基于Renascence架构的SQL查询引擎设计(一)
基于Renascence架构的sqlite查询优化(一)
sqlite查询优化方案是一开始是在Hw时设计的,但当时只实现一些简单case,并未完成sql的普遍支持。后面考虑到这可以做为 Renascence 架构的一个实验场景,因此将其方案做了一番修改,代码也重写了一遍,现在做成一个能支持普通sql查询的demo。
sqlite架构
参考:http://wiki.dzsc.com/info/7440.html
sqlite是移动设备广泛使用的轻量级数据库引擎。它主要由前端——虚拟机——后端三部分组成,这里不做详细介绍。
VM机制
参考:
http://www.cnblogs.com/hustcat/archive/2010/06/23/1762987.html
对于任何一条sql语句,sqlite都是先编译为一串虚拟机码(执行计划),然后基于虚拟机码执行程序:
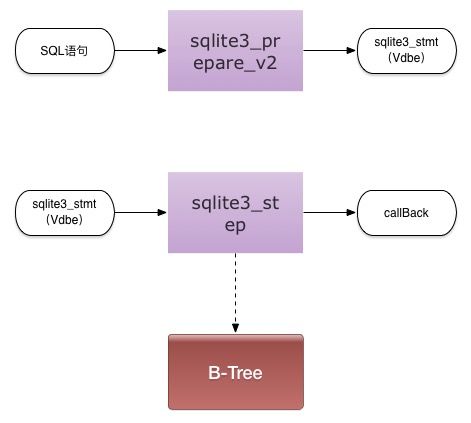
如:
select * from TEST where age >20 and salary<99999666;
被翻译为如下的虚拟机码:
addr:0 opcode:Init p1:0 p2:16 p3:0 p4: p5:00 comment:
addr:1 opcode:OpenRead p1:0 p2:2 p3:0 p4:5 p5:00 comment:
addr:2 opcode:Rewind p1:0 p2:14 p3:0 p4: p5:00 comment:
addr:3 opcode:Column p1:0 p2:2 p3:1 p4: p5:00 comment:
addr:4 opcode:Le p1:2 p2:13 p3:1 p4:(BINARY) p5:53 comment:
addr:5 opcode:Column p1:0 p2:3 p3:3 p4: p5:00 comment:
addr:6 opcode:Ge p1:4 p2:13 p3:3 p4:(BINARY) p5:53 comment:
addr:7 opcode:Column p1:0 p2:0 p3:5 p4: p5:00 comment:
addr:8 opcode:Column p1:0 p2:1 p3:6 p4: p5:00 comment:
addr:9 opcode:Copy p1:1 p2:7 p3:0 p4: p5:00 comment:
addr:10 opcode:Copy p1:3 p2:8 p3:0 p4: p5:00 comment:
addr:11 opcode:Column p1:0 p2:4 p3:9 p4: p5:00 comment:
addr:12 opcode:ResultRow p1:5 p2:5 p3:0 p4: p5:00 comment:
addr:13 opcode:Next p1:0 p2:3 p3:0 p4: p5:01 comment:
addr:14 opcode:Close p1:0 p2:0 p3:0 p4: p5:00 comment:
addr:15 opcode:Halt p1:0 p2:0 p3:0 p4: p5:00 comment:
addr:16 opcode:Transaction p1:0 p2:0 p3:3 p4:0 p5:01 comment:
addr:17 opcode:TableLock p1:0 p2:2 p3:0 p4:TEST p5:00 comment:
addr:18 opcode:Integer p1:20 p2:2 p3:0 p4: p5:00 comment:
addr:19 opcode:Integer p1:99999666 p2:4 p3:0 p4: p5:00 comment:
