android4.0.1 webkit dom tree 创建过程分析
文档对象模型是独立于平台和语言的一套编程接口,允许程序和脚本动态的访问和更新文档的内容,结构和样式。
文档可以被进一步的处理,处理的结果可以与当前页面交互。
W3C 发布 DOM 规范,所有的浏览器都执行了这个标准。
DOM实际上是以面向对象方式描述的文档模型。DOM定义了表示和修改文档所需的对象、这些对象的行为和属性以及这些对象之间的关系。
webkit解析网络上取到的主资源(text/html)生成DOM tree的过程是依据规范(http://www.whatwg.org/specs/web-apps/current-work/multipage/parsing.html)实现的。
在生成DOM Tree的过程也会同时建立Render Tree,以下是与DOM Tree创建相关的主要类的类图。
DOMTree创建的类图:
类图下载地址
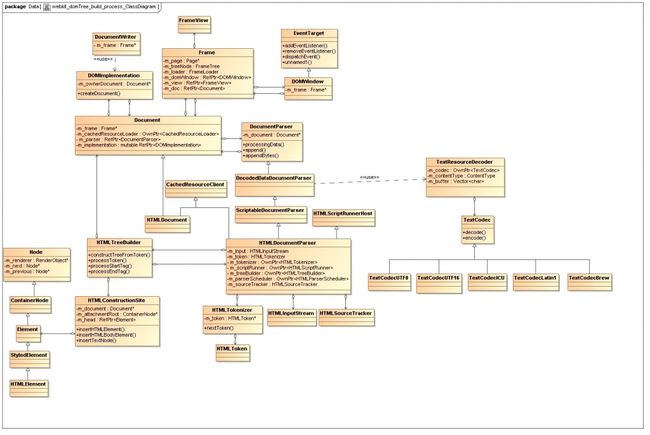
HTMLDocumentParser封装了创建DOM tree要用到的主要类。
HTMLInputStream 存放网络上取到的原始数据。
HTMLTokenizer将原始数据分成HTMLToken.
HTMLSourceTracker用于跟踪原始数据的当前位置。
HTMLTreeBuilder利用HTMLToken创建DOM树。具体的创建过程通过调用类HTMLConstructionSite的接口完成。
二.DOM Tree的创建过程如下:
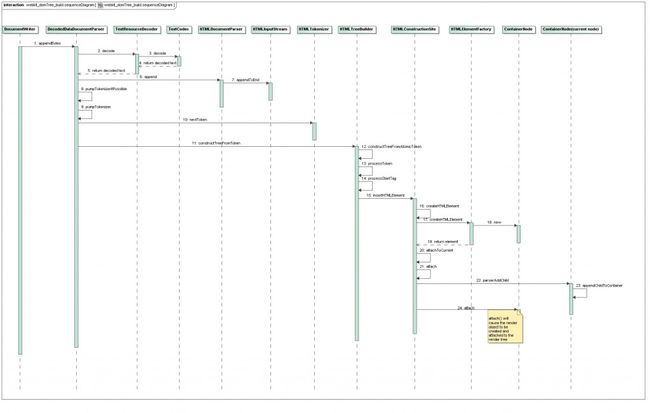
1.得到主资源(text/html)。DocumentLoader将主资源传给DocumentWriter,DocumentWriter最终将数据传给了DecodedDataDocumentParser。
2.将主资源解码为Unicode字符。从网络上取到的主资源数据是原始的字符数据经过特定的字符编码形成的字节流,
在交给Tokenizer进一步处理之前,需要先将编码后的字节流解码成原始的字符(Unicode code point)。
这项工作是由DecodedDataDocumentParser在appendBytes()函数中通过调用TextResourceDecoder类的具体字符解码器完成的。解码后的字符数据保存在类HTMLInputStream的实例中。
在创建DOM Tree的过程中可能会执行脚本document.write(),这会改变文档的结构,所以HTMLInputStream需要提供这样的接口工HTMLDocuemntParser调用来临时增加Document内容。InsertionPointRecord用来记录通过Document.write()增加的内容在HTMLInputStream中的插入信息。
3. 将解码后的主资源分割为HTMLToken。HTMLTokenizer负责将HTMLInputStream中的数据分割成HTMLToken。
HTMLToken 可以看作是html文档的基本组成单位。有以下几种类型:
enum Type {
Uninitialized,
DOCTYPE,
StartTag,
EndTag,
Comment,
Character,
EndOfFile,
};
DOCTYPE 对应 html 文档中的 <!DOCTYPE HTML>
StartTag对应 html 文档中的 <head> <body> 等。
Comment , Character对应html 标签之间的字符内容。
4.创建DOMTree及RenderTree。HTMLTreeBuilder利用HTMLToken来创建DOM tree的过程。
HTMLTreeBuilder提供了私有的方法来处理不同类型的HTMLToken.
void processDoctypeToken(AtomicHTMLToken&);
void processStartTag(AtomicHTMLToken&);
void processEndTag(AtomicHTMLToken&);
void processComment(AtomicHTMLToken&);
void processCharacter(AtomicHTMLToken&);
void processEndOfFile(AtomicHTMLToken&);
InsertionMode 是一个状态变量,用来控制DOM Tree创建过程的主要操作。InsertionMode指明了当前处理的HTMLToken的相对位置信息,
因而会影响HTMLToken的处理过程。
比如在调用processStartTag()处理StartTag类型的HTMLToken时,如果当前的InsertionMode是InTableMode,则表明当前的Start标签处在Table元素中,对这个标签的进一步处理会通过调用processStartTagForInTable()进行。InsertionMode的值为“before html”时,会创建 html 的 root element node. 这个node 被压入栈HTMLConstructionSite::m_openElements.
HTMLTreeBuilder对HTMLToken的处理最终会调用HTMLConstructionSite的insertxxxxElement,并改变InsertionMode的值。
HTMLConstructionSite会根据HTMLToken创建HTMLElement从而创建node及containernode,新创建的node会与当前的node创建关联,也就是新创建的node被插入到已创建的DOMTree。这个过程是通过HTMLConstructionSite的attach函数调用当前Node的parserAddChild()完成的,containerNode调用模板函数appendChildToContainer建立新建Node与当前Node的关联。
当HTML Document的所有HTMLToken代表的Node都建立起关联时,DOM Tree就建成了。
DOM Tree创建的顺序图:
顺序图下载地址