快速理解使用DOM解析简单的XML文档
xml DOM中的节点类型
首先介绍一些XML的节点类型,你可以不必全部细看,可以重点了解Element节点和Text节点。如下图1所示,为XML文档的12中节点类型。
图1:XML文档节点类型
在DOM中除了上面的12种节点类型外,还有一个抽象公共基类就是Node,代表节点的抽象。Node可以代表图1中的任何一种节点类型。Node类抽象了一些基本的操作,例如获得节点的类型、节点的名称、节点的值等。
对于一个节点(Node)最重要的3个属性就是nodeName(节点名称),nodeValue(节点值),nodeType(节点类型)。而我们最常用的3个节点就是Element节点,Text节点和Attr节点,对于Attr节点一般很少单独使用,都是用Element节点直接获取属性值。Element是可以嵌套的,所以一般都是以Element为中心来处理xml文件。
Element:
<property name="content">hello world</property>代表一个Element节点,它包含一个Text类型的子节点。
Attr:
Element节点<property environment="env"/>中的environment="env"就是一个Attr节点
Text:
Text元素比较特殊,一般是其他节点和节点之间的元素,例如:
<property name="content">hello world</property>
bbb
<!-- 这是注释 -->
中的Text元素就是Element节点和Comment节点之间的元素(行结束符bbb行结束符)在windows中的行结束符是\r\n。
Comment:
<!-- 这是注释 -->
上面介绍的是比较抽象的,下面通过一个实例来说明一下:
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Attr;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class StudyDom
{
private static final String XML = "E:\\trayvon\\note\\client.xml";
public static void main(String[] args)
{
testNode();
// testElement();
}
private static Document init()
{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = null;
Document doc = null;
try
{
builder = factory.newDocumentBuilder();
} catch (ParserConfigurationException e)
{
e.printStackTrace();
}
try
{
doc = builder.parse(XML);
} catch (SAXException | IOException e)
{
e.printStackTrace();
}
return doc;
}
public static void testElement()
{
Document doc = init();
Element root = doc.getDocumentElement();
Attr attr = root.getAttributeNode("name");
System.out.println(attr);
System.out.println(root.getAttribute("name"));//获取属性名称为name的值
System.out.println(root.getTagName());
System.out.println(root.getNodeName());//获取节点的名称
System.out.println(root.getNodeValue());//Element节点的nodeValue为null
System.out.println(root.getNodeType());//Element节点的nodeType值为1
}
public static void testNode()
{
Document doc = init();
Element root = doc.getDocumentElement();
NodeList childNodes = root.getChildNodes();
System.out.println(childNodes.getLength());
for(int i=0;i<childNodes.getLength();i++)
{
Node item = childNodes.item(i);
System.out.println("nodeType:"+item.getNodeType()+" nodeName:"+item.getNodeName()+" nodeValue:"+item.getNodeValue());
}
}
}
其中client.xml的类容如下:
<?xml version="1.0"?> <project basedir="../" name="forumclient" default="dist"> aaa <property environment="env"/> <property name="src" value="src/client"/> <property name="content">hello world</property> bbb <!-- 这是注释 --> </project>
testNode的输出为:
9 nodeType:3 nodeName:#text nodeValue: aaa nodeType:1 nodeName:property nodeValue:null nodeType:3 nodeName:#text nodeValue: nodeType:1 nodeName:property nodeValue:null nodeType:3 nodeName:#text nodeValue: nodeType:1 nodeName:property nodeValue:null nodeType:3 nodeName:#text nodeValue: bbb nodeType:8 nodeName:#comment nodeValue: 这是注释 nodeType:3 nodeName:#text nodeValue:
其中nodeType为1表示是Element节点,nodeType为3表示是Text节点,具体的对于关系参见图4。nodeName和nodeValue的值对应关系参见图3。
为了更加清晰的弄清楚输出的含义,请看下图2:
图2:XML文档的节点示意图
testNode首先是从整个文档中获得一个Element节点,这个是一个nodeNamea为project的节点也是根节点。然后输出的是该根节点的所有子节点。如上图2所示一共9个子节点,所有子节点的长度为9。
从上图2也可以意会一些出节点的划分方式,值得注意和强调的是Element节点是可嵌套的,<property name="content">hello world</property>这个Element节点就是一个嵌套节点,如果要得到hello world不能直接通过Element的节点的getNodeValue来取的,因为Element节点的getNodeValue返回值是空。取而代之的是通过Element获得它的Text子节点,在通过Text节点的getNodeValue来获得其值。
图3:XML节点的nodeName与nodeValue
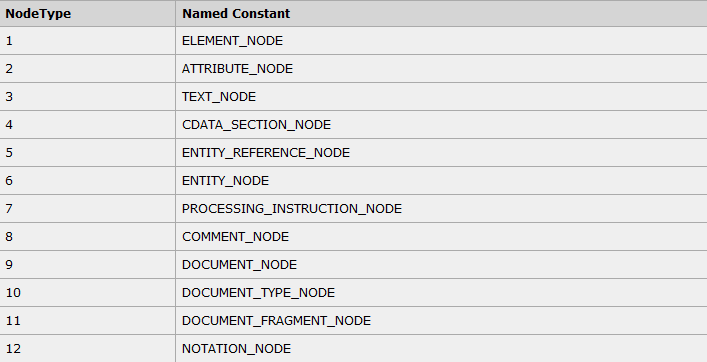
图4:XML DOM节点类型对应的常量
总结:在使用DOM解析XML文档是最常使用的就是Element节点,Text节点。一定要注意的就是不要使用Element节点来获取节点的值,因为这种方式很直观所以我们很容易这样做,取而代之的是用Element来取属性值和子节点的集合,用Text节点来获取值。
在另一篇文章使用DOM解析简单的XML文档实例中我们通过使用DOM来解析ant配置文件和pom配置文件中的jar包来说明怎样使用Element节点和Text节点。
XML DOM 节点类型(Node Types):http://www.w3school.com.cn/xmldom/dom_nodetype.asp
Entity: http://www.ibm.com/developerworks/cn/xml/x-entities/