关于ORACLE正则表达式一些
那个Oracle的正则表达式4个函数看起来简单用起来麻烦,记起来繁琐! 一般很讨厌开源的东西搞个参数那么复杂,那么难用,要注意太多细节了。
ORACLE中的支持正则表达式的函数主要有下面四个:
1,REGEXP_LIKE :与LIKE的功能相似
2,REGEXP_INSTR :与INSTR的功能相似
3,REGEXP_SUBSTR :与SUBSTR的功能相似
4,REGEXP_REPLACE :与REPLACE的功能相似
regexp_like 只能用于条件表达式,和 like 类似,但是使用的正则表达式进行匹配,语法很简单:
regexp_substr 函数,和 substr 类似,用于拾取合符正则表达式描述的字符子串,语法如下:
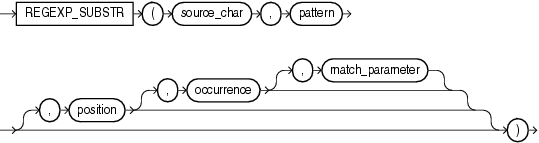
上面这个模式参数就复杂了些 常用组合以下
regexp_substr (string, pattern, position)
regexp_substr (string, pattern, position, occurence)
regexp_substr (string, pattern, position, occurence, match_parameters)
regexp_instr 函数,和 instr 类似,用于标定符合正则表达式的字符子串的开始位置,语法如下:
regexp_instr (string, pattern)
regexp_instr (string, pattern, position)
regexp_instr (string, pattern, position, occurence)
regexp_instr (string, pattern, position, occurence, return-option)
regexp_instr (string, pattern, position, occurence, return-option, parameters)
regexp_replace 函数,和 replace 类似,用于替换符合正则表达式的字符串,语法如下:
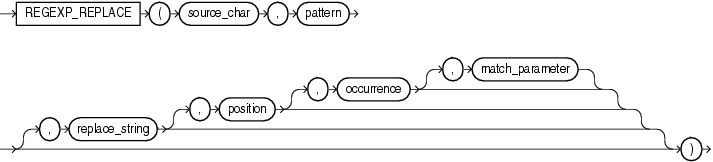
这里解析一下几个参数的含义:
1。source_char,输入的字符串,可以是列名或者字符串常量、变量。
2。pattern,正则表达式。
3。match_parameter,匹配选项取值范围: i:大小写不敏感; c:大小写敏感;n:点号 . 不匹配换行符号;m:多行模式;x:扩展模式,忽略正则表达式中的空白字符。
4。position,标识从第几个字符开始正则表达式匹配。
5。occurrence,标识第几个匹配组。
6。replace_string,替换的字符串。
在新的函数中使用正则表达式来代替通配符‘%’和‘_’。
正则表达式由标准的元字符(metacharacters)所构成:
'^' 匹配输入字符串的开始位置,在方括号表达式中使用,此时它表示不接受该字符集合。
'$' 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 'n' 或 'r'。
'.' 匹配除换行符 n之外的任何单字符。
'?' 匹配前面的子表达式零次或一次。
'+' 匹配前面的子表达式一次或多次。
'*' 匹配前面的子表达式零次或多次。
'|' 指明两项之间的一个选择。例子'^([a-z]+|[0-9]+)$'表示所有小写字母或数字组合成的字符串。
'( )' 标记一个子表达式的开始和结束位置。
'[]' 标记一个中括号表达式。
'{m,n}' 一个精确地出现次数范围,m=<出现次数<=n,'{m}'表示出现m次,'{m,}'表示至少出现m次。
num 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。
字符簇:
[[:alpha:]] 任何字母。
[[:digit:]] 任何数字。
[[:alnum:]] 任何字母和数字。
[[:space:]] 任何白字符。
[[:upper:]] 任何大写字母。
[[:lower:]] 任何小写字母。
[[:punct:]] 任何标点符号。
[[:xdigit:]] 任何16进制的数字,相当于[0-9a-fA-F]。
各种操作符的运算优先级
转义符
(), (?:), (?=), [] 圆括号和方括号
*, +, ?, {n}, {n,}, {n,m} 限定符
^, $, anymetacharacter 位置和顺序
| “或”操作
SQL> create table sunwg (id varchar2(100));
Table created.
SQL> insert into sunwg values ('<a href="http://sunwgneuqsoft.itpub.net/post/34741/447698">常见SQL访问索引的方式</a>');
1 row created.
SQL> commit;
Commit complete.
SQL> select * from sunwg;
ID
----------------------------------------------------------------------------------------------------
<a href="http://sunwgneuqsoft.itpub.net/post/34741/447698">常见SQL访问索引的方式</a>
1, REGEXP_LIKE
REGEXP_LIKE与LIKE类似,用REGEXP_LIKE能实现的操作大部分都可以用LIKE实现,不过要简单方便得多。
<a>目标:查询表sunwg中是否存在类似与3XX41的记录?
