Hadoop2.0的yarn 的基本的介绍
YARN (MRv2) 简介
为了实现一个 Hadoop 集群的集群共享、可伸缩性和可靠性。设计人员采用了一种分层的集群框架方法。具体来讲,特定于 MapReduce 的功能已替换为一组新的守护程序,将该框架向新的处理模型开放。
图 2. YARN 的新架构回想一下,由于限制了扩展以及网络开销所导致的某些故障模式,MRv1 JobTracker 和 TaskTracker 方法曾是一个重要的缺陷。这些守护程序也是 MapReduce 处理模型所独有的。为了消除这一限制,JobTracker 和 TaskTracker 已从 YARN 中删除,取而代之的是一组对应用程序不可知的新守护程序。
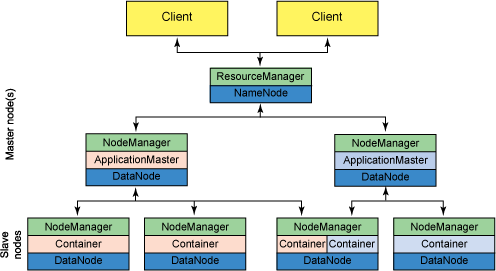
YARN 分层结构的本质是 ResourceManager。这个实体控制整个集群并管理应用程序向基础计算资源的分配。ResourceManager 将各个资源部分(计算、内存、带宽等)精心安排给基础 NodeManager(YARN 的每节点代理)。ResourceManager 还与 ApplicationMaster 一起分配资源,与 NodeManager 一起启动和监视它们的基础应用程序。在此上下文中,ApplicationMaster 承担了以前的 TaskTracker 的一些角色,ResourceManager 承担了 JobTracker 的角色。
ApplicationMaster 管理一个在 YARN 内运行的应用程序的每个实例。ApplicationMaster 负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器的执行和资源使用(CPU、内存等的资源分配)。请注意,尽管目前的资源更加传统(CPU 核心、内存),但未来会带来基于手头任务的新资源类型(比如图形处理单元或专用处理设备)。从 YARN 角度讲,ApplicationMaster 是用户代码,因此存在潜在的安全问题。YARN 假设 ApplicationMaster 存在错误或者甚至是恶意的,因此将它们当作无特权的代码对待。
NodeManager 管理一个 YARN 集群中的每个节点。NodeManager 提供针对集群中每个节点的服务,从监督对一个容器的终生管理到监视资源和跟踪节点健康。MRv1 通过插槽管理 Map 和 Reduce 任务的执行,而 NodeManager 管理抽象容器,这些容器代表着可供一个特定应用程序使用的针对每个节点的资源。YARN 继续使用 HDFS 层。它的主要 NameNode 用于元数据服务,而 DataNode 用于分散在一个集群中的复制存储服务。
要使用一个 YARN 集群,首先需要来自包含一个应用程序的客户的请求。ResourceManager 协商一个容器的必要资源,启动一个 ApplicationMaster 来表示已提交的应用程序。通过使用一个资源请求协议,ApplicationMaster 协商每个节点上供应用程序使用的资源容器。执行应用程序时,ApplicationMaster 监视容器直到完成。当应用程序完成时,ApplicationMaster 从 ResourceManager 注销其容器,执行周期就完成了。
通过这些讨论,应该明确的一点是,旧的 Hadoop 架构受到了 JobTracker 的高度约束,JobTracker 负责整个集群的资源管理和作业调度。新的 YARN 架构打破了这种模型,允许一个新 ResourceManager 管理跨应用程序的资源使用,ApplicationMaster 负责管理作业的执行。这一更改消除了一处瓶颈,还改善了将 Hadoop 集群扩展到比以前大得多的配置的能力。此外,不同于传统的 MapReduce,YARN 允许使用 Message Passing Interface 等标准通信模式,同时执行各种不同的编程模型,包括图形处理、迭代式处理、机器学习和一般集群计算。