git服务解析
Git 历险(一)
Git是Linus.Torvald为了管理Linux内核发起并开发的一个开源分布式版本控件系统(DVCS)。从2002年起,Linux 内核一直使用BitKeeper来进行版本管理,但是在2005年BitKeeper和Linux 内核开源社区的合作关系结束,BitKeeper再也不能免费使用了,这迫使Linus决定开发一个开源界自已的版本控制系统。
传统的SVN、CVS 等版本控制系统,只有一个仓库(repository),用户必须要连上这个仓库才能开始提交;而Git之类的分布式版本控制系统(当然也还包括 BitKeeper、Mercurial等 等),它的每个工作目录都包含一个完整的仓库,它们可以支持离线工作,先把工作提交到本地仓库后再提交上远程的服务器上的仓库里。分布式的处理也让开发更 为便捷,开发人员可以很方便的在本地创建分支来进行日常开发,每个人的本地仓库都是平等且独立,不会因为你的本地提交而直接影响别人。
老实说,Git的速度是我用的版本控制系统中最快的(SVN Mercurial Git)。我这里说的速度,包括本地提交(commit)、本地签出(checkout)、提交到远程仓库(git push)和从远程仓库获取(git fetch ,git pull);它的本地操作速度和本地文件系统在一个级别,远程仓库的操作速度和SFTP文件传输在一个级别。这当然和Git的内部实现机制有关,这里就不 多展开了,有兴趣的朋友可以看一下这里:Git is the next Unix。
我们在学一门新的语言时,往往是从一个“hello world” 程序开始的,那么Git历程也就从一个“hello Git”开始吧。
在这里假设各位同学的电脑都装好了Git,如果没有装好,可以先看一下这里(安装Git)。当然,后面的章节我会专门讲安装可能会碰到的问题。
我们首先打开Git的命令行:windows下是点击“Git Bash 快捷方式”;Linux或是Unix like平台的话就直接打开命令行界面就可以了。
备注:$符号后面的字符串代表的是命令行输入;命令行输入后的以#开始的黑体字符串代表注释;其它的部分则是命令行输出。
我们先用建一个仓库吧:
$mkdir testGit #建立仓库目录 $cd testGit #进入仓库目录 $git init #这会在当前的目录下建一个仓库 Initialized empty Git repository in e:/doc/Git/test/testGit/.git/
好的,前面的三行命令就建立了一个本地的Git仓库。这个仓库现在是一个空的仓库。
我们在命令行下执行:
$ git status #查看当前仓库的状态 # On branch master (在master分支上) # # Initial commit # nothing to commit (create/copy files and use "git add" to track) (现在没有任何台被提交的文件,复制或创建新的文件,再用”git add” 命令添加到暂存区中) $ git log #查看当前仓库的历史日志 fatal: bad default revision 'HEAD' (由于仓库里没有任提交在里面,所以它会报这个错。BTW: 这种提示是不是有点不友好呀:) )
现在就让我们在这个仓库里添加点内容吧。
$ echo “hello Git” > readme.txt #建立一个含有 hello Git 的文本文件 $ git add readme.txt #将readme.txt添加到暂存区中 $ git status #查看当前仓库的状态 # On branch master # # Initial commit # # Changes to be committed:(暂存里下次将被提交的修改) # (use "git rm --cached <file>..." to unstage) # # new file: readme.txt #
好的,文件即然被暂存到暂存区中,我们现在就可以把它提交到仓库里面去:)
$ git commit -m "project init" #将刚才的修改提交到本地仓库中 [master (root-commit) 8223db3] project init 1 files changed, 1 insertions(+), 0 deletions(-) create mode 100644 readme.txt $ git status # On branch master nothing to commit (working directory clean) (现在这个工作目录里没有什么要提交的东东,它是整洁的)
现在你执行一下git log 命令就会看到刚才的提交记录
$ git log commit 8223db3b064a9826375041c8fea020cb2e3b17d1 Author: liuhui998 <[email protected]> Date: Sat Jan 1 18:12:38 2011 +0800 project init
“8223db3b064a9826375041c8fea020cb2e3b17d1”这一串字符就是我们这次创建的提交的名字。看起来是不是很 熟,如果经常用电驴的朋友就会发现它就是和电驴里内容标识符一样,都是SHA1串。Git通过对提交内容进行 SHA1 Hash运算,得到它们的SHA1串值,作为每个提交的唯一标识。根据一般的密码学原理来说,如果两个提交的内容不相同,那么它们的名字就不会相同;反 之,如果它们的名字相同,就意味着它们的内容也相同。
现在我想改一下仓库里文件的内容,现提交到仓库中去
$ echo "Git is Cool" >> readme.txt #在文件的最后添加一行 $ git status #查看当前仓库的状态 # On branch master # Changed but not updated: (修改了,但是还没有暂存的内容) # (use "git add <file>..." to update what will be committed) # (use "git checkout -- <file>..." to discard changes in working directory) # # modified: readme.txt # no changes added to commit (use "git add" and/or "git commit -a")(没有修改可以被提交,使用 “git add” 命令添加文件到暂存区,或是使用“git commit -a” 命令强制提交当前目录下的所有文件)
OK,即然我们修改了仓库里被提交的文件,那么我想看一下我们
到底改了哪些地方,再决定是否提交。
$ git diff #查看仓库里未暂存内容和仓库已提交内容的差异 diff --git a/readme.txt b/readme.txt index 7b5bbd9..49ec0d6 100644 --- a/readme.txt +++ b/readme.txt @@ -1 +1,2 @@ hello Git +Git is Cool
