页面缓存——内存与文件的那些事儿
转载:http://blog.csdn.net/drshenlei/article/details/4582197
原文标题:Page Cache, the Affair Between Memory and Files
原文地址:http://duartes.org/gustavo/blog/
[注:本人水平有限,只好挑一些国外高手的精彩文章翻译一下。一来自己复习,二来与大家分享。]
上次我们考察了内核如何为一个用户进程管理虚拟内存,但是没有涉及文件及I/O。这次我们的讨论将涵盖非常重要且常被误解的文件与内存间关系的问题,以及它对系统性能的影响。
提到文件,操作系统必须解决两个重要的问题。首先是硬盘驱动器的存取速度缓慢得令人头疼(相对于内存而言),尤其是磁盘的寻道性能。第二个是要满足‘一次性加载文件内容到物理内存并在程序间共享’的需求。如果你使用进程浏览器翻看Windows进程,就会发现大约15MB的共享DLL被加载进了每一个进程。我目前的Windows系统就运行了100个进程,如果没有共享机制,那将消耗大约1.5GB的物理内存仅仅用于存放公用DLL。这可不怎么好。同样的,几乎所有的Linux程序都需要ld.so和libc,以及其它的公用函数库。
令人愉快的是,这两个问题可以被一石二鸟的解决:页面缓存(page cache),内核用它保存与页面同等大小的文件数据块。为了展示页面缓存,我需要祭出一个名叫render的Linux程序,它会打开一个scene.dat文件,每次读取其中的512字节,并将这些内容保存到一个建立在堆上的内存块中。首次的读取是这样的:
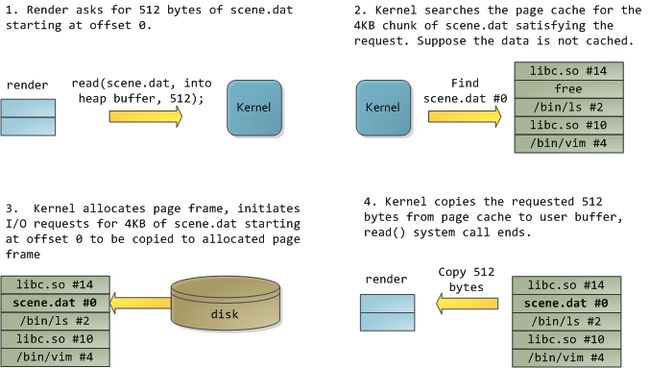
在读取了12KB以后,render的堆以及相关的页帧情况如下:

这看起来很简单,但还有很多事情会发生。首先,即使这个程序只调用了常规的read函数,此时也会有三个 4KB的页帧存储在页面缓存当中,它们持有scene.dat的一部分数据。尽管有时这令人惊讶,但的确所有的常规文件I/O都是通过页面缓存来进行的。在x86 Linux里,内核将文件看作是4KB大小的数据块的序列。即使你只从文件读取一个字节,包含此字节的整个4KB数据块都会被读取,并放入到页面缓存当中。这样做是有道理的,因为磁盘的持续性数据吞吐量很不错,而且一般说来,程序对于文件中某区域的读取都不止几个字节。页面缓存知道每一个4KB数据块在文件中的对应位置,如上图所示的#0, #1等等。与Linux的页面缓存类似,Windows使用256KB的views。
不幸的是,在一个普通的文件读取操作中,内核必须复制页面缓存的内容到一个用户缓冲区中,这不仅消耗CPU时间,伤害了CPU cache的性能,还因为存储了重复信息而浪费物理内存。如上面每张图所示,scene.dat的内容被保存了两遍,而且程序的每个实例都会保存一份。至此,我们缓和了磁盘延迟的问题,但却在其余的每个问题上惨败。内存映射文件(memory-mapped files)将引领我们走出混乱:
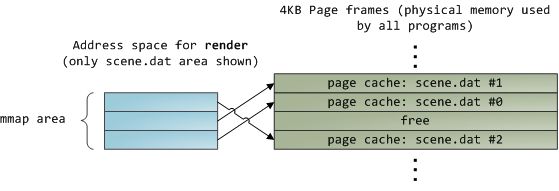
当你使用文件映射的时候,内核将你的程序的虚拟内存页直接映射到页面缓存上。这将导致一个显著的性能提升:《Windows系统编程》指出常规的文件读取操作运行时性能改善30%以上;《Unix环境高级编程》指出类似的情况也发生在Linux和Solaris系统上。你还可能因此而节省下大量的物理内存,这依赖于你的程序的具体情况。
和以前一样,提到性能,实际测量才是王道,但是内存映射的确值得被程序员们放入工具箱。相关的API也很漂亮,它提供了像访问内存中的字节一样的方式来访问一个文件,不需要你多操心,也不牺牲代码的可读性。回忆一下地址空间、还有那个在Unix类系统上关于mmap的实验,Windows下的CreateFileMapping及其在高级语言中的各种可用封装。当你映射一个文件时,它的内容并不是立刻就被全部放入内存的,而是依赖页故障(page fault)按需读取。在获取了一个包含所需的文件数据的页帧后,对应的故障处理函数会将你的虚拟内存页映射到页面缓存上。如果所需内容不在缓存当中,此过程还将包含磁盘I/O操作。
