Red Hat Enterprise Linux 4: 系統管理
| Red Hat Enterprise Linux 4: 系統管理導論 | ||
|---|---|---|
| 前頁 | 第 2章. 監控資源 | 下頁 |
2.5. Red Hat Enterprise Linux 的特定資訊
Red Hat Enterprise Linux 內附非常多種資源監控工具。以功能而言,底下這些工具都是個中翹楚;但您可選用的工具遠多於此。這些工具包括了:
-
free
-
top (以及 GNOME 系統監控:圖形版本的top)
-
vmstat
-
Sysstat 資源監控工具組
-
OProfile 系統全域剖析工具
現在我們就來一一檢視這些工具。
2.5.1. free
free 指令顯示了系統記憶體的使用率。底下是執行後的例子:
total used free shared buffers cached |
Mem: 那一行顯示了實際記憶體的使用率;Swap: 顯示的是系統 swap 空間的使用率;而 -/+ buffers/cache: 則是目前撥給系統緩衝區的實體記憶體數量。
因為 free 指令預設上只會顯示一次記憶體使用率,所以對於短期的監控,或看看目前記憶體是不是有問題很有幫助。雖然您可以在 free 指令後加上 -s 選項,連續顯示記憶體使用率;但畫面會一直往上捲,讓人不容易看清每次的變化為何。
| 提示 | |||
|---|---|---|---|
| 與其使用 free -s,您不妨結合 watch 與 free 指令。舉例來說,要系統每兩秒(watch 指令的預設值)顯示一次記憶體用量,請執行以下指令:
watch 指令會每兩秒執行 free 一次,執行前會清除螢幕,在同樣位置列印資料。因為 watch 指令不會捲動螢幕,所以很容易看出長時間的記憶體使用率。您可以使用 -n 選項,控制執行的頻率;您也可以利用 -d 選項,讓程式將每次不同的地方標示出來。執行範例如下:
欲知更多詳情,請參閱 watch man page。 watch 指令會一直執行,直到您按下 [Ctrl] - [C] 為止。您不妨把 watch 指令記下來,它在很多時候都很有用。 |
2.5.2. top
free 指令只會顯示記憶體相關的訊息,top 指令則每樣東西都沾上點邊。CPU 使用率、程序的統計資料、記憶體使用率 — top 全部一網打盡。除此之外,跟 free 不同的是,top 預設上就是不斷的執行,您不需要搭配 watch 使用。以下是使用範例:
14:06:32 up 4 days, 21:20, 4 users, load average: 0.00, 0.00, 0.00 |
這畫面分成兩個部份。上半部包括了系統的整體狀態 — 迄今的開機時間、平均負載、程序的數量、CPU 狀態、記憶體與 swap 空間的使用資料。下半部則顯示了程序等級的統計資訊。您可以在 top 執行期間變更顯示畫面。例如 top 預設上會顯示所有執行與非執行中的程序,如果您只想看執行中的程序,請按下 [i] 鍵;再按一次可以讓您回到預設的顯示模式。
| 警告 | |
|---|---|
| 雖然從畫面上看起來,top 是個再陽春不過的程式;但千萬別讓它的外表給騙了,您可以用單鍵的指令來操作 top。舉例來說,如果您以 root 身份登入,您就可以用這程式改變系統上任何程序的優先順序,甚至直接刪除程序。因此,除非您已經詳讀了 top 指令的說明畫面(要顯示說明畫面,請按 [?] 鍵),否則建議您除了 [q] (結束 top)按鍵以外,什麼都不要按。 |
2.5.2.1. GNOME 系統監控 — 圖形化的 top
如果您比較習慣圖形化介面,那麼您一定會喜歡 GNOME 系統監控。GNOME 系統監控 跟 top 很像,會顯示系統的整體狀態、程序的數量、記憶體與 swap 使用率、以及程序方面的統計數據。