很好,正如我们所愿,我们只是在readme.txt的最后一行添加了一行“Git is Cool”。
好的,我们现在再把 readme.txt放到暂存区里:
$ git add readme.txt
我们现在看一下仓库的状态:
$ git status # On branch master # Changes to be committed: # (use "git reset HEAD <file>..." to unstage) # # modified: readme.txt #
可以提交了:
$ git commit -m "Git is Cool" [master 45ff891] Git is Cool 1 files changed, 1 insertions(+), 0 deletions(-) (一个文件被修改,一行插入,零行删除)
再看一下新的日志:
$ git log commit 45ff89198f08365bff32364034aed98126009e44 Author: liuhui998 <[email protected]> Date: Sat Jan 1 18:17:07 2011 +0800 Git is Cool commit 8223db3b064a9826375041c8fea020cb2e3b17d1 Author: liuhui998 <[email protected]> Date: Sat Jan 1 18:12:38 2011 +0800 project init
“45ff89198f08365bff32364034aed98126009e44” 这个就是我们刚才提交修改时创建的提交。
Git历险记(二)——Git的安装和配置
各位同学,上回Git历险记(一)讲了一个 “hello Git” 的小故事。有的同学可能是玩过了其它分布式版本控制系统(DVCS),看完之后就触类旁通对Git就了然于胸了;也有的同学可能还如我当初入手Git一样,对它还是摸不着头脑。
从这一篇开始,我就将比较“啰嗦”的和大家一起从零开始经历Git使用的每一步,当然对我而言这也是一个重新认识Git的过程。
使用Git的第一步肯定是安装Git,因为在多数平台上Git是没有预装的。我平时主要的工作环境是windows和Linux(ubuntu),我想看这篇文章的同学多半也是在这两个平台下工作;下面我讲一下如何在这两个平台下安装和配置Git。
BTW:如果是苹果平台的用户的安装可以参看一下这里(1,2),配置和命令行的使用与windows、Linux(*nix)平台差别不大。
Linux (*nix) 平台
Linus开发Git的最初目的就是为了开发Linux内核服务的,自然它对Linux的平台支持也是最棒的。在Linux下安装Git大约有几种方法:
从源代码开始(这种方法也适合于多数*nix平台)
从Git官网的下载页面下载它最新稳定版的源代码,就可以从源代码开始编译、安装:
$ wget http://kernel.org/pub/software/scm/git/git-1.7.3.5.tar.bz2 $ tar -xjvf git-1.7.3.5.tar.bz2 $ cd git-1.7.3.5 $ make prefix=/usr all ;# prefix设置你的Git安装目录 $ sudo make prefix=/usr install ;# 以root权限运行
为了编译Git的源代码,我们还需要一些库: expat、curl、 zlib 和 openssl; 除了expat 外,其它的库可能在你的机器上都安装了。
使用安装包管理器(apt 或 yum)
在 fedora 等系统下用yum :
$ yum install git-core
在debian, ubuntu等系统下用apt :
$ apt-get install git-core
有时候,你系统里的安装包管理器出现了问题,或是要安装Git的机器不能上网、没有编译器的话,你可以从下面的站点去下载 “.deb” 或 “.rpm”的安装包:
- RPM Packages
- Stable Debs
Windows平台
windows平台有两个模拟*nix like运行环境的工具:cygwin,msys;Git在cygwin,msys下都有相应的移植版本。我个人觉得msys平台下的msysGit最好用,现在我在windows下也是用的这个版本。
很多同学可能要问,现在windows下有那多Git用户,为什么Git不直接出一个windows native版。俺当年翻看了一下Git的源代码,它里面使用了大量的*nix平台的native api,而这些api在windows下是没有的,所以必须要用cygwin、msys这样的一个中间层来满足软件移植的要求。
下面我“啰嗦”一下如何在windows下安装msysGit。
下载
到它的下载页面去下载一个最新的完整安装包,笔者在撰写本文时下载的是这个。
安装
安装的过程没有什么好说的,一般是开始安装后,一路的点击“下一步”。由于windows平台的换行符(CRLF)和Linux(*nix)平台的换行符(LF)不同,那么在windows下开发其它平台软件的朋友有一个地方要注意(见下图):
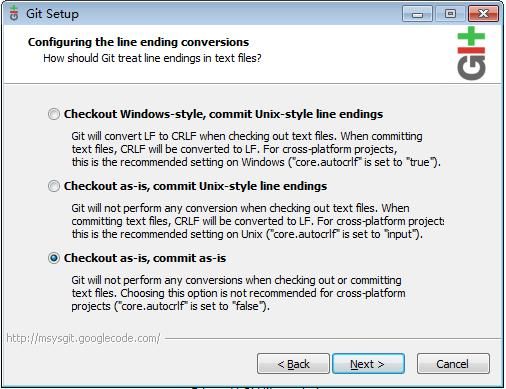
在这里一最好选“Checkout as-is, commit as-is”这个选项,这样,Git就不会修改你代码的换行符风格。
以前有个朋友因为选错了这个选项,以致他在windows平台下的一签出(checkout)其它平台的代码,就会显示”已修改“(modified),不过后来可能msysGit也认识到这个问题了,就把默认选项改成了这个选项。
BTW: 其实前面两项也是有用的,如果对windows和Linux(*nix)平台如何处理换行符很熟悉的话,也可以尝试一下前面两个选项:)
配置Git
在Linux下和windows下配置Git的方法差不多,只是在Linux下,可以在命令行里直接使用git config进行配置, 而在windows下则要先打开“Git Bash”,进入msysGit命令行界面,再用git config命令进行相应的配置操作。
好了,前面安装好了Git,现在我们开始配置:
第一个需要配置的就是用户的用户名和email,因为这些内容会出现在你的每一个提交(commit)里面的,像下面这样:
$ git log #我们用git log查看当前仓库的提交(commit)日志 commit 71948005382ff8e02dd8d5e8d2b4834428eece24 Author: author <[email protected]> Date: Thu Jan 20 12:58:05 2011 +0800 Project init
下面的这两行命令就是设置用户名和email:
$ git config --global user.name author #将用户名设为author $ git config --global user.email [email protected] #将用户邮箱设为[email protected]
Git的配置信息分为全局和项目两种,上面命令中带了“--global"参数,这就意味是在进行全局配置,它会影响本机上的每个一个Git项目。
