,这里输出目录的写法是${outputDir},为EL表达式语言,即对输出目录进行了参数化,当你在提交workflow的时候,会弹出一个对话框让你填写这些参数。
job属性配置:
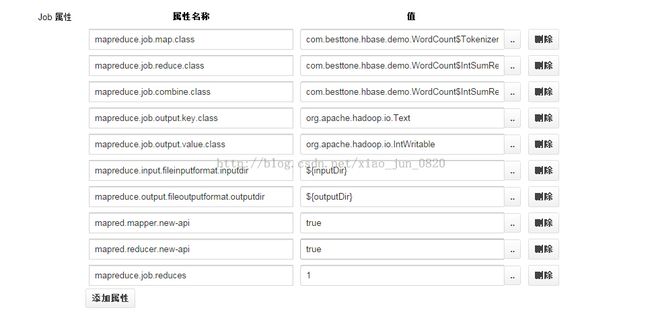
作业XML设置:
JOB属性配置会覆盖作业XML文件中的配置。作业XML一般都是配置一些通用的不长改变的属性,存成一个文件放到HDFS上去,经常变的就放到job属性配置中一个一个的配置。
3 配置好后,提交workflow,填写输入目录和输出目录两个参数,就job就开始运行了。
说明:oozie提交mapreduce job和传统的通过hadoop jar方式运行job不同,hadoop jar方式把该配置的属性都写在main方法里面了,而oozie 提交mapreduce不能这样做,所以必须把传统的main方法里设置的属性,都作为job属性设置一项一项的设置上。至于具体的属性名,可以通过查看源代码来找到,比如job.setMapperClass(TokenizerMapper.class);可以点进这个方法里面去看到底设置的是哪个属性名,常用的属性名都定义在MRJobConfig这个类中,比如public static final String MAP_CLASS_ATTR = "mapreduce.job.map.class";定义的是将要使用的map类。
workflow提交后,我们再次去查看工作区,可以看到如下图: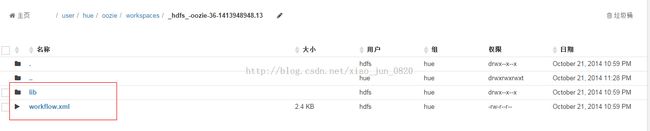
工作区下面多了workflow.xml和lib目录,lib目录里存放的是我们刚才设置的jar文件: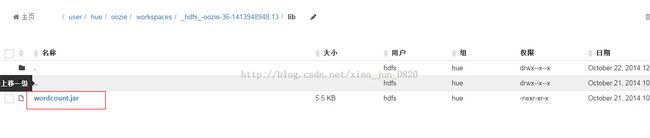
workflow.xml内容就是本文开头描述的XML代码片段。