然而,GNOME 系統監控 更進一步,使用圖形化方式顯示 CPU、記憶體、以及 swap 空間的使用率,並以柱狀圖列出所有的磁碟空間使用率。圖形 2-1 是 GNOME 系統監控 程序清單 的範例。
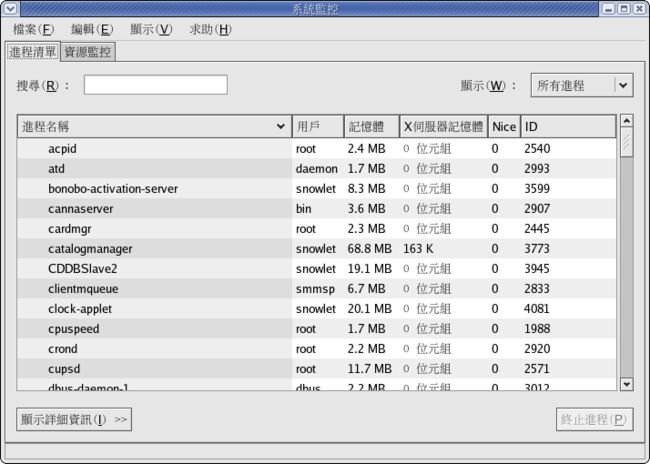
圖形 2-1. GNOME 系統監控 程序清單 的畫面
您可以先點選其中一個程序,再按下下方的顯示詳細資訊按鈕,以得到該程序更進一步的資訊。
要顯示 CPU、記憶體、以及磁碟使用率的統計資訊,請按下 系統監控 標籤。
2.5.3. vmstat
如果您想對系統效能有個初步的了解,不妨試試 vmstat 指令,它以一行數據簡明扼要地列出程序、記憶體、swap 空間、I/O、系統、以及處理器等相關動作的資訊。
procs memory swap io system cpu |
第一行將所有欄位分成六大類,包括程序、記憶體、swap 空間、I/O、系統、以及處理器等相關的統計數據。第二行則進一步顯示各種細部資訊,讓您快速地瀏覽所需資訊。
與程序有關的欄位包括:
-
r — 等著存取處理器的可執行程序之數量
-
b — 處於不可執行睡眠狀態下的程序數目
與記憶體相關的欄位包括:
-
swpd — 已使用的虛擬記憶體大小
-
free — 未使用的記憶體大小
-
buff — 用來當作緩衝區的記憶體大小
-
cache — 用來當作分頁快取的記憶體大小
與 swap 有關的欄位包括:
-
si — 從磁碟讀入,置換到記憶體的資料大小
-
so — 從記憶體置換到磁碟的資料大小
與 I/O 有關的欄位包括:
-
bi — 送到區塊(block)裝置的區塊數目
-
bo — 從區塊裝置讀入的區塊數目
與系統相關的欄位包括:
-
in — 每秒的中斷數目
-
cs — 每秒的環境切換(context switch)數目
與 CPU 相關的欄位包括:
-
us — CPU 處理使用者等級程式碼的時間,以百分比表示
-
sy — CPU 處理系統等級程式碼的時間,以百分比表示
-
id — CPU 的閒置時間,以百分比表示
-
wa — I/O 等待
如果您不加任何選項,那麼 vmstat 只會顯示一行,包括系統開機以來的平均值。
不過大部分系統管理者不會倚靠這行資料來做分析,因為每次擷取的資料會隨著時間而不同。因此,大部分管理者都會使用 vmstat 的重複執行功能,設定一定的間隔擷取資訊。例如 vmstat 1 會每隔一秒鐘顯示一行資訊;而 vmstat 1 10 會每隔一秒顯示一行,但只會持續十秒。
只要有 vmstat 在手,有經驗的管理者可以馬上找出系統使用率與效能問題的關鍵。但是要更深一步,就需要另一個工具 — 能深入搜集並分析資料的工具。
2.5.4. Sysstate 資源監控工具組
在很短的時間之內,之前所提到的工具能提綱挈領地,讓您一窺系統的效能資訊;但除了提供某個時點的資源使用率之外,就沒有太大用處。除此之外,這些簡單的工具有時也有力有未逮的時候。
因此,我們需要更複雜的工具。Sysstat 正符合所需。
Sysstat 包括以下搜集 I/O 與 CPU 統計資料的工具:
- iostat
-
顯示 CPU 使用率的概要,以及一或多台磁碟機的 I/O 統計數據。
- mpstat
-
顯示更深入的 CPU 統計資料。
Sysstat 也包含搜集系統資源使用率資料、以及利用這些資料建立日報表的工具。這些工具包括:
- sadc
-
sadc 是系統活動資料搜集程式(system activity data collector)的縮寫,能將系統資源使用率的資料搜集後寫到檔案中。
- sar
-
sar 會利用 sadc 所建立的檔案,以互動式的方式製作報表、或寫入檔案以供更深入的分析。
底下章節將更詳細地探討每一項工具。
2.5.4.1. iostat 指令
基本上,iostat 指令大致提供了 CPU 與磁碟 I/O 的統計資訊:
