使用七 (试用Counter Monitor )
简述:
试用VTune的CounterMonitor
仍然使用之前的gzip.exe做测试, 收集Counter Monitor 的到的数据结果
步骤:
1. 创建新的Activity, 选择Counter Monitor Wizard
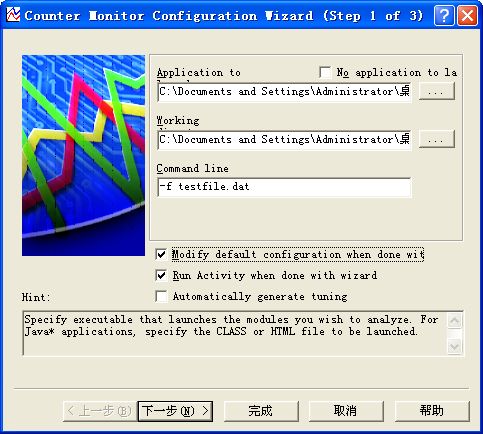
2.打开gzip.exe文件,同时在Command line arguments 的文本框中打入参数 -f testfile.dat
同时勾选中Modify default configuration when done whith wizard checkbox
下一步, 下一步,至如下页面勾选中Collect Sampling ...
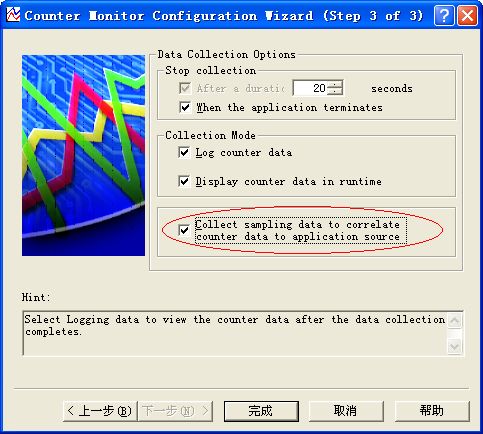
点击完成
3. 之后进入如下界面,勾选中Sampling
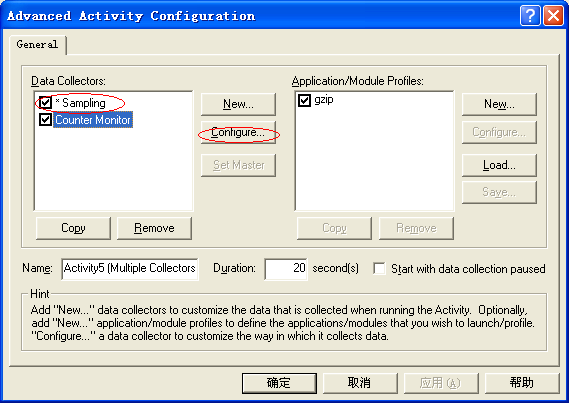
选中Sampling, 进入Sampling的 Configuration, 选中Dont't Calibrate ....
点击确定
选中Data Collectors 中的Counter Monitor, 点击Configuration进入
选中Performance Objects 中的LogicalDisk, 点击Add
选中C:
选中Disk Reads/sec , Disk Writes/sec
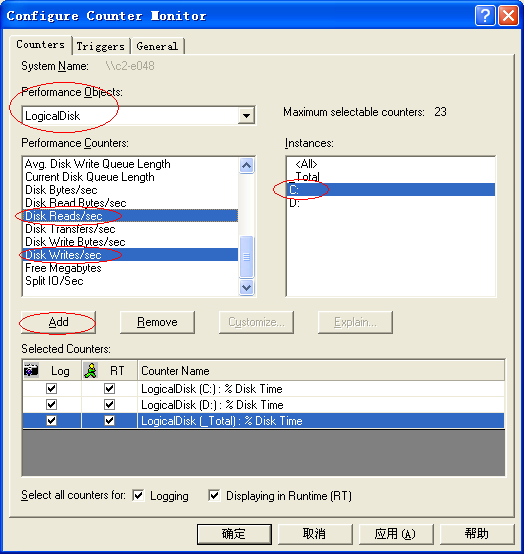
点击Add
最后只保留C:盘的部分
点击确定 --> 确定。
4. 测试结束后,出现如下小窗口
选中Counter Monitor Results --> View
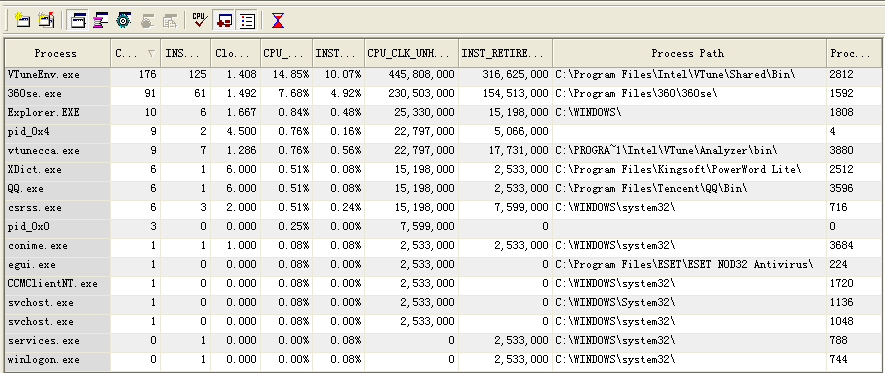
1) 得到系统Read的平均时间为 1.015 , 其中write远大于write的时间 可以看出这个程序是个以文件为主的
5. Counter Monitord Data相关的Sampling Data 事件取样
选中 Select Range to Zoom/Drill Down 图标
如下图 向右拖拉,
点击Drill Down to Correlate Sampling Data View icon

于是可以看到上面设定的时间段内的Sampling Data
1) 实验过程中发现VTune可以自己吧测试程序在指令层进行性能剖析,对于细化研究程序是很有用的。Vtune不仅对应用程序本身取样,还对应用程序中调用的系统库函数进行取样,还对用到的设备驱动进行取样
