hadoop集群安装和配置
准备工作:
Jdk 1.7.0_71
Hadoop2.2.0
虚拟机vmware
Centos6.3
安装就是直接解压就行,jdk的安装自己上网查,
主要是配置,目前是一主一从,
主:192.168.100.128
从:192.168.100.129
步骤:
1、首先配置ssh,一般来说centos安装的时候就已经安装了ssh了,这里主要是配置无密码登录;进入.ssh文件夹ssh-keygen -t rsa,直接一直回车;
Cat id_rsa.pub >> authorized_keys;从Hadoop服务器上面的id_rsa_1.pub由主服务器拷贝而来,主从服务器均由root用户重启sshd服务即可使主服务器能登录从服务器;
2、hadoop配置过程 (非root用户)
配置之前,需要在hadoop1本地文件系统创建以下文件夹:
~/dfs/name
~/dfs/data
~/temp
这里要涉及到的配置文件有7个:
~/hadoop-2.2.0/etc/hadoop/hadoop-env.sh
~/hadoop-2.2.0/etc/hadoop/yarn-env.sh
~/hadoop-2.2.0/etc/hadoop/slaves
~/hadoop-2.2.0/etc/hadoop/core-site.xml
~/hadoop-2.2.0/etc/hadoop/hdfs-site.xml
~/hadoop-2.2.0/etc/hadoop/mapred-site.xml
~/hadoop-2.2.0/etc/hadoop/yarn-site.xml
以上个别文件默认不存在的,可以复制相应的template文件获得。
<目前配置均在主服务器上配置:Master.Hadoop>
配置文件1:hadoop-env.sh
修改JAVA_HOME值(export JAVA_HOME=/psy/jdk1.7.0_71)
配置文件2:yarn-env.sh
修改JAVA_HOME值(export JAVA_HOME=/psy/jdk1.7.0_71)
配置文件3:slaves(这个文件里面保存所有slave节点)
写入以下内容:
Slave1.Hadoop
配置文件4:core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://Master.Hadoop:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/home/psy/tmp</value> <description>Abase for othertemporary directories.</description> </property> <property> <name>hadoop.proxyuser.psy.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.psy.groups</name> <value>*</value> </property></configuration>
配置文件5:hdfs-site.xml
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop1:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/psy/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/psy/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>
配置文件6:mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>Master.Hadoop:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>Master.Hadoop:19888</value> </property> </configuration>
配置文件7:yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>Master.Hadoop:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>Master.Hadoop:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>Master.Hadoop:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>Master.Hadoop:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>Master.Hadoop:8088</value> </property> </configuration>
3、修改hosts文件以及hostname
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.100.128 Master.Hadoop
192.168.100.129 Slave1.Hadoop
添加进去所有Hadoop节点的IP和hostName的对应信息;所有节点都要改,不要将127.0.0.1注释掉,那种做法是错的
4、将主服务器上面地 Hadoop文件直接copy到从服务器对应的文件夹里面,用户名字尽量弄成一样的;
5、启动Hadoop
在hadoop文件夹里面的sbin目录下start-all.sh,或者分步先
start-dfs.sh,再start-yarn.sh启动;
6、查看jps
主服务器
从服务器

7、查看主服务器上面的50070
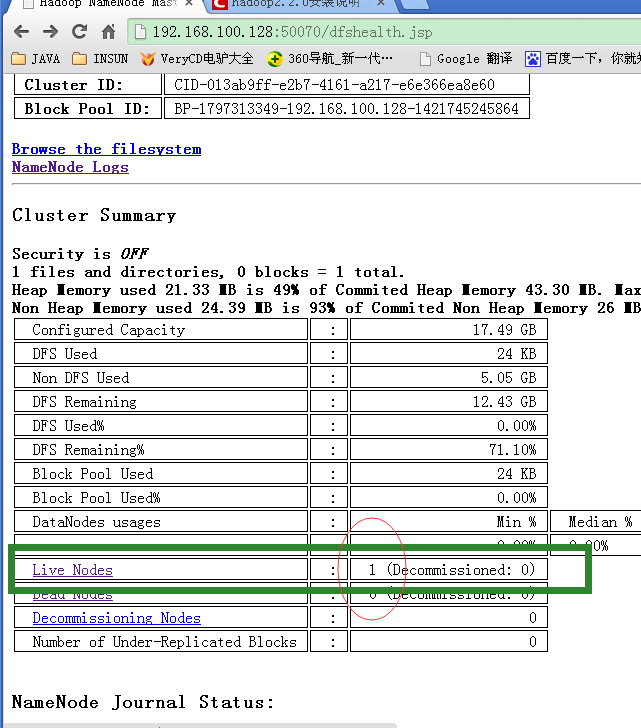
8、恭喜这个小集群安装成功;