在Ubuntu 14.04 64bit上使用pycURL模块示例
PycURL 传说是实现Python下多线程网页抓取的效率最高的解决方案,本质是对libcurl C语言库的封装。
在Linux上有个常用的命令 curl(非常好用),支持curl的就是大名鼎鼎的libcurl库;libcurl是功能强大的,而且是非常高效的函数库。libcurl除了提供本身的C API之外,还有多达40种编程语言的Binding,这里介绍的PycURL就是libcurl的Python binding。
在Python中对网页进行GET/POST等请求,当需要考虑高性能的时候,libcurl是非常不错的选择,一般来说会比liburl、liburl2快不少,可能也会比Requests的效率更高。特别是使用PycURL的多并发请求时,更是效率很高的。个人感觉,其唯一的缺点是,由于是直接调用的是libcurl C库,PycURL的函数接口之类的还和C中的东西很像,可能不是那么的Pythonic,写代码的学习曲线稍微比liburl高一点儿。
https://github.com/pycurl/pycurl //pycurl模块的源码
搭建好sphinx环境之后,文档生成,直接从git源码下面运行,make docs
就会在build/doc中看到相关文档信息,进去之后,直接点击index.html进行查看
下面是我的几个实践示例
1.最简单的网页获取
#!/usr/bin/env python
#-*- coding: utf-8 -*-
import sys, pycurl, time, cStringIO
sys.stderr.write("pycURL version [%s]\n" % pycurl.version)
start_time = time.time()
url = 'http://www.dianping.com/shanghai'
b = cStringIO.StringIO()
c = pycurl.Curl()
c.setopt(c.URL, url)
c.setopt(c.WRITEFUNCTION, b.write)
c.perform()
end_time = time.time()
content = b.getvalue()
duration = end_time - start_time
print c.getinfo(pycurl.HTTP_CODE), c.getinfo(pycurl.EFFECTIVE_URL)
c.close()
print 'pycurl takes [%s] seconds to get [%s]' % (duration, url)
print 'length of the content is [%d]' % len(content)
2.简单的pycURL包装类
#!/usr/bin/env python
#encoding: utf-8
import sys, pycurl, cStringIO, urllib
class Curl:
def __init__(self):
self.c = pycurl.Curl()
def __del__(self):
self.c.close()
def init(self, verbose):
c = self.c;
c.setopt(c.FOLLOWLOCATION, 1)
c.setopt(c.MAXREDIRS, 5)
c.setopt(c.CONNECTTIMEOUT, 30)
c.setopt(c.TIMEOUT, 300)
c.setopt(c.NOSIGNAL, 1)
c.setopt(c.USERAGENT, "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36")
c.setopt(c.VERBOSE, verbose)
def get(self, url):
b = cStringIO.StringIO()
c = self.c;
c.setopt(c.URL, url)
c.setopt(c.WRITEFUNCTION, b.write)
c.perform()
content = b.getvalue()
print "HTTP CODE: ", c.getinfo(c.HTTP_CODE)
b.close()
return content
def post(self, url, data):
b = cStringIO.StringIO()
c = self.c;
c.setopt(c.POSTFIELDS, urllib.urlencode(data))
c.setopt(c.URL, url)
c.setopt(c.WRITEFUNCTION, b.write)
c.perform()
content = b.getvalue()
print "HTTP CODE: ", c.getinfo(c.HTTP_CODE)
b.close()
return content
def purge(self, url):
cmd = 'PURGE '
proxy = '127.0.0.1:8080'
c = self.c
c.setopt(c.URL, url)
c.setopt(c.PROXY, proxy)
c.setopt(c.CUSTOMREQUEST, cmd)
c.perform()
status = c.getinfo(c.HTTP_CODE)
print "HTTP CODE: ", status
return status
if __name__ == '__main__':
page = 'http://news.sohu.com/'
c = Curl()
c.init(True)
c.get(page)
page1 = 'http://www.google.com/'
post_data_dic = {"name":"value"}
c.post(page1, post_data_dic)
page2 = 'http://m3.biz.itc.cn/pic/new/n/94/87/Img7798794_n.jpg'
c.purge(page2)
3.简单的pycURL multi类包装
#!/usr/bin/env python
#encoding: utf-8
import sys, pycurl, cStringIO
class MCurl:
def __init__(self, tasks, concurrent):
self.taskQ = tasks
self.taskQ_size = len(tasks)
self.max_conn = concurrent
self.resp_dict = {}
self.m = pycurl.CurlMulti()
def __del__(self):
self.m.close()
def add_tasks(self):
self.max_conn = min(self.taskQ_size, self.max_conn)
assert 1 <= self.max_conn <= 100, "invalid number of concurrent urls"
print "===Getting %d urls using %d concurrent cURL handle pool===" % (self.taskQ_size, self.max_conn)
self.m.handles = []
for i in range(self.max_conn):
c = pycurl.Curl()
c.fp = None
c.setopt(pycurl.FOLLOWLOCATION, 1)
c.setopt(pycurl.MAXREDIRS, 5)
c.setopt(pycurl.CONNECTTIMEOUT, 30)
c.setopt(pycurl.TIMEOUT, 300)
c.setopt(pycurl.NOSIGNAL, 1)