addr:20 opcode:Goto p1:0 p2:1 p3:0 p4: p5:00 comment:架构缺陷与优化思路
缺陷:
1、采用虚拟机模式(VM),且粒度为1行,switch case 太频繁,使CPU的cache命中率不高。
2、操作粒度太小,一列一列地取值操作,不利于进一步优化(GPU加速,多线程等)。
3、进行优化时,需要同时修改前端与后端,双重工作。
优化思路:
1、保留前端与后端,绕开VM机制,采用有向无环图(DAG)——算子的架构,每个算子次处理一批数据。
2、对于算子本身可作GPU/多线程优化加速
Renascence(Genetic-Program-Frame)介绍
Renascence是自动编程架构的框架库,一般而言它可视为一个特殊的编译器,算法库不直接提供对外API,而是将往Renascence中注册函数。上层应用或上层库调用算法库时,输入一条公式,然后 Renascence将公式编译为有向无环图,间接调用算法库。
Renascence的作用,优化上层应用调用下层引擎的逻辑,并起自适配作用。
1、优化调用逻辑,防止重复计算
新查询引擎的设计,主要便利用了Renascence这个功能。
比如如下的调用逻辑:f(g(x0), g(x0)),便可优化为

T节点表示转发,R节点表示传递,如是便省去g(x0)的第二次计算。
2、允许自动化参数调节
写程序,尤其是算法类程序时,调参数是不可避免的事情,如多线程优化中开启的线程数,开启多线程优化的阈值,使用OpenCL时device端缓存的大小,一次运算的globalsize, localsize,等等。
Renascence可提供一个框架,以公式链接起来的所有函数参数,会通过一个通一的方案调优。这个优化的目标,对查询引擎的优化而言,可以设为时间的快慢或内存占用的多少。
对sqlite查询优化这个场景而言,主要就是内存池一个BLOCK的大小,每次取多少行的数据,哈希表初始大小等等。
3、允许部分程序逻辑根据实际应用场景动态生成与调节
比如一个where条件 where A > 30 and B < 50 and C >100,且 A、B、C 三列均无索引
公式解释为:FILTER(x0, AND(AND(x1, x2), x3)),其中x0为源数据,x1、x2、x3是算符,分别表示 A>30、B<50和C>100
但由于注册等价匹配: FILTER(x0, AND(x1, x2)) = FILTER(FILTER(x0, x1), x2) = FILTER(FILTER(x0, x2), x1)
将会被转换为如下一系列等价形式:
FILTER(x0, AND(AND(x1, x2), x3)) = FILTER(FILTER(x0, AND(x1, x2)), x3) | FILTER(FILTER(x0, x3), AND(x1,x2)) =
FILTER(FILTER(FILTER(x0, x1), x2), x3) | FILTER(FILTER(FILTER(x0, x2), x1), x3)
FILTER(FILTER(FILTER(x0, x3), x1), x2) | FILTER(FILTER(FILTER(x0, x3), x2), x1)
这四个等价形式中选取哪一个,可以通过数据库采样实验(目标函数)动态决定。
2、3事实上是Renascence架构的核心,但对于数据库的查询引擎而言,程序逻辑相对固定,没有太多让Renascence发挥的空间,尽管如此,在Renascence架构之上实现CBO类似的优化还是会容易一些。
注:CBO 即 Cost Based Optimizer,为ORACLE的优化器,
参考:http://blog.csdn.net/suncrafted/article/details/4239237
查询引擎设计
图中 libGP.so 即 Renascence 库。
新引擎分为如下部分:
对接层