大家看到,上面我们用的是@corpmail(公司邮箱);但是有时候我们可能也参与了一些开源项目,那么就需要新的用户名和自己的私人邮箱,Git 可以为每个项目设定不同的配置信息。
在命令行环境,进入Git项目所在目录,执行下面的命令:
$ git config user.name nickname#将用户名设为nickname $ git config user.email [email protected] #将用户邮箱设为[email protected]
Git的设计哲学和Linux(*nix)一样,尽量的使用“文本化”(Textuality);它里面尽量用文本化的形式存储信息,对于配置信息也更是如此,用户的这些配置信息全部是存储在文本文件中。Git的全局配置文件是存放在"~/.gitconfig"(用户目录下的.gitconfig)文件中:
我们用cat、head命令查看全局配置信息文件,并假设相关配置信息存储在文件的前3行(当然也有可能不在前3行,这里只是为了方便表示)
$ cat ~/.gitconfig | head -3 [user] name = author email = [email protected]
而项目配置文件是存放在Git项目所在目录的".git/config"文件中,这里也像上面一样用cat、head命令查看一下:
$ cat .git/config | head -3 [user] name = nickname email = [email protected]
如果大家对于Git熟悉后,可以直修改”~/.gitconfig”,”.git/config”这两个文件进行配置。
Git里还有很多可以配置的地方,大家可以参考一下git config 和 定制git。
Git 历险记(三)——创建一个自己的本地仓库
如果我们要把一个项目加入到Git的版本管理中,可以在项目所在的目录用git init命令建立一个空的本地仓库,然后再用git add命令把它们都加入到Git本地仓库的暂存区(stage or index)中,最后再用git commit命令提交到本地仓库里。
创建一个新的项目目录,并生成一些简单的文件内容:
$ mkdir test_proj $ cd test_proj $ echo “hello,world” > readme.txt
在项目目录创建新的本地仓库,并把项目里的所有文件全部添加、提交到本地仓库中去:
$ git init #在当前的目录下创建一个新的空的本地仓库 Initialized empty Git repository in /home/user/test_proj/.git/ $ git add . #把前目录下的所有文件全部添加到暂存区 $ git commit -m 'project init' #创建提交 [master (root-commit) b36a785] project init 1 files changed, 1 insertions(+), 0 deletions(-) create mode 100644 readme.txt
Git目录的结构
git init命令在项目的顶层目录中建了一个名为:“.git”的目录,它的别名是 “Git目录”(Git directory)。这时”Git目录”中虽然有一些文件,但是没有任何提交(commit)在里面,所以我们叫它是空仓库(empty Git repository)。
和 SVN不同,一个Git项目一般只在项目的根目录下建一个“.git”目录,而SVN则会在项目的每一个目录下建一个”.svn”目录;这也我喜欢Git的原因之一:)
Git把所有的历史提交信息全部存储在“Git目录”里,它就是一个Git项目的仓库;你对本地的源代码进行编辑修改后创建的提交也都会先保存在这里面,然后再推送到远端的服务器。当我们我把项目目录和“Git目录”一起拷到其它电脑里,它能马上正常的工作(所有的提交信息全都保存在Git目录里);甚至可以只把“Git目录”拷走也行,但是要再签出(checkout)一次。
Git为了 调试的方便,它可以指定项目的Git目录的位置。有两种办法:一是设置“GIT_DIR”环境变量,二是在命令行里设定“--git-dir--git-dir”参数指定它的位置,大家可以看一下这里(git(1) Manual Page)。
庖丁解牛
前面的这些东东我在第一篇里也大概的讲过一些,但是今天我们想不但要开动这辆叫“Git”的跑车,还想看看它里面有些什么样的零件,是怎么构成的。
OK,我们来看看“test_proj”项目里的“Git目录”的结构:
$cd test_proj/.git $ ls | more branches/ # 新版的Git已经不再使用这个目录,所以大家看到它 #一般会是空的 COMMIT_EDITMSG # 保存着上一次提交时的注释信息 config # 项目的配置信息 description # 项目的描述信息 HEAD # 项目当前在哪个分支的信息 hooks/ # 默认的“hooks” 脚本文件 index # 索引文件,git add 后把要添加的项暂存到这里 info/ # 里面有一个exclude文件,指定本项目要忽略的文件 #,看一下这里 logs/ # 各个refs的历史信息 objects/ # 这个目录非常重要,里面存储都是Git的数据对象 # 包括:提交(commits), 树对象(trees),二进制对象 #(blobs),标签对象(tags)。 #不明白没有关系,后面会讲的。 refs/ # 标识着你的每个分支指向哪个提交(commit)。
我先用git log命令来看一下这个Git项目里有哪些提交:
$ git log commit 58b53cfe12a9625865159b6fcf2738b2f6774844 Author: liuhui998 <[email protected]> Date: Sat Feb 19 18:10:08 2011 +0800 project init
大家可以看到目前只有一个提交(commit)对象,而它的名字就是:”58b53cfe12a9625865159b6fcf2738b2f6774844”。这个名字就是对象内容的一个SHA签名串值,只要对象里面的内容不同,那么我们就可以认为对象的名字不会相同,反之也成立。我在使用时一般不用把这个40个字符输全,只要把前面的5~8个字符输完就可以(前提是和其它的对象名不冲突)。为了方便表示,在不影响表达的情况下,我会只写SHA串值的前6个字符。
我们可以用git cat-file来看一下这个提交里的内容是什么:
$ git cat-file -p 58b53c tree 2bb9f0c9dc5caa1fb10f9e0ccbb3a7003c8a0e13 author liuhui998 <[email protected]> 1298110208 +0800 committer liuhui998 <[email protected]> 1298110208 +0800 project init
