浅析SNN,CN,BN,HA,Federation
一、SecondaryNameNode
Secondary NameNode不是NameNode的备份。它的作用是:定期合并fsimage与edits文件,并推送给NameNode,以及辅助恢复NameNode。
SNN的作用现在(Hadoop2.x)可以被两个节点替换CheckpointNode和BackupNode。
CheckpointNode可以理解为与Secondary NameNode的作用一致。
BackupNode:NameNode的完全备份。
配置文件:core-site.xml
fs.checkpoint.period、fs.checkpoint,size、
fs.checkpoint.dir、fs.checkpoint.edits.dir
Secondary NameNode定期合并流程,如下图所示。 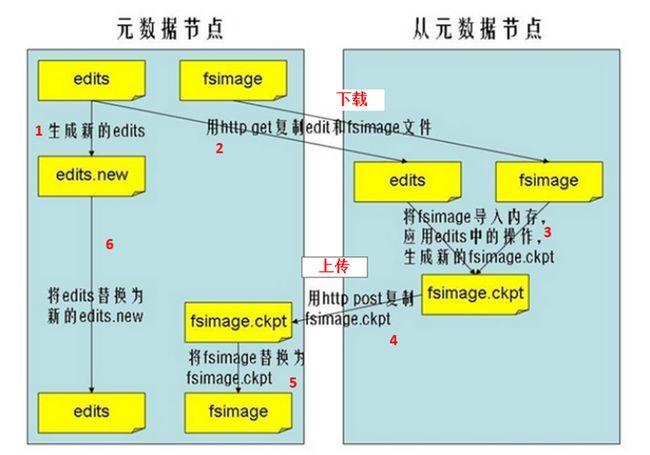
[root@master current]# more VERSION#Mon May 04 15:06:37 CST 2015namespaceID=1967523381clusterID=CID-bdf70043-346a-439b-87de-cee402d13fa4cTime=0storageType=NAME_NODEblockpoolID=BP-510666760-172.23.253.20-1430213820023layoutVersion=-47
VERSION文件保存了HDFS的版本号
layoutVersion是一个负整数,保存了HDFS的持续化在硬盘上的数据
结构的格式版本号
namespaceID是文件系统的唯一标识符,在文件系统初次格式化时生成的。
cTime此处为0
storageType表示此文件夹中保存的是元数据节点的数据结构
NameNode进程死了,并且存放NameNode元数据信息目录下的数据丢失了,怎么恢复?
1、删除SNN存放数据目录下in_use.lock文件
2、执行恢复命令hadoop namenode -importCheckpoint
3、启动namenodehadoop-daemon.sh start namenode
4、进行校验检查根目录是否健康hadoop fsck /
5、查看数据hadoop fs -lsr /
至此,NameNode元数据恢复成功。
二、CheckpointNode
CheckpointNode和SecondaryNameNode的作用以及配置完全相同。
启动命令:hdfs namenode -