2) 对Intel 的VTune中Sampling是如何同硬件系统结合,的获取实验数据的感到好奇。
分析器收集的数据,
~ 在内存中的指令运行地址
~ 操作系统进程或线程ID
~ 在此地址装入的可执行模块
VTune使用(五 ~ 七) 实验回顾:
1)Sampling提供了在进程级别的开销的数据,在进程模块层查看数据,这是Call Graph没有的,具体两者功能如下,
/*********************************************************************************/
Call Graph 调用曲线图
通过分析程序运行时函数的入口点和出口点,生成一张调用图,并且确定调用顺序,显示关键路径。他显示线程创建,函数执行,以及他们之间的父子继承关系,分析关于程序流程的示意图,帮助开发者快速识别主要功能和调用顺序。主要包含如下几个部分,
~ 程序函数级的框架结构
~ 某个函数被某特定区域调用的次数
~ 每个函数消耗的时间
~ 处于关键路径上的函数
Sampling 取样功能
可以帮助开发者分辨程序中最消耗时间的函数和模块,并给出操作系统和应用程序详细视图,它能够寻找到程序中的热点区域,最好时间的模块、函数、代码行和汇编指令,并提供进程、线程、模块、函数以及代码等不同层次的各种视图,并在表格内将具体参数列出。主要功能内容如下,
~ 通过统计的方法来找到Hotspots
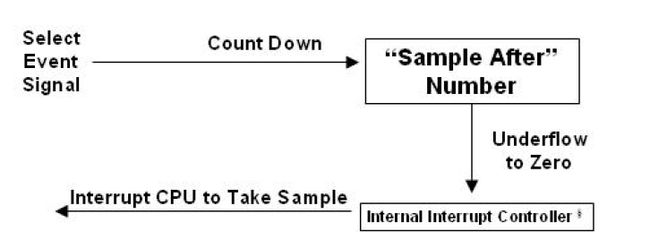
~ Sampling收集器周期性的中断处理器以获取可执行的程序信息
~ 采样的两种方式:基于时刻的采样(TBS)由操作系统定时服务和每n个处理器时钟点触发;基于事件的采样 (EBS)由指处理器相关事件,如:L2级缓存遗失、分支误预测、浮点指令过时(retired)等等事件所触发。
/*********************************************************************************/
对于LINPACK这个程序,应当参考Call Graph 中体现的在daxpy 函数上开销较大,应该主要优化这个函数
2)因为CPU可能被非测试程序使用,导致测试程序的结果不准确,素以在Sampling Data之前要看一下在Counter Monitor中CPU的使用率
3)Sampling 和 call graph 两者开销不大,通常设定为1000,这样使得取样完整性和取样开销之间做权衡,其中取样产生的时间开销不到1%, 切对指令无要求,不必为取样而对程序代码做任何改动。
4)Sampling根据一些系统Event或钟点触发来得到数据结果,更趋向于体现系统层面的性能, Call Graph主要是基于函数调用,在函数层面的分析,是基于程序内部函数调用