Linux 2.4.20-1.1931.2.231.2.10.ent (pigdog.example.com) 07/11/2003 |
在第一行(包括系統核心的版本、主機名稱、以及目前日期)之下,iostat 顯示了開機以來,系統平均 CPU 使用率的簡明資訊,其中包括以下百分比數字:
-
使用者模式所花的時間(執行應用程式等等)。
-
使用者模式所花的時間(曾經使用 nice(2) 指令改變既定優先權限的程序)
-
核心模式所用的時間
-
處理器的閒置時間
在 CPU 使用率報表之下,是裝置的使用率報表。其中每個磁碟裝置一行,包括以下資訊:
-
裝置名稱,以 dev<major-number>-sequence-number格式顯示,其中 <major-number> 是裝置的主要號碼[1];而 <sequence-number> 則是從零開始的流水號
-
每秒的傳輸(或 I/O 操作)數目
-
每秒讀取的 512 位元區塊數
-
每秒寫入的 512 位元區塊數
-
512 位元區塊的讀取總數
-
512 位元區塊的寫入總數
這只是 iostat 指令的範例。如欲了解更多資訊,請參閱 iostat 的 man page。
2.5.4.2. mpstat 指令
mpstat 指令的執行結果跟 iostat 的 CPU 使用率報表沒什麼分別。
Linux 2.4.20-1.1931.2.231.2.10.ent (pigdog.example.com) 07/11/2003 |
除了多一欄顯示 CPU 每秒處理的中斷外,實質上沒有什麼差異。然而,如果您為 mpstat 加上 -P ALL 選項後,那就有很大的不同:
Linux 2.4.20-1.1931.2.231.2.10.ent (pigdog.example.com) 07/11/2003 |
在多處理器系統上,mpstat 指令能個別顯示每個 CPU 的資訊,讓您比較每個處理器的效能為何。
2.5.4.3. sadc 指令
如之前所述,sadc 指令會搜集系統使用率的資訊,寫進檔案中以供將來分析用。預設上,這資料會寫到 /var/log/sa/ 目錄中,命名為sa<dd>。其中 <dd> 是目前日期的二位數字。
sadc 通常都由 sal 這個 script 來執行;而這 script 又由 cron 定期透過位於 /etc/cron.d/ 目錄中的 sysstat 檔案運作。sal 會以為期一秒的時間,執行 sadc。預設上,cron 會每十分鐘執行 sal 一次,然後定期寫到 /var/log/sa/sa<dd> 檔案中。
2.5.4.4. sar 指令
sar 指令會根據 sadc 所蒐集的資料來產生系統使用率報表。根據 Red Hat Enterprise Linux 的設定,sar 會自動執行,以處理由 sadc 而來的檔案。這些報告檔案會寫到 /var/log/sa/ 目錄中,命名為 sar<dd>;其中 <dd> 是一組二位數字,表示前一天的日期。
sar 多半由 sa2 這個 script 所執行,後者會定期由 cron 執行位於 /etc/cron.d 目錄中的 sysstat。預設上 cron 會在每天晚上 11 點 53 分時,執行 sa2,以利用當天的所有資料製作報表。
2.5.4.4.1. 解讀 sar 報表
根據 Red Hat Enterprise Linux 預設的設定,sar 報表包括了幾個段落,每個段落都包括了特定類型的資料,依照資料搜集的時間排列。由於 sadc 會每隔十分鐘執行一秒,所以 sar 報表預設上會以十分鐘為單位,列出 00:00 到 23:50 之間的資料[2]。
這報表每一節開始的地方,都有標題描述包含於本節的資料。這標題會在每節中以固定的時間間隔重複,讓您閱讀報表時,能更輕易地解讀資料。每一節的最後一行,都包含了該節的平均資料。
底下是 sar 報表的範例。為了節省空間,00:30 到 23:40 的資料都已經被移除:
00:00:01 CPU %user %nice %system %idle |
本節顯示的是 CPU 的使用率資訊,跟 iostat 所顯示的資料非常類似。
其他部份可能包含同一時間內,值得研究的資訊;這些資訊散佈在多行中。例如底下是從雙 CPU 電腦搜集到的資訊:
00:00:01 CPU %user %nice %system %idle |
根據預設值,Red Hat Enterprise Linux 中的 sar 指令共有十七個不同的段落;有些將在之後的章節中為您介紹。如要了解所有段落中的資料,請參閱 sar(1) 的 man page。
2.5.5. OProfile
OProfile 系統全域剖析工具(profiler)是個不太耗費系統資源的監控工具。OProfile 利用了處理器的效能監控硬體[3]來找出與效能相關的問題本質。
效能監控硬體是處理器內建的功能之一,作法是用一個特別的計數器,每當有某個特殊事件(例如處理器不再閒置、或所需要的資料不在快取中)發生時,就會加一。有些處理器擁有不只一個這種計數器,讓使用者紀錄多種不同的事件。
您可以為這計數器載入一個初始值,當計數器溢位時,它會發出一個中斷訊號。將不同的值填入這計數器,就可以改變中斷產生的頻率。這樣就可以控制採樣頻率,進一步設定資料搜集的詳細程度。
一 方面,您可以為每個事件產生中斷,讓這計數器溢位,以搜集到最詳盡的資料(但系統負荷會很重)。另一方面,您可以設定這計數器,讓它不常產生中斷,只對系 統效能搜集一般性的資料(這樣幾乎不會對系統產生任何負荷)。有效監控系統的秘訣在於如何選擇您的採樣頻率,一方面要高到足以搜集到需要的資訊,另一方面 又不要太高以免加重系統的負荷。
| 警告 | |
|---|---|
| 您可以設定 OProfile,讓它產生的負荷足夠讓系統無法處理正常事務。因此,在您選擇計數器的值時,一定要小心謹慎。也因此,opcontrol 指令的 --list-events 選項能為目前的處理器顯示可用的事件種類,以及每個種類的最小建議值。 |
記得使用 OProfile時,您得在採樣頻率與系統負荷間取得平衡,魚與熊掌是不能兼得的。
2.5.5.1. OProfile 元件
Oprofile 包括了以下元件:
-
資料搜集軟體
-
資料分析軟體
-
管理介面的軟體
資料搜集軟體包括 oprofile.o 核心模組,以及 oprofiled daemon。
資料分析軟體包括:
- op_time
-
為每個執行檔所做的採樣頻率,以數目與相對百分比顯示
- oprofpp
-
由函數、獨立指令、或使用 gprof 格式所採取的樣本,以數目或百分比顯示
- op_to_source
-
顯示已註釋的原始碼與(或)組合清單
- op_visualise
-
用圖形化方式顯示搜集來的資料
這些程式能以多樣化的方式,顯示搜集而來的資料。
管理介面軟體控制了所有資料搜集方面的事情,從指定要監控哪些事件,到搜集開始與結束等等。這些工作都以 opcontrol 指令來操作。
2.5.5.2. OProfile 的使用範例
本節將為您示範 OProfile 從開始設定,到最後的資料分析的過程。這只是個初步的簡介,欲知更多資訊,請參閱《Red Hat Enterprise Linux 系統管理手冊》。
請用 opcontrol 設定欲搜集的資料類型,指令如下:
opcontrol / |
在這裡所用的選項會將 opcontrol 導向到:
-
將 OProfile 導向到目前執行核心的複本(--vmlinux=/boot/vmlinux-`uname -r`)
-
指明使用處理器的第零個計數器,CPU 執行指令時做監控的動作(--ctr0-event=CPU_CLK_UNHALTED)
-
指明 OProfile 每 6,000 個時段,就針對特定的事件採樣一次(--ctr0-count=6000)
接下來,使用 lsmod 指令檢查 oprofile 核心模組是否已經載入:
Module Size Used by Not tainted |
用 ls /dev/oprofile/ 指令,檢查 OProfile 檔案系統(位於 /dev/oprofile/)是否已經掛載:
0 buffer buffer_watershed cpu_type enable stats |
(實際的檔案數目會根據處理器種類而有所不同。)
做到這一步,/root/.oprofile/daemonrc 檔案包含了資料搜集軟體所需的設定:
CTR_EVENT[0]=CPU_CLK_UNHALTED |
接下來,執行 opcontrol --start 指令,實際開始資料搜集動作:
Using log file /var/lib/oprofile/oprofiled.log |
用 ps x | grep -i oprofiled 指令檢查 oprofiled daemon 是否正在執行中:
32019 ? S 0:00 /usr/bin/oprofiled --separate-lib-samples=0 … |
(用 ps 指令顯示的 oprofiled 遠長於此;但為了格式問題,畫面已經被裁切過。)
現在您已經開始監控系統,對系統上所有執行檔進行資料的搜集。所有資料都儲存在 /var/lib/oprofile/samples/ 目錄中;不過檔案的命名方式都非常獨特。底下是一個範例:
}usr}bin}less#0 |
這命名方式使用每個包括可執行碼檔案的絕對路徑,以右大括弧(})取代斜線(/),緊跟著井字號(#),最後是一個號碼(本例為0)。因此,本例表示當 /usr/bin/less 正在執行時,系統正在搜集資料。
一旦資料搜集好,就可以用以下任一種分析工具來顯示。OProfile 有個很好的功能,就是在分析資料時,不用暫停搜集資料的動作。然而,您應該先等上一段時間,讓資料樣本寫進磁碟中;或使用opcontrol --dump 指令強迫程式把樣本寫到檔案中。
以底下的例子來說,op_time 用來顯示(反向顯示 — 從最高到最低)已搜集的樣本:
3321080 48.8021 0.0000 /boot/vmlinux-2.4.21-1.1931.2.349.2.2.entsmp |
要以互動方式產生報表,less 是個不錯的選擇,因為這報表通常多達數百行。也基於這個原因,您現在看到的範例只是實際情形的部份而已。
這特殊報表的格式,是每一行代表一個採樣的執行檔。每一行都遵循以下格式:
<sample-count> <sample-percent> <unused-field> <executable-name> |
其中:
-
<sample-count> 代表以搜集的樣本數
-
<sample-percent> 代表這個特別執行檔的採樣資料,以百分比表示
-
<unused-field> 是個沒有用到的欄位
-
<executable-name> 表示資料搜集的可執行檔檔名
這份報表(來自一臺大部分時間都在閒置的系統)顯示近半數的採樣都發生在 CPU 執行核心碼的時候。第二行是 OProfile 資料搜集 daemon,然後是許多函式庫與 X 視窗系統伺服器,XFree86。值得一提的是,計數器的值 6,000 是 opcontrol --list-events 推薦的最小值。這表示 — 至少在這部電腦上 — OProfile 的最高負載大約是 CPU 資源的 11%。
注
| [1] | 您可以在用 ls -l 指令,顯示 /dev/ 目錄裡面的檔案。主要號碼就是裝置群組規格後的那個數字。 |
| [2] | 由於系統的負載不同,資料搜集的時間也會有一兩秒的差異。 |
| [3] | 對於缺少效能監控硬體的電腦架構,OProfile 也可以使用先前的機制(稱為 TIMER_INT)來運作 |
| 前頁 | 內容 | 下頁 |
| 監控何種資源? | 上 | 額外資源 |