LIKE:
select * from sunwg where id like '%3__41%';
REGEXP_LIKE
select * from sunwg where regexp_like(id,'3..41');
<b>目标:查询表sunwg中是否存在类似与3XX41的记录,并且XX必须是数字?
LIKE:
这个LIKE我就想出来很好的实现办法了,唯一想到就是截取出来后判断该字符串是不是纯数字的。
REGEXP_LIKE
select * from sunwg where regexp_like(id,'3[0-9]{2}41');
用REGEXP_LIKE则可以简单快捷的得到结果。其他几个函数也都有类似的情况,下面的函数就不具体比较差异了,仅仅给出常用的用法。
2, REGEXP_INSTR
<a>目标:查询表sunwg中是否存在类似与3XX41的字符串第一次出现的位置?
SQL> select regexp_instr(id,'3..41',1,1) from sunwg;
REGEXP_INSTR(ID,'3..41',1,1)
----------------------------
46
SQL> select substr(id,46,5) from sunwg;
SUBST
-----
34741
3, REGEXP_SUBSTR
<a>目标:截取出表sunwg中的URL地址?
SQL> select regexp_substr(id,'http[0-9a-zA-Z/:.]+') from sunwg;
REGEXP_SUBSTR(ID,'HTTP[0-9A-ZA-Z/:.]+')
----------------------------------------------------------------------------------------------------
http://sunwgneuqsoft.itpub.net/post/34741/447698
4, REGEXP_REPLACE
<a>目标:替换表sunwg中的URL的地址为www.163.com?
SQL> select regexp_replace(id,'http[0-9a-zA-Z/:.]+','www.163.com') from sunwg;
REGEXP_REPLACE(ID,'HTTP[0-9A-ZA-Z/:.]+','WWW.163.COM')
------------------------------------------------------------------------------------------------------------------------------------------------------
<a href="www.163.com">常见SQL访问索引的方式</a>
从上面的例子可以看得出来这几个支持正则表达式的函数是十分强大的,合理的加以使用一定会使你写出的SQL更加简单高效。
常用正则表达式大全!(例如:匹配中文、匹配html)
匹配中文字符的正则表达式: [u4e00-u9fa5]
评注:匹配中文还真是个头疼的事,有了这个表达式就好办了
匹配双字节字符(包括汉字在内):[^x00-xff]
评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
匹配空白行的正则表达式:ns*r
评注:可以用来删除空白行
匹配HTML标记的正则表达式:<(S*?)[^>]*>.*?|<.*? />
评注:网上流传的版本太糟糕,上面这个也仅仅能匹配部分,对于复杂的嵌套标记依旧无能为力
匹配首尾空白字符的正则表达式:^s*|s*$
评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式
匹配Email地址的正则表达式:w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*
评注:表单验证时很实用
匹配网址URL的正则表达式:[a-zA-z]+://[^s]*
评注:网上流传的版本功能很有限,上面这个基本可以满足需求
匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
评注:表单验证时很实用
匹配国内电话号码:d{3}-d{8}|d{4}-d{7}
评注:匹配形式如 0511-4405222 或 021-87888822
匹配腾讯QQ号:[1-9][0-9]{4,}
评注:腾讯QQ号从10000开始
匹配中国邮政编码:[1-9]d{5}(?!d)
评注:中国邮政编码为6位数字
匹配身份证:d{15}|d{18}
评注:中国的身份证为15位或18位
匹配ip地址:d+.d+.d+.d+
评注:提取ip地址时有用
匹配特定数字:
^[1-9]d*$ //匹配正整数
^-[1-9]d*$ //匹配负整数
^-?[1-9]d*$ //匹配整数
^[1-9]d*|0$ //匹配非负整数(正整数 + 0)
^-[1-9]d*|0$ //匹配非正整数(负整数 + 0)
^[1-9]d*.d*|0.d*[1-9]d*$ //匹配正浮点数
^-([1-9]d*.d*|0.d*[1-9]d*)$ //匹配负浮点数
^-?([1-9]d*.d*|0.d*[1-9]d*|0?.0+|0)$ //匹配浮点数
^[1-9]d*.d*|0.d*[1-9]d*|0?.0+|0$ //匹配非负浮点数(正浮点数 + 0)
^(-([1-9]d*.d*|0.d*[1-9]d*))|0?.0+|0$ //匹配非正浮点数(负浮点数 + 0)
评注:处理大量数据时有用,具体应用时注意修正
匹配特定字符串:
^[A-Za-z]+$ //匹配由26个英文字母组成的字符串
^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串
^[a-z]+$ //匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串
^w+$ //匹配由数字、26个英文字母或者下划线组成的字符串