大家可以看到:提交“58b53c” 是引用一个名为“2bb9f0”的树对象(tree)。一个树对象(tree)可以引用一个或多个二进制对象(blob), 每个二进制对象都对应一个文件。 更进一步, 树对象也可以引用其他的树对象,从而构成一个目录层次结构。我们再看一下这个树对象(tree)里面有什么东东:
$ git cat-file -p 2bb9f0 100644 blob 2d832d9044c698081e59c322d5a2a459da546469 readme.txt
不难看出,2bb9f0”这个树对象(tree)包括了了一个二进制对象(blob),对应于我们在前面创建的那个叫 ”readme.txt”的文件。现在我们来看看这个”blob”里的数据是不是和前面的提交的内容一致:
$ git cat-file -p 2d832d hello,world
哈哈,熟悉的“hello,world”又回来了。
想不想看看提交对象、树对象和二进制对象是怎么在”Git目录“中存储的;没有问题,执行下面的命令,看看”.git/objects”目录里的内容:
$ find .git/objects .git/objects .git/objects/2b .git/objects/2b/b9f0c9dc5caa1fb10f9e0ccbb3a7003c8a0e13 .git/objects/2d .git/objects/2d/832d9044c698081e59c322d5a2a459da546469 .git/objects/58 .git/objects/58/b53cfe12a9625865159b6fcf2738b2f6774844 .git/objects/info .git/objects/pack
如果大家仔细看上面命令执行结果中的粗体字,所有的对象都使用SHA签名串值作为索引存储在”.git/objects”目录之下;SHA串的前两个字符作为目录名,后面的38个字符作为文件名。
这些文件的内容其实是压缩的数据外加一个标注类型和长度的头。类型可以是提交对象(commit)、二进制对象(blob)、 树对象(tree)或者标签对象(tag)。
如何clone一个远程项目
我身边的很多朋友是因为要得到某个开源项目的代码,所以才开始学习使用Git。而获取一个项目的代码的一般的做法就是用git clone命令进行直接复制。
例如,有些朋友可能想看一下最新的linux内核源代码,当我们打开它的网站时,发现有如下面的一段提示:
URL git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux-2.6.git http://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux-2.6.git https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux-2.6.git
URL下面的三行字符串表示三个地址,我们可以通过这三个地址得到同样的一份Linux内核源代码。
也就是说下面这三条命令最终得到的是同一份源代码:
git clone git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux-2.6.git git clone http://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux-2.6.git git cone https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux-2.6.git
我们先来看一下URL,git://、http://、https://这些代表是传输git仓库的协议形式,而“git.kernel.org“则代表了Git仓库存储的服务器名字(域名),“/pub/scm/linux/kernel/git/torvalds/linux-2.6.git” 则代表了Git仓库在服务器上位置。
Git 仓库除了可以通过上面的git、http、https协议传输外还可以通过ssh、ftp(s)、rsync等协议来传输。git clone的本质就是把“Git目录”里面的内容拷贝过来,大家想想看,一般的“Git目录”里有成千上万的各种对象(提交对象,树对象,二进制对象......),如果逐一复制的话,其效率就可想而知。
如果通过git、ssh协议传输,服务器端会在传输前把需要传输的各种对象先打好包再进行传输;而http(s)协议则会反复请求要传输的不同对象。如果仓库里面的提交不多的话,前者和后者的效率相差不多;但是若仓库里有很多提交的话,git、ssh协议进行传输则会更有效率。
不过现在Git对http(s)协议传输Git仓库做了一定的优化,http(s)传输现在也能达到ssh协议的效率,有兴趣的朋友可以看一下这里(Smart HTTP Transport)。
好的,现在我们执行了下面这条命令,把linux-2.6的最新版源代码clone下来:
$cd ~/ $mkdir temp $git clone git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux-2.6.git Initialized empty Git repository in /home/liuhui/temp/linux-2.6/.git/ remote: Counting objects: 1889189, done. remote: Compressing objects: 100% (303141/303141), done. Receiving objects: 100% (1889189/1889189), 385.03 MiB | 1.64 MiB/s, done. remote: Total 1889189 (delta 1570491), reused 1887756 (delta 1569178) Resolving deltas: 100% (1570491/1570491), done. Checking out files: 100% (35867/35867), done.
当我们执行了“git clone git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux-2.6.git”这条命令后大家可以看到这条输出:
Initialized empty Git repository in /home/user/temp/linux-2.6/.git/
这就是意味着我们在本地先建了一个“linux-2.6”目录,然后在这个目录建了一个空的Git本地仓库(Git目录);里面将会存储从网上拉下来的历史提交。
下面两条输入代表服务器现在调用 git-pack-objects 对它的仓库进行打包和压缩:
remote: Counting objects: 1888686, done. remote: Compressing objects: 100% (302932/302932), done.
然后客户端接收服务器端发过送过来的数据:
Receiving objects: 100% (1889189/1889189), 385.03 MiB | 1.64 MiB/s, done.