1、转换sqlite解析的语法树为 dag库所支持的格式
2、调用sqlite后端B-Tree的代码,获取数据源
3、将dag库返回的结果转换为sqlite的内存格式(Mem)
公式层
数据类型
在描述公式生成过程之前,先说明dag库的主要数据类型定义:
RawData:从对接层调用sqlite后端,读取出来的原始数据格式,sqlite是按行存储的,但会作一个序列化操作
FormalData:RawData中的数据,经过投影器解析(实际是反序列化),将所需要的列解出而得的数据
VirtualColumn:一列数据,由 FormalData 中复制或经表达式运算而得
VirtualColumnSet:列集,VirtualColumn 的集合
每个查询子句最终输出的是一个 VirtualColumnSet,而输入是一系列 RawData
语法分析与公式生成
我们先来看一下sqlite解析出来的语法树结构
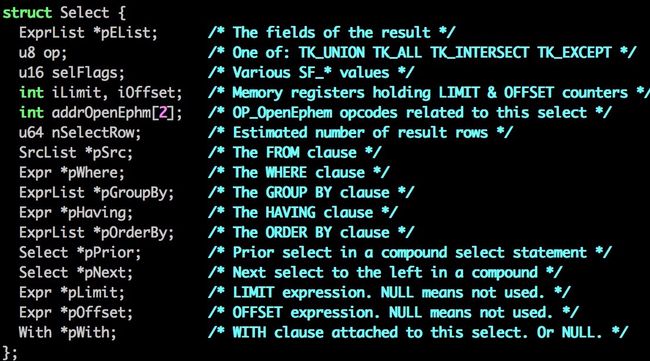
如图所示,Select 结构包含的主要是表达式ExprList(由一系列Expr组成)和源SrcList(由一系列SrcList_item组成)
解析的核心思路就是依次解析从句,然后依次解析表达式提取数值。
SQL语句:select age, age*2, SNO from TEST where salary=99999666 order by SNO, SNAME; (salary 无索引)
Sort(MergeSet(MergeSet(SetAlloc(Column(Project(Filter(x0, Op2(Column(Project(x0, x1), x3), Const(x4), x2)), x5), x6)), Op2(Column(Project(Filter(x0, Op2(Column(Project(x0, x1), x3), Const(x4), x2)), x5), x6), Const(x8), x7)), Column(Project(Filter(x0, Op2(Column(Project(x0, x1), x3), Const(x4), x2)), x5), x9)),MergeSet(SetAlloc(Column(Project(Filter(x0, Op2(Column(Project(x0, x1), x3), Const(x4), x2)), x5), x9)), Column(Project(Filter(x0, Op2(Column(Project(x0, x1), x3), Const(x4), x2)), x5), x10)), x11)这个公式是如何生成的呢:
第一步,决定数据源
与这一步有关的子项是SrcList和where
查看 Select 结构体的内容可知,只有一个Source,且不是子查询,存在where条件条件,需要作过滤
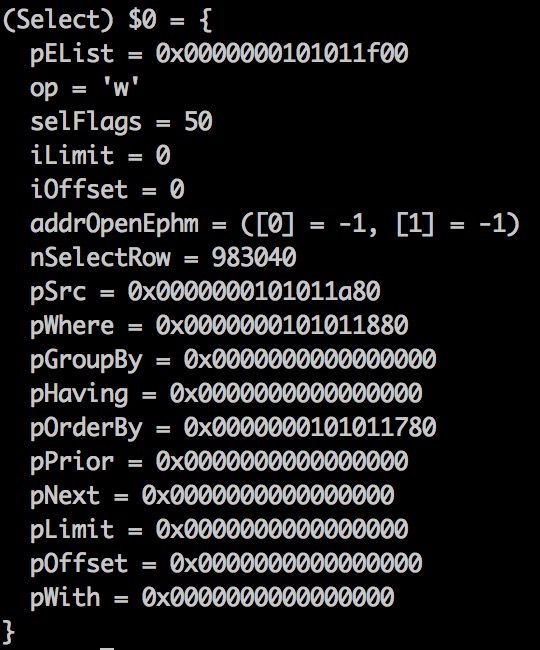
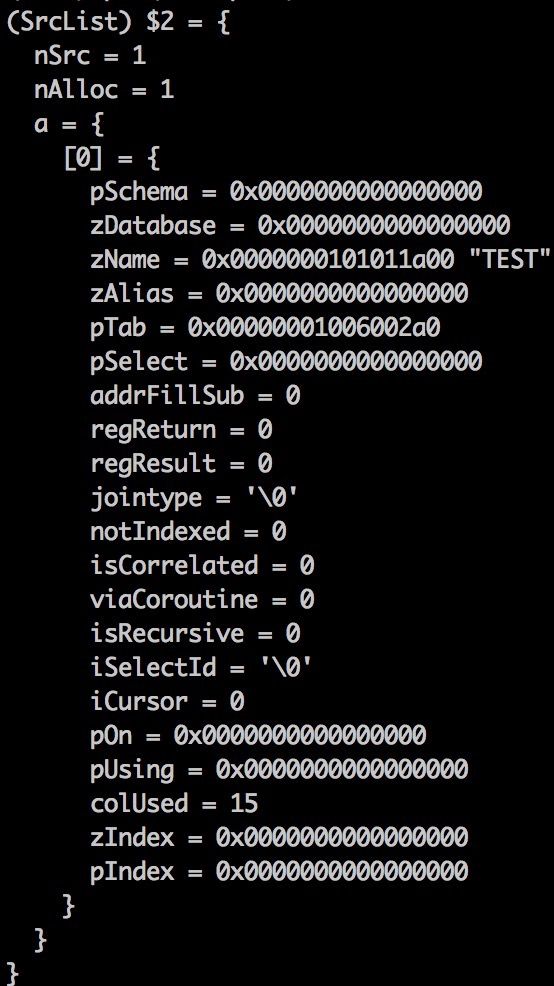
得到的公式为:
Project(Filter(x0, Op2(Column(Project(x0, x1), x3), Const(x4), x2)), x5)
为了避免解析不通过where条件的行,在第一步解析where子句所需的列,在过滤之后再解析其他所需要的列。
(当需要连接时,处理逻辑会复杂一些,如两个表内连接的对应公式为Join(Project(x0, x2),SortAndMask(Project(x1, x3),x4), x5),x0 是大表的 RawData,x1是小表的 RawData,本篇暂不详述)
第二步,解析Select的表达式组
解析表达式,直接按表达式树一层组织公式就好,如图所示的表达式树:
被解析为公式:
Op2(Column(x0, x1), Op2(Column(x0, x1), Const(x3), x2), x2)
