OpenCv实现卷积神经网络实例:tiny_cnn代码详解(6)——average_pooling_layer层结构类分析
在之前的博文中我们着重分析了convolutional_layer类的代码结构,在这篇博文中分析对应的下采样层average_pooling_layer类:
一、下采样层的作用
下采样层的作用理论上来说由两个,主要是降维,其次是提高一点特征的鲁棒性。在LeNet-5模型中,每一个卷积层后面都跟着一个下采样层:
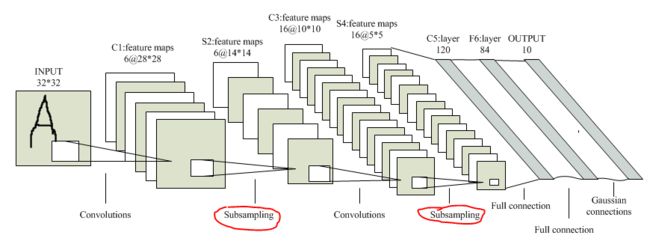
原因就是当图像在经过卷积层之后,由于每个卷积层都有多个卷积模板,直接导致卷积结果输出的特征矩阵相对于输入的数据矩阵其维数要提高数倍,再加上存在若干卷积层(谷歌的某些模型甚至超过100层),若不进行降维操作,最后的特征维数可想而知,因此在这里下采样层就充当了一个特征降维的角色。比如这里用的是2*2模板均值下采样,说白了就是四个相邻像素经过加权计算变成一个,维数变为原来的四分之一,降维性能显而易见。至于鲁棒性问题,理论上只要是合理的降维手段,对鲁棒性都会有一定的提升(当然这是我的个人观点)。
二、average_pooling_layer类结构
average_pooling_layer类同样继承自基类partial_connected_layer,和前文中所说的convolutional_layer类算是相同继承层次,因此与convolutional_layer类在结构上也非常相似,但下采样层由于其功能相对单一,因此在结构上比convolutional_layer类要简洁不少
2.1 成员变量
average_pooling_layer类的成员变量一共有两个,分别保存输入数据矩阵的属性和下采样后输出特征矩阵的属性:
至于有关layer_size_t、index3d等类型的相关知识在上一篇博客中已经进行了详细介绍,这里不再赘述。
2.2 构造函数
average_pooling_layer类的构造函数十分简洁,基本上就是调用了基类partial_connected_layer的构造函数,然后在完成自己类中两个成员变量的初始化而已:
这里稍稍介绍一下pooling_size_mismatch()函数。这是一个定义在基类layer中的函数,作用就是抛出尺寸异常的信息,而在每一层中对尺寸匹配的检验标准都不同,因此各个子类在调用这个函数给出异常信息时,需要依据对应层的标准来进行判断,比如在下采样层,我们认为如果输入数据矩阵的尺寸不是下采样窗口的整数倍时,则无法正常进行分块降维,即视为尺寸不匹配,抛出尺寸异常信息:
2.3 其他函数
除了构造函数,下采样层还提供了一些其他函数,包括下采样矩阵权重初始化函数和偏置初始化函数(在下采样的过程中同样需要加上偏置)init_connection(),权重矩阵设置函数connect_kernel(),以及输出特征矩阵图像化的转换函数output_to_image(),以上这些函数与前一篇博文中convolutional_layer类中的对应的函数功能可以说是完全相同(毕竟都是继承与同一个基类),这里不再赘述。
三、注意事项
1、下采样层后的激活函数
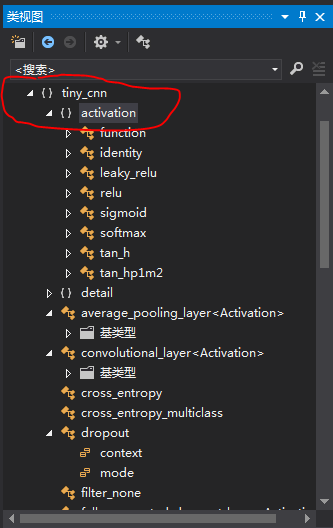
在实际的卷积神经网络模型中,对卷积特征输出进行下采样之后,紧接着应该送入激活函数中,换句话说下采样层和激活函数应该是紧密相关的。不过在这里作者并没有将激活函数直接放在average_pooling_layer类中,而是将每个激活函数都封装成对应的类,并放到activation命名空间下:
2、LeNet-5模型的经典性
这里在介绍卷积伸神经网络模型时一直沿用LeNet-5模型,主要是因为它既结构简单又堪称CNN的经典之作,但在实际应用中卷积神经网络的层数可不止这些,举个例子,2014年的VGG模型已经将网络扩展到16层的深度,至于各大深度学习研究院内部已经将网络加深到多少层这个已经不得而知,总之一两块泰坦级别的N卡是不够用的。