在我们执行完上面的clone linux-2.6代码的的操作后,Git会从“Git目录”里把最新的代码到签出(checkout)到“linux-2.6”这个目录里面。我们一般把本地的“linux-2.6”这个目录叫做”工作目录“(work directory),它里面保存着你从其它地方clone(or checkout)过来的代码。当你在项目的不同分支间切换时,“工作目录”中的文件可能会被替换或者删除;“工作目录”只是保存着当前的工作,你可以修改里面文件的内容直到下次提交为止。
大家还记得前面的“庖丁解牛”吗,是不是觉得只杀一头叫“hello,world”的小牛太不过瘾了。没有问题,拿起前面的那把小刀,来剖析一下现在躺在你硬盘里这头叫“linux-2.6”大牛看看,我想一定很好玩。
Git历险记(四)——索引与提交的幕后故事
不一样的索引
我想如果看过《Git历险记》的前面三篇文章的朋友可能已经知道怎么用git add,git commit这两个命令了;知道它们一个是把文件暂存到索引中为下一次提交做准备,一个创建新的提交(commit)。但是它们台前幕后的一些有趣的细节大家不一定知晓,请允许我一一道来。
Git 索引是一个在你的工作目录(working tree)和项目仓库间的暂存区域(staging area)。有了它, 你可以把许多内容的修改一起提交(commit)。 如果你创建了一个提交(commit),那么提交的一般是暂存区里的内容, 而不是工作目录中的内容。
一个Git项目中文件的状态大概分成下面的两大类,而第二大类又分为三小类:
- 未被跟踪的文件(untracked file)
- 已被跟踪的文件(tracked file)
- 被修改但未被暂存的文件(changed but not updated或modified)
- 已暂存可以被提交的文件(changes to be committed 或staged)
- 自上次提交以来,未修改的文件(clean 或 unmodified)
看到上面的这么多的规则,大家早就头大了吧。老办法,我们建一个Git测试项目来试验一下:
我们先来建一个空的项目:
$rm -rf stage_proj $mkdir stage_proj $cd stage_proj $git init Initialized empty Git repository in /home/test/work/test_stage_proj/.git/
我们还创建一个内容是“hello, world”的文件:
$echo "hello,world" > readme.txt
现在来看一下当前工作目录的状态,大家可以看到“readme.txt”处于未被跟踪的状态(untracked file):
$git status # On branch master # # Initial commit # # Untracked files: # (use "git add <file>..." to include in what will be committed) # # readme.txt nothing added to commit but untracked files present (use "git add" to track)
把“readme.txt"加到暂存区: $git add readme.txt
现在再看一下当前工作目录的状态:
$git status # On branch master # # Initial commit # # Changes to be committed: # (use "git rm --cached <file>..." to unstage) # # new file: readme.txt #
可以看到现在"readme.txt"的状态变成了已暂存可以被提交(changes to be committed),这意味着我们下一步可以直接执行“git commit“把这个文件提交到本地的仓库里去了。
暂存区(staging area)一般存放在“git目录“下的index文件(.git/index)中,所以我们把暂存区有时也叫作索引(index)。索引是一个二进制格式的文件,里面存放了与当前暂存内容相关的信息,包括暂存的文件名、文件内容的SHA1哈希串值和文件访问权限,整个索引文件的内容以暂存的文件名进行排 序保存的。
但是我不想马上就把文件提交,我想看一下暂存区(staging area)里的内容,我们执行git ls-files命令看一下:
$git ls-files --stage 100644 2d832d9044c698081e59c322d5a2a459da546469 0 readme.txt
我们如果有看过上一篇文章里 的"庖丁解牛", 你会发现“git目录“里多出了”.git/objects/2d/832d9044c698081e59c322d5a2a459da546469”这么一个文件,再执行“git cat-file -p 2d832d” 的话,就可以看到里面的内容正是“hello,world"。Git在把一个文件添加暂存区时,不但把它在索引文件(.git/index)里挂了号,而且把它的内容先保存到了“git目录“里面去了。
如果我们执行”git add“命令时不小心把不需要的文件也加入到暂存区中话,可以执行“git rm --cached filename" 来把误添加的文件从暂存区中移除。
现在我们先在"readme.txt"文件上做一些修改后:
$echo "hello,world2" >> readme.txt
再来看一下暂存区的变化:
$git status # On branch master # # Initial commit # # Changes to be committed: # (use "git rm --cached <file>..." to unstage) # # new file: readme.txt # # Changed but not updated: # (use "git add <file>..." to update what will be committed) # (use "git checkout -- <file>..." to discard changes in working directory) # # modified: readme.txt #
大家可以看到命令输出里多了一块内容:“changed but not updated ...... modified: readme.txt”。大家可能会觉得很奇怪,我前面不是把"readme.txt"这个文件给添加到暂存区里去了吗,这里怎么又提示我未添加到暂存区 (changed but not updated)呢,是不是Git搞错了呀。
Git 没有错,每次执行“git add”添加文件到暂存区时,它都会把文件内容进行SHA1哈希运算,在索引文件中新加一项,再把文件内容存放到本地的“git目录“里。如果在上次执行 “git add”之后再对文件的内容进行了修改,那么在执行“git status”命令时,Git会对文件内容进行SHA1哈希运算就会发现文件又被修改了,这时“readme.txt“就同时呈现了两个状态:被修改但未被暂存的文件(changed but not updated),已暂存可以被提交的文件(changes to be committed)。如果我们这时提交的话,就是只会提交第一次“git add"所以暂存的文件内容。
我现在对于“hello,world2"的这个修改不是很满意,想要撤消这个修改,可以执行git checkout这个命令:
$git checkout -- readme.txt
现在再来看一下仓库里工作目录的状态:
$git status # On branch master # # Initial commit # # Changes to be committed: # (use "git rm --cached <file>..." to unstage) # # new file: readme.txt #
好的,现在项目恢复到我想要的状态了,下面我就用git commit 命令把这个修改提交了吧:
$git commit -m "project init" [master (root-commit) 6cdae57] project init 1 files changed, 1 insertions(+), 0 deletions(-) create mode 100644 readme.txt
现在我们再来看一下工作目录的状态:
$git status # On branch master nothing to commit (working directory clean)
大家可以看到“nothing to commit (working directory clean)”;如果一个工作树(working tree)中所有的修改都已提交到了当前分支里(current head),那么就说它是干净的(clean),反之它就是脏的(dirty)。
SHA1值内容寻址
正如Git is the next Unix 一文中所说的一样,Git是一种全新的使用数据的方式(Git is a totally new way to operate on data)。Git把它所管理的所有对象(blob,tree,commit,tag……),全部根据它们的内容生成SHA1哈希串值作为对象名;根据目前的数学知识,如果两块数据的SHA1哈希串值相等,那么我们就可以认为这两块数据是相同 的。这样会带来的几个好处:
