Google机器翻译分析
由 www.lucene.com.cn 提供 史洪柏 葛帅
2008奥运会,全球目光聚焦北京,必将中文与其它语言的机器翻译市场也将有很大的发展, 在Google有一个在线翻译服务,网址为: http://translate.google.com/translate_t ,目前针对中文仅有中->英 ,英->中的文本翻译和网页翻译服务,就意味在不能满足其它国家众多语言用户的需求,该领域目前还存在新商业商业模式和机会。
测试原文:
My sincere thanks to Owen Astrachan whose valuable comments helped to improve this text. I am grateful to all the visitors of my web site and to my students who commented on "Pascal and C++ Side by Side."
测试译文:
衷心感谢欧文astrachan的宝贵意见帮助改善这个文本. 我要感谢所有的观众对我和我的同学网站评论"、帕斯卡尔 C++中并肩. "
结果在上面,不用多说,还不是很好,希望Baidu推出该类产品能有所突破。
-----------------------------------------------------------------------------------------------------------------------------
有兴趣可以了解一下机器翻译的相关算法:
1. 机器翻译的介绍
(1) 基于规则的机器翻译(Rule-based Machine Transltion)
原理:目前一般采用转换文法的方法,先根据原语言的语法规则分析原语言,生成语法树;根据转换规则将其转换成目标语言的语法树,然后根据译文的生成规则生成译文。
特点:灵活,适应性强,但产生的译文质量一般。由于自然语言中存在着大量的例外情况,当规则库比较庞大的时候可能产生很多冲突。规则的调试需要专家知识,非常耗时,并且很难保证修改后的规则不会带来新的冲突。
(2) 基于实例的机器翻译(Example-based Machine Translation)
原理:基于实例的机器翻译的本质是通过类比来获得翻译的结果。给出一系列的汉语对应的源语言和目标语言的语句,将同源语言句子的类似的句子翻译成目标语言。基于实例的机器翻译的假定是:如果一个已经翻译过的语句再次出现,那么它的上一次的翻译结果非常可能也正确。
特点:适用范围窄(受双语语料库规模,题材的限制),如果能匹配成功则译文准确率极高,翻译速度快。对于翻译产品说明书的不同版本能取得很好的效果。
(3) 基于规则和语料库相结合的机器翻译(Hybrid Method)
以Rule_Based Machine Translation为基础,利用从语料库获得的统计信息进行消歧,利用统计的信息和树库做基于统计Parser。
2. 传统的EBMT采用的方法
语句匹配问题:精度匹配和模糊匹配
精度匹配:准确率极高,但是匹配率比较低。译文的质量有保障。
模糊匹配:特点是准确率比较高,匹配率比较好;但是如何根据匹配成功的目标语言的语句来产生译文仍然是一个棘手的问题,可能需要一定程度的深层分析。随着模糊匹配算法的不同,相应的译文生成的策略也不同。
3. Generalized EBMT的介绍
Gereralization:将语句中的某些词语或短语用更一般的概念来表示。可以很大程度上减少对实例库规模的需求。
泛化采用的基本方法:
-通过对大规模语料的训练进行word cluster 来自动的对实例进行一般化
-利用现有的语义词典计算词语的上下位来自动的对实例进行一般化
举例说明:
-{English} John Hancock was in Philadelphia on July 4
-{German} John hancock war am 4.juli in Philadelphia.
-{English} <PERSON> was in <CITY> on <DATE>
-{German} <PERSON> war am <DATE> in <CITY>
CMU 的tokenization: 利用一个特殊的词表来查找,并且用了一些简单的规则,根据他们的研究,如果双语语料库的规模能够达到百万数量对语句,对非限定领域的输入就能够达到比较好的覆盖。基于语法树库进行的工作,半自动标注词类。
4.研究内容
本文通过汉语和英语的语义词典来计算词的语义距离,进而计算语句的结构相似度,然后将相似语句的共同部分提取出来做为模板 的候选元素。汉语和英语的语义词典分别是基于 wordnet和同义词词林。由于对自然语言的完全分析尚未达到很好的程度,本文试图不对语言进行完全分析,直接从语料库获取翻译模板,所用的方法基本和语言无关。
4.1词的语义距离的计算和上位词的获取
采用语义词典,根据词的上下位来确定词的语义距离英语采用<wordnet>汉语采用<同义词词林>
4.2语句结构相似度的计算
假设语句A和语句B分别有m和n 个词,他们的词相似度矩阵为:
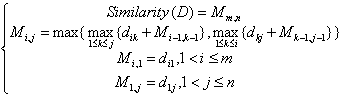
dij为语句A的第i个词和语句B的第j个词的语义距离,根据此相似矩阵,我们可以计算两个语句之间的相似度并且能够提取他们的共同部分作为模板的侯选元素。计算方法如下(采用动态规划)
4.3模板的提取
一个翻译模板对应于一个分句或是短语,目前并不考虑模板的嵌套问题。计算得到语句相似度之后,将对相似度有贡献的“词对”作为两个语句的相似
部分提取出来并结合语义词典得到template candidates
将两个语句的相似的部分提取出之后,取得他们的上位词,作为最初的模板
5.研究的意义
在保证翻译准确率的前提下提高了系统的匹配率,使更多的相似语句可以匹配。翻译速度有了很大程度的提高,同时翻译结果的重复利用性良好,模板的可读性较好。实例库的组织更加有条理,层次清晰,有利于扩充和检索。