self.m.handles.append(c)
self.resp_dict['total'] = self.taskQ_size
self.resp_dict['succ'] = []
self.resp_dict['fail'] = []
def process_tasks(self):
freelist = self.m.handles[:]
queue = self.taskQ
num_processed = 0
while num_processed < self.taskQ_size:
#if there is an url to process and a free curl handle, add to multi stack
while queue and freelist:
url, filename = queue.pop(0)
c = freelist.pop()
c.fp = open(filename, "wb")
c.setopt(pycurl.URL, url)
c.setopt(pycurl.WRITEDATA, c.fp)
self.m.add_handle(c)
#store some info for use later
c.filename = filename
c.url = url
#run the internal curl state machine for the multi stack
while 1:
ret, num_handles = self.m.perform()
if ret != pycurl.E_CALL_MULTI_PERFORM:
break
#check if curl handle has terminated, and add them to the freelist
while 1:
num_q, ok_list, err_list = self.m.info_read()
for c in ok_list:
c.fp.close()
c.fp = None
self.resp_dict['succ'].append(c.url)
self.m.remove_handle(c)
print ("Success:", c.filename, c.url, c.getinfo(pycurl.EFFECTIVE_URL))
freelist.append(c)
for c, errno, errmsg in err_list:
c.fp.close()
c.fp = None
self.resp_dict['fail'].append(c.url)
self.m.remove_handle(c)
print("Failed: ", c.filename, c.url, errno, errmsg)
freelist.append(c)
num_processed = num_processed + len(ok_list) + len(err_list)
if num_q == 0:
break;
#currently no more I/O is pending, we just call select() to sleep until some more data is available
self.m.select(1.0)
def del_tasks(self):
for c in self.m.handles:
if c.fp is not None:
c.fp.close()
c.fp = None
c.close()
def dump_process(self):
print self.resp_dict
#========= main entry point ==========
#give tasks info
urls = ["http://m3.biz.itc.cn/pic/new/n/94/87/Img7798794_n.jpg",
"http://m3.biz.itc.cn/pic/new/n/94/87/Img7798794_n.jpg", "", "http://m2.biz.itc.cn/pic/new/n/93/87/Img7798793_n.jpg",
"http://m1.biz.itc.cn/pic/new/n/92/87/Img7798792_n.jpg", "http://m3.biz.itc.cn/pic/new/n/94/91/Img7799194_n.jpg",
"http://m1.biz.itc.cn/pic/new/n/96/87/Img7798796_n.jpg", "http://m2.biz.itc.cn/pic/new/n/97/87/Img7798797_n.jpg",
"http://m1.biz.itc.cn/pic/new/n/16/88/Img7798816_n.jpg", "http://m2.biz.itc.cn/pic/new/n/17/88/Img7798817_n.jpg",
"http://m4.biz.itc.cn/pic/new/n/95/87/Img7798795_n.jpg", "http://m4.biz.itc.cn/pic/new/n/91/91/Img7799191_n.jpg"]
concurr = 6
queue = []
for url in urls:
url = url.strip()
if not url or url[0] == "#":
continue
filename = "./sohu_%03d.jpg" % (len(queue) + 1)
queue.append((url, filename))
mc = MCurl(queue, concurr)
mc.add_tasks()
mc.process_tasks()
mc.del_tasks()
mc.dump_process()
运行截图
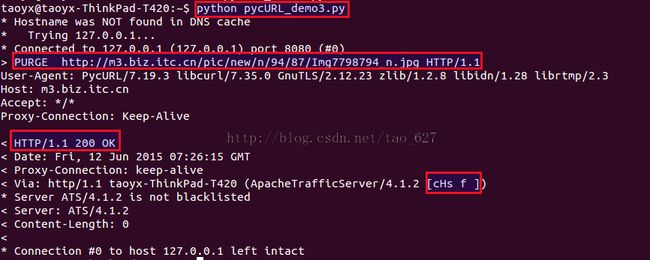
4.PURGE等自定义请求实现
#!/usr/bin/env python
#encoding: utf-8
import sys, pycurl, cStringIO, urllib
url = 'http://m3.biz.itc.cn/pic/new/n/94/87/Img7798794_n.jpg'
cmd = 'PURGE '
#cmd = 'DELETE '
proxy = '127.0.0.1:8080'
c = pycurl.Curl()
c.setopt(c.URL, url)
c.setopt(c.VERBOSE, 1)
c.setopt(c.PROXY, proxy)
c.setopt(c.CUSTOMREQUEST, cmd)
try:
c.perform()
except Exception as e:
print e
status = c.getinfo(c.HTTP_CODE)
print "HTTP CODE: ", status
c.close()
运行截图
说明:
1.使用post表单时,只需要设置
c.setopt(c.POSTFIELDS, postfields)
这个选项会自动将HTTP request mathod改为POST
源码pycurl/examples/quickstart/form_post.py 很标准
2.异步批量预取的例子在pycurl/examples/retriever-multi.py,很有代表性的
3.使用自定义方法
c.setopt(pycurl.CUSTOMREQUEST,"DELETE")
详见官网文章
http://curl.haxx.se/libcurl/c/CURLOPT_CUSTOMREQUEST.html
http://stackoverflow.com/questions/17075844/how-to-send-delete-request-in-pycurl
delete request