- Git只要比较对象名,就可以很快的判断两个对象的内容是否相同。
- 因为在每个仓库(repository)的“对象名”的计算方法都完全一样,如果同样的内容存在两个不同的仓库中,就会存在相同的“对象名”。
- Git还可以通过检查对象内容的SHA1的哈希值和“对象名”是否匹配,来判断对象内容是否正确。
我们通过下面的例子,来验证上面所说的是否属实。现在创建一个和“readme.txt“内容完全相同的文件”readme2.txt“,然后再把它提交到本地仓库中:
$echo "hello,world" > readme2.txt $git add readme2.txt $git commit -m "add new file: readme2.txt" [master 6200c2c] add new file: readme2.txt 1 files changed, 1 insertions(+), 0 deletions(-) create mode 100644 readme2.txt
下面的这条很复杂的命令是查看当前的提交(HEAD)所包含的blob对象:
$git cat-file -p HEAD | head -n 1 | cut -b6-15 | xargs git cat-file -p 100644 blob 2d832d9044c698081e59c322d5a2a459da546469 readme.txt 100644 blob 2d832d9044c698081e59c322d5a2a459da546469 readme2.txt
我们再来看看上一次提交(HEAD^)所包含的blob对象:
$git cat-file -p HEAD^ | head -n 1 | cut -b6-15 | xargs git cat-file -p 100644 blob 2d832d9044c698081e59c322d5a2a459da546469 readme.txt
很明显大家看到尽管当前的提交比前一次多了一个文件,但是它们之间却是在共用同一个blob对象:“2d832d9”。
No delta, just snapshot
Git 与大部分你熟悉的版本控制系统,如Subversion、CVS、Perforce 之间的差别是很大的。传统系统使用的是: “增量文件系统” (Delta Storage systems),它们存储是每次提交之间的差异。而Git正好与之相反,它是保存的是每次提交的完整内容(snapshot);它会在提交前根据要提交 的内容求SHA1哈希串值作为对象名,看仓库内是否有相同的对象,如果没有就将在“.git/objects"目录创建对应的对象,如果有就会重用已有的 对象,以节约空间。
下面我们来试验一下Git是否真的是以“snapshot”方式保存提交的内容。
先修改一下"readme.txt",给里面加点内容,再把它暂存,最后提交到本地仓库中:
$echo "hello,world2" >> readme.txt $git add readme.txt $git commit -m "add new content for readme.txt" [master c26c2e7] add new content for readme.txt 1 files changed, 1 insertions(+), 0 deletions(-)
我们现在看看当前版本所包含的blob对象有哪些:
$git cat-file -p HEAD | head -n 1 | cut -b6-15 | xargs git cat-file -p 100644 blob 2e4e85a61968db0c9ac294f76de70575a62822e1 readme.txt 100644 blob 2d832d9044c698081e59c322d5a2a459da546469 readme2.txt
从上面的命令输出,我们可以看到"readme.txt"已经对应了一个新的blob对象:“2e4e85a”,而之前版本的"readme.txt“对应的blob对象是:“2d832d9”。下面我们再来看一看这两个”blob“里面的内容和我们的预期是否相同:
$git cat-file -p 2e4e85a hello,world hello,world2 $git cat-file -p 2d832d9 hello,world
大家可以看到,每一次提交的文件内容还是全部保存的(snapshot)。
小结
Git内在机制和其它传统的版本控制系统(VCS)间存在本质的差异,所以Git的里"add"操作的含义和其它VCS存在差别也不足为奇,“git add“不但能把未跟踪的文件(untracked file)添加到版本控制之下,也可以把修改了的文章暂存到索引中。
同时,由于采用“SHA1哈希串值内容寻值“和”快照存储(snapshot)“,让Git成为一个速度非常非常快的版本控制系统(VCS)。
Git历险记(五)——Git里的分支&合并
分支与合并
在Git里面我们可以创建不同的分支,来进行调试、发布、维护等不同工作,而互不干扰。下面我们还是来创建一个试验仓库,看一下Git分支运作的台前幕后:
$rm -rf test_branch_proj $mkdir test_branch_proj $cd test_branch_proj $git init Initialized empty Git repository in /home/test/test_branch_proj/.git/
我们如以往一样,创建一个“readme.txt”文件并把它提交到仓库中:
$echo "hello, world" > readme.txt $git add readme.txt $git commit -m "project init" [master (root-commit) 0797f4f] project init 1 files changed, 1 insertions(+), 0 deletions(-) create mode 100644 readme.txt
我们来看一下工作目录(working tree)的当前状态:
$git status # On branch master nothing to commit (working directory clean)
大家如果注意的话,可以看到“# On branch master”这么一行,这表示我们现在正在主分支(master)上工作。当我们新建了一个本地仓库,一般就是默认处在主分支(master)上。下面我们一起看一下Git是如何存储一个分支的:
$cd .git $cat HEAD ref: refs/heads/master
“.git/HEAD”这个文件里保存的是我们当前在哪个分支上工作的信息。
在Git中,分支的命名信息保存在“.git/refs/heads”目录下:
$ls refs/heads master
我们可以看到目录里面有一个名叫“master”文件,我们来看一下里面的内容:
$cat refs/heads/master 12c875f17c2ed8c37d31b40fb328138a9027f337
大家可以看到这是一个“SHA1哈希串值”,也就是一个对象名,我们再看看这是一个什么类型的对象:
$cat refs/heads/master | xargs git cat-file -t commit
是的,这是一个提交(commit),“master”文件里面存有主分支(master)最新提交的“对象名”;我们根据这个“对象名”就可以可找到对应的树对象(tree)和二进制对象(blob),简而言之就是我能够按“名”索引找到这个分支里所有的对象。
读者朋友把我们文章里的示例在自己的机器上执行时会发现,“cat refs/heads/master”命令的执行结果和和文章中的不同。在本文里这个提交(commit)的名字是: “12c875f17c2ed8c37d31b40fb328138a9027f337”,前面我讲Git是根据对象的内容生成“SHA1哈希串值”作为 名字,只要内容一样,那么的对应的名字肯定是一样的,为什么这里面会不一样呢? Git确实根据内容来生成名字的,而且同名(SHA1哈希串值)肯定会有 相同内容,但是提交对象(commit)和其它对象有点不一样,它里面会多一个时间戳(timestamp),所以在不同的时间生成的提交对象,即使内容 完全一样其名字也不会相同。
下面命令主是查看主分支最新提交的内容:
$cat refs/heads/master | xargs git cat-file -p tree 0bd1dc15d804534cf25c5cb53260fd03c84fd4b9 author liuhui998 <[email protected]> 1300697913 +0800 committer liuhui998 <[email protected]> 1300697913 +0800 project init
“1300697913 +0800”这就是时间戳(timestamp)。
现在查看此分支里面所包含的数据(blob)
$cat refs/heads/master | xargs git cat-file -p | head -n 1 | cut -b6-15 | xargs git cat-file -p 100644 blob 4b5fa63702dd96796042e92787f464e28f09f17d readme.txt
查看当前的readme.txt
$git cat-file -p 4b5fa63 hello, world $cd ..