Op2表示通用二目算子,x2为算符*
x0为 FormalData数据源
x3为 表达式 2,经过 Const 解析为常量 2
Column为取列算子,x1记录取的是age这一列
(其实这样解析并不太好,最好方式是每个表达式对应一个算子,但这样工作量很大,因此暂时这么做)
在解析时,Column对应的源,会被替换为第一步所得到的数据源,即Project(Filter(x0, Op2(Column(Project(x0, x1), x3), Const(x4), x2)), x5)
因此公式中会重复出现这一段,显得所长。但后面 Renascence 作解析时,会去除冗余,因此不会影响性能。
每个表达式解析完后,输出是一个 列(VirtualColumn),需要用 SetAlloc 和 MergeSet 算子将其一个个合并为列集(VirtualColumnSet)
第三步,加前缀(GroupBy和AggFunc)
由于此语句无 GroupBy,不详细介绍
第四步,加后缀(Distinct、Sort、Limit)
这里只有一个Sort子句。
Sort算子输入是 Select 和 Order By 两个表达式组产生的列集,输出与 Select 表达式组的列集相同的一个列集。
因此解析 Order by 表达式集,将其合并,然后将其与 Select 列集一并输入 Sort 算子,即得出最终的列集。
经过 Renascence 优化之后,这个公式将被拆成如下片段计算:
Root: Sort(MergeSet(MergeSet(SetAlloc(x12), Op2(x12, Const(x8), x7)), x13), MergeSet(SetAlloc(x13), Column(x15, x10)), x11)
x12: Column(x15, x6)
x13: Column(x15, x9)
x14: Filter(x0, Op2(Column(Project(x0, x1), x3), Const(x4), x2))
x15: Project(x14, x5)
对应的有向无环图太复杂就不画了。
运行DAG并读取其输出结果
首先根据公式创建一个 ADF:
AGPProducer* producer = ProducerInstance::getInstance();
mADF = GP_Function_Create_ByFormula(producer, formula, NULL);这个ADF的输入由两部分组成:参数与数据源
参数parameters在创建公式的过程中生成,数据源则在运行ADF时临时读取。
配置输入的代码:
int i=0; i<maxnumber; ++i)
{
mInputs.push(NULL, NULL);
}
for (auto pair:parameters)
{
HWASSERT(pair.first < mInputs.size());
mInputs.contents[pair.first] = pair.second;
}
for (auto pair:sources)
{
HWASSERT(pair.first < mInputs.size());
mInputs.contents[pair.first].type = gHwOriginDataBatch;
}运行的代码:
for (auto pair : mSources)
{
auto batch = pair.second.produce(pair.second);
mInputs.contents[pair.first].content = batch;
}
mOutput = GP_Function_Run(mADF, &mInputs);算子层
1、基于RawData的运算:
投影(Project):作数据解析,将 RawData 需要提取的列取出来,生成 FormalData