现在给你出一个流行的测试题。想象一下,在最后一个render程序的实例退出之时,那些保存了scene.dat的页面缓存会被立刻清理吗?人们通常会这样认为,但这是个坏主意。如果你仔细想想,我们经常会在一个程序中创建一个文件,退出,紧接着在第二个程序中使用这个文件。页面缓存必须能处理此类情况。如果你再多想想,内核何必总是要舍弃页面缓存中的内容呢?记住,磁盘比RAM慢5个数量级,因此一个页面缓存的命中(hit)就意味着巨大的胜利。只要还有足够的空闲物理内存,缓存就应该尽可能保持满状态。所以它与特定的进程并不相关,而是一个系统级的资源。如果你一周前运行过render,而此时scene.dat还在缓存当中,那真令人高兴。这就是为什么内核缓存的大小会稳步增加,直到缓存上限。这并非因为操作系统是破烂货,吞噬你的RAM,事实上这是种好的行为,反而释放物理内存才是一种浪费。缓存要利用得越充分越好。
由于使用了页面缓存体系结构,当一个程序调用write()时,相关的字节被简单的复制到页面缓存中,并且将页面标记为脏的(dirty)。磁盘I/O一般不会立刻发生,因此你的程序的执行不会被打断去等待磁盘设备。这样做的缺点是,如果此时计算机死机,那么你写入的数据将不会被记录下来。因此重要的文件,比如数据库事务记录必须被fsync() (但是还要小心磁盘控制器的缓存)。另一方面,读取操作一般会打断你的程序直到准备好所需的数据。内核通常采用积极加载(eager loading)的方式来缓解这个问题。以提前读取(read ahead)为例,内核会预先加载一些页到页面缓存,并期待你的读取操作。通过提示系统即将对文件进行的是顺序还是随机读取操作(参看madvise(), readahead(), Windows缓存提示),你可以帮助内核调整它的积极加载行为。Linux的确会对内存映射文件进行预取,但我不太确定Windows是否也如此。最后需要一提的是,你还可以通过在Linux中使用O_DIRECT或在Windows中使用NO_BUFFERING来绕过页面缓存,有些数据库软件就是这么做的。
一个文件映射可以是私有的(private)或共享的(shared)。这里的区别只有在更改(update)内存中的内容时才会显现出来:在私有映射中,更改并不会被提交到磁盘或对其他进程可见,而这在共享的映射中就会发生。内核使用写时拷贝(copy on write)技术,通过页表项(page table entries),实现私有映射。在下面的例子中,render和另一个叫render3d的程序(我是不是很有创意?)同时私有映射了scene.dat。随后render改写了映射到此文件的虚拟内存区域:

上图所示的只读的页表项并不意味着映射是只读的,它们只是内核耍的小把戏,用于共享物理内存直到可能的最后一刻。你会发现‘私有’一词是多么的不恰当,你只需记住它只在数据发生更改时起作用。此设计所带来的一个结果就是,一个以私有方式映射文件的虚拟内存页可以观察到其他进程对此文件的改动,只要之前对这个内存页进行的都是读取操作。一旦发生过写时拷贝,就不会再观察到其他进程对此文件的改动了。此行为不是内核提供的,而是在x86系统上就会如此。另外,从API的角度来说,这也是合理的。与此相反,共享映射只是简单的映射到页面缓存,仅此而已。对页面的所有更改操作对其他进程都可见,而且最终会执行磁盘操作。最后,如果此共享映射是只读的,那么页故障将触发段错误(segmentation fault)而不是写时拷贝。
被动态加载的函数库通过文件映射机制放入到你的程序的地址空间中。这里没有任何特别之处,同样是采用私有文件映射,跟提供给你调用的常规API别无二致。下面的例子展示了两个运行中的render程序的一部分地址空间,还有物理内存。它将我们之前看到的概念都联系在了一起。
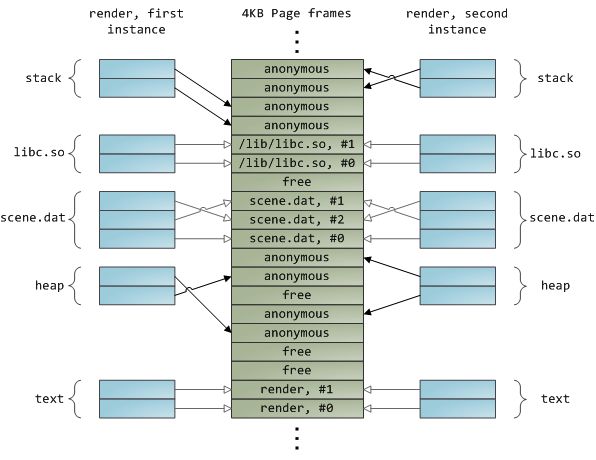
至此我们完成了内存基础知识的三部曲系列。我希望这个系列对您有用,并在您头脑中建立一个好的操作系统模型。