好的,前面是在主分支(master)里面玩,下面我们想要创建一个自己的测试分支来玩一下。git branch命令可以创建一个新的分支,也可以查看当前仓库里有的分支。下面先创建一个叫“test”的分支: $git branch test
再来看一下当前项目仓库中有几个分支:
$git branch * master test
我们现在签出“test”分支到工作目录里:
$git checkout test
现在再来看一下我们处在哪个分支上:
$git branch master * test
好的,我们现在在“test”分支里面了,那么我们就修改一下“readme.txt”这个文件,再把它提交到本地的仓库里面支:
$echo "In test branch" >> readme.txt $git add readme.txt $git commit -m "test branch modified" [test 7f3c997] test branch modified 1 files changed, 1 insertions(+), 0 deletions(-)
当看当前版本所包含的blob:
$git cat-file -p HEAD | head -n 1 | cut -b6-15 | xargs git cat-file -p
我们现在再像前面一样的看看Git如何存储“test”这个分支的,先来看看“.git/HEAD”这个文件是否指向了新的分支:
$cd .git $cat HEAD ref: refs/heads/test
没错,“.git/HEAD”确实指向的“test”分支。再来看看“.git/refs/heads”目录里的内容:
$ls refs/heads master test
我们可以看到目录里面多了一个名叫“test”文件,我们来看一下里面的内容:
$cat refs/heads/test 7f3c9972577a221b0a30b58981a554aafe10a104
查看测试分支(test)最新提交的内容:
$cat refs/heads/test | xargs git cat-file -p tree 7fa3bfbeae072063c32621ff08d51f512a3bac53 parent b765df9edd4db791530f14c2e107aa40907fed1b author liuhui998 <[email protected]> 1300698655 +0800 committer liuhui998 <[email protected]> 1300698655 +0800 test branch modified
再来查看此分支里面所包含的数据(blob):
$cat refs/heads/test | xargs git cat-file -p | head -n 1 | cut -b6-15 | xargs git cat-file -p 100644 blob ebe01d6c3c2bbb74e043715310098d8da2baa4bf readme.txt
查看当前”readme.txt”文件里的内容:
$git cat-file -p ebe01d6 hello, world In test branch cd ..
我们再回到主分支里面:
$git checkout master Switched to branch 'master' $git checkout master $cat readme.txt hello, world
如我们想看看主分支(master)和测试分支(test)之间的差异,可以使用git diff命令来查看它们之间的diff:
$git diff test diff --git a/readme.txt b/readme.txt index ebe01d6..4b5fa63 100644 --- a/readme.txt +++ b/readme.txt @@ -1,2 +1 @@ hello, world -In test branch
大家可以以到当前分支与测试分支(test)相比,少了一行内容:“-In test branch”。
如果执行完git diff命令后认为测试分支(test)的修改无误,能合并时,可以用git merge命令把它合并到主分支(master)中:
$git merge test Updating b765df9..7f3c997 Fast-forward readme.txt | 1 + 1 files changed, 1 insertions(+), 0 deletions(-)
“Updating b765df9..7f3c997”表示现在正在更新合并“b765df9”和“7f3c997”两个提交(commit)之间的内容;“b765df9”代表着主分支(master),“7f3c997”代表测试分支(test)。
“Fast-forward”在这里可以理解为顺利合并,没有冲突。“readme.txt | 1 +”表示这个文件有一行被修改,“1 files changed, 1 insertions(+), 0 deletions(-)”,表示这一次合并只有一个文件被修改,一行新数据插入,0 行被删除。
我们现在看一下合并后的“readme.txt”的内容:
$cat readme.txt hello, world In test branch
内容没有错,是“master”分支和“test”分支合并后的结果,再用“git status”看一下,当前工作目录的状态也是干净的(clean)。
$git status # On branch master nothing to commit (working directory clean)
好的,现在测试分支(test)结束了它的使命,没有存在的价值的,可以用“git branch -d”命令把这个分支删掉:
$git branch -d test Deleted branch test (was 61ce004).