在使用RegularExpressionValidator验证控件时的验证功能及其验证表达式介绍如下:
只能输入数字:“^[0-9]*$”
只能输入n位的数字:“^d{n}$”
只能输入至少n位数字:“^d{n,}$”
只能输入m-n位的数字:“^d{m,n}$”
只能输入零和非零开头的数字:“^(0|[1-9][0-9]*)$”
只能输入有两位小数的正实数:“^[0-9]+(.[0-9]{2})?$”
只能输入有1-3位小数的正实数:“^[0-9]+(.[0-9]{1,3})?$”
只能输入非零的正整数:“^+?[1-9][0-9]*$”
只能输入非零的负整数:“^-[1-9][0-9]*$”
只能输入长度为3的字符:“^.{3}$”
只能输入由26个英文字母组成的字符串:“^[A-Za-z]+$”
只能输入由26个大写英文字母组成的字符串:“^[A-Z]+$”
只能输入由26个小写英文字母组成的字符串:“^[a-z]+$”
只能输入由数字和26个英文字母组成的字符串:“^[A-Za-z0-9]+$”
只能输入由数字、26个英文字母或者下划线组成的字符串:“^w+$”
验证用户密码:“^[a-zA-Z]w{5,17}$”正确格式为:以字母开头,长度在6-18之间,
只能包含字符、数字和下划线。
验证是否含有^%&'',;=?$"等字符:“[^%&'',;=?$x22]+”
只能输入汉字:“^[u4e00-u9fa5],{0,}$”
验证Email地址:“^w+[-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*$”
验证InternetURL:“^http://([w-]+.)+[w-]+(/[w-./?%&=]*)?$”
验证电话号码:“^((d{3,4})|d{3,4}-)?d{7,8}$”
正确格式为:“XXXX-XXXXXXX”,“XXXX-XXXXXXXX”,“XXX-XXXXXXX”,
“XXX-XXXXXXXX”,“XXXXXXX”,“XXXXXXXX”。
验证身份证号(15位或18位数字):“^d{15}|d{}18$”
验证一年的12个月:“^(0?[1-9]|1[0-2])$”正确格式为:“01”-“09”和“1”“12”
验证一个月的31天:“^((0?[1-9])|((1|2)[0-9])|30|31)$”
正确格式为:“01”“09”和“1”“31”。
匹配中文字符的正则表达式: [u4e00-u9fa5]
匹配双字节字符(包括汉字在内):[^x00-xff]
匹配空行的正则表达式:n[s| ]*r
匹配HTML标记的正则表达式:/<(.*)>.*|<(.*) />/
匹配首尾空格的正则表达式:(^s*)|(s*$)
匹配Email地址的正则表达式:w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*
匹配网址URL的正则表达式:http://([w-]+.)+[w-]+(/[w- ./?%&=]*)?
(1)应用:计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
String.prototype.len=function(){return this.replace([^x00-xff]/g,"aa").length;}
(2)应用:javascript中没有像vbscript那样的trim函数,我们就可以利用这个表达式来实现
String.prototype.trim = function()
{
return this.replace(/(^s*)|(s*$)/g, "");
}
(3)应用:利用正则表达式分解和转换IP地址
function IP2V(ip) //IP地址转换成对应数值
{
re=/(d+).(d+).(d+).(d+)/g //匹配IP地址的正则表达式
if(re.test(ip))
{
return RegExp.$1*Math.pow(255,3))+RegExp.$2*Math.pow(255,2))+RegExp.$3*255+RegExp.$4*1
}
else
{
throw new Error("Not a valid IP address!")
}
}
(4)应用:从URL地址中提取文件名的javascript程序
s="http://www.9499.net/page1.htm";
s=s.replace(/(.*/){0,}([^.]+).*/ig,"$2") ;//Page1.htm
(5)应用:利用正则表达式限制网页表单里的文本框输入内容
用正则表达式限制只能输入中文:onkeyup="value=value.replace(/[^u4E00-u9FA5]/g,'') "onbeforepaste="clipboardData.setData(''text'',clipboardData.getData(''text'').replace(/[^u4E00-u9FA5]/g,''))"
用正则表达式限制只能输入全角字符: onkeyup="value=value.replace(/[^uFF00-uFFFF]/g,'') "onbeforepaste="clipboardData.setData(''text'',clipboardData.getData(''text'').replace(/[^uFF00-uFFFF]/g,''))"
用正则表达式限制只能输入数字:onkeyup="value=value.replace(/[^d]/g,'') "onbeforepaste= "clipboardData.setData(''text'',clipboardData.getData(''text'').replace(/[^d]/g,''))"
用正则表达式限制只能输入数字和英文:onkeyup="value=value.replace(/[W]/g,'') "onbeforepaste="clipboardData.setData(''text'',clipboardData.getData(''text'').replace(/[^d]/g,''