过滤(Filter):作数据过滤,将 RawData 中不满足条件的行去掉。
2、基于列的运算:
Column:从FormalData复制一列数据出来
Const:将常数映射为一个数据列
Op(表达式):对数据列作运算,生成新数据列
3、基于列集的运算:
去重(Distinct):对列集进行去重,目前使用 stl的set实现,效率比较低。
排序(Sort):对列集进行排序
分组(GroupBy):实际上是在排序的基础额外做一个标志,把相同的行合并。
这部分算子是最耗时间的,最需要重点优化
4、列转换为列集的算子:SetAlloc、MergeSet
SetAlloc:生成一个列集
MergeSet:往列集中加一个列
执行的过程如图所示:
性能测试结果
小米pad上数据,TEST表数据量为91W
TEST2表行数 20W
运行5次的总时间:
select * from TEST where age >20 and salary<99999666;: Old: 14252.2ms, New: 12389.5ms
select * from TEST where age >20 ;: Old: 13416.2ms, New: 11889.1ms
select age, SNO, SNAME from TEST order by SNO, SNAME;: Old: 30262.1ms, New: 22727.2ms
select age*2, SNO, SNAME from TEST order by SNO, SNAME;: Old: 31254.6ms, New: 24319ms
select distinct * from TEST where SNO in (select SNO from TEST2);: Old: 26575.3ms, New: 33258.9ms
select distinct * from TEST;: Old: 19063.8ms, New: 27220.6ms
select * from TEST where SNO in (select SNO from TEST2);: Old: 23383.9ms, New: 19860.9ms
select * from TEST where SNO in (‘aa’, ‘bb’, ‘cc’);: Old: 2697.3ms, New: 1914.26ms
select * from TEST2;: Old: 3316.53ms, New: 3061.97ms
select TEST.age, TEST.SNO, TEST.salary, TEST2.SNAME from TEST JOIN TEST2 on (TEST.salary=TEST2.SALARYDD);: Old: 50112.1ms, New: 42631.2ms
select sno, SNAME, sum(age+salary), count(age) from TEST group by SNO, SNAME;: Old: 31813.3ms, New: 25966.2ms
select count(sno), sum(age) from TEST;: Old: 3167.34ms, New: 2830.28ms
鉴于算子本身的实现并不是太好,以及后续 MAP-REDUCE +多线程框架的引入,预计还有至少 100% 以上的性能提升空间。
基于Renascence架构的查询引擎设计思想
依赖Renascence组织调用逻辑
查询引擎分为公式层与算子层,公式层生成一个模糊的公式,Renascence生成适合的程序逻辑(这里是有向无环图DAG),调用算子层进行计算。
性能优化集中于算子/执行层面
查询引擎的性能优化只需要优化算子,逻辑性的优化由Renascence完成。
由于代码不便公开且还在大改,很多细节并未完全描述,留到下一篇再写。