如果你想要删除的分支还没有被合并到其它分支中去,那么就不能用“git branch -d”来删除它,需要改用“git branch -D”来强制删除。
如何处理冲突(conflict)
前面说了分支的一些事情,还简单地合并了一个分支。但是平时多人协作的工作过程中,几乎没有不碰到冲突(conflict)的情况,下面的示例就是剖析一下冲突成因及背后的故事:
还是老规矩,新建一个空的Git仓库作试验:
$rm -rf test_merge_proj $mkdir test_merge_proj $cd test_merge_proj $git init Initialized empty Git repository in /home/test/test_merge_proj/.git/
在主分支里建一个“readme.txt”的文件,并且提交本地仓库的主分支里(master):
$echo "hello, world" > readme.txt $git add readme.txt $git status # On branch master # # Initial commit # # Changes to be committed: # (use "git rm --cached <file>..." to unstage) # # new file: readme.txt # git commit -m "project init" [master (root-commit) d58353e] project init 1 files changed, 1 insertions(+), 0 deletions(-) create mode 100644 readme.txt
当看当前版本所包含的blob:
$git cat-file -p HEAD | head -n 1 | cut -b6-15 | xargs git cat-file -p 100644 blob 4b5fa63702dd96796042e92787f464e28f09f17d readme.txt
虽然前面把“readme.txt”这个文件提交了,但是暂存区里还是会暂存一下,直到下次“git add”时把它冲掉:
$git ls-files --stage 100644 4b5fa63702dd96796042e92787f464e28f09f17d 0 readme.txt
然后再创建测试分支(test branch),并且切换到测试分支下工作:
$git branch test $git checkout test Switched to branch 'test'
再在测试分支里改写“readme.txt”的内容,并且提交到本地仓库中:
$echo "hello, mundo" > readme.txt $git add readme.txt $git commit -m "test branch modified" [test 7459649] test branch modified 1 files changed, 1 insertions(+), 1 deletions(-)
现在看一下当前分支里的“readme.txt”的“SHA1哈希串值”确实不同了:
$git cat-file -p HEAD | head -n 1 | cut -b6-15 | xargs git cat-file -p 100644 blob 034a81de5dfb592a22039db1a9f3f50f66f474dd readme.txt
暂存区里的东东也不一样了:
$git ls-files --stage 100644 034a81de5dfb592a22039db1a9f3f50f66f474dd 0 readme.txt
现在我们切换到主分支(master)下工作,再在“readme.txt”上作一些修改,并把它提交到本地的仓库里面:
$git checkout master Switched to branch 'master' $git add readme.txt echo "hola,world" > readme.txt $git add readme.txt $git commit -m "master branch modified" [master 269ef45] master branch modified 1 files changed, 1 insertions(+), 1 deletions(-)
现在再来看一下当前分支里的“readme.txt”的“SHA1哈希串值”:
$git cat-file -p HEAD | head -n 1 | cut -b6-15 | xargs git cat-file -p 100644 blob aac629fb789684a5d9c662e6548fdc595608c002 readme.txt
暂存区里的内容也改变了:
$git ls-files --stage 100644 aac629fb789684a5d9c662e6548fdc595608c002 0 readme.txt
主分支(master) 和测试分支(test)里的内容已经各自改变了(diverged),我们现在用“git merge”命令来把两个分支合一下看看:
$git merge test Auto-merging readme.txt CONFLICT (content): Merge conflict in readme.txt Automatic merge failed; fix conflicts and then commit the result.
合并命令的执行结果不是“Fast-foward”,而是“CONFLICT”。是的,两个分支的内容有差异,致使它们不能自动合并(Auto-merging)。
还是先看一下工作目录的状态:
$git status # On branch master # Unmerged paths: # (use "git add/rm <file>..." as appropriate to mark resolution) # # both modified: readme.txt # no changes added to commit (use "git add" and/or "git commit -a")
现在Git提示当前有一个文件“readme.txt”没有被合并,原因是“both modified”。
再看一下暂存区里的内容:
$git ls-files --stage 100644 4b5fa63702dd96796042e92787f464e28f09f17d 1 readme.txt 100644 aac629fb789684a5d9c662e6548fdc595608c002 2 readme.txt 100644 034a81de5dfb592a22039db1a9f3f50f66f474dd 3 readme.txt
看一下里面的每个blob对象的内容:
$git cat-file -p 4b5fa6 hello, world $git cat-file -p aac629 hola,world $git cat-file -p 034a81 hello, mundo
我们不难发现,“aac629”是当前主分支的内容,“034a81”是测试分支里的内容,而“4b5fa6”是它们共同父对象(Parent)里的内容。因为在合并过程中出现了错误,所以Git把它们三个放到了暂存区了。
现在我们再来看一下工作目录里的“readme.txt”文件的内容:
$cat readme.txt <<<<<<< HEAD hola,world ======= hello, mundo >>>>>>> test
“<<<<<<< HEAD“下面就是当前版本里的内容;而“=======”之下,“>>>>>>> test”之上则表示测试分支里与之对应的有冲突的容。修复冲突时我们要做的,一般就是把“ <<<<<<< HEAD”,“=======”和“ >>>>>>> test”这些东东先去掉,然后把代码改成我们想要的内容。
假设我们用编辑器把“readme.txt“改成了下面的内容:
$cat readme.txt hola, mundo
然再把改好的“readme.txt”用“git add”添加到暂存区中,最后再用“git commit”提交到本地仓库中,这个冲突(conflict)就算解决了:
$git add readme.txt $git commit -m "fix conflict" [master ebe2f18] fix conflict
这里看起来比较怪异的地方是Git解决了冲突的办法:怎么用“git add”添加到暂存区去,“git add”不是用来未暂存文件的吧,怎么又来解决冲突了。不过我想如果你仔细读过上一篇文章的话就不难理解,因为Git是一个“snapshot”存储系统,所有新增加的内容都是直接存储的,而不是和老版本作一个比较后存储新旧版本间的差异。
Git里面合并两个版本之间的同一文件,如果两者间内容相同则不作处理,两者间内容不同但是可以合并则产生一个新的blob对象,两者间内容不同但是合并时产生了冲突,那么我们解决了冲突后要把文件“git add”到暂存区中再“git commit”提交到本地仓库即可,这就和前面一样产生一个新的blob对象。
假设我们对合并的结果不满意,可以用下面的命令来撤消前面的合并:
$git reset --hard HEAD^ HEAD is now at 050d890 master branch modified
从git reset(2)命令的输出结果可以看到,主分支已经回到了合并前的状态了。
我们再用下面的命令看一下“readme.txt”文件,确认一下文件改回来没有:
$cat readme.txt hola,world
小结
由于Git采用了“SHA1哈希串值内容寻值”、“快照存储(snapshot)”等方法, Git中创建分支代价是很小的速度很快;也这是因为如此,它处理合并冲突的方法与众不同。
在这里我想起了“C语言就是汇编(计算机硬件)的一个马甲”这句话,其实Git也就是底层文件系统的一个马甲,只不过它带了版本控制功能,而且更加高效。Git里有些命令可能不是很好理解(如解决合并冲突用git add),但是对于系统层而言,它是最高效的,就像是C语言的数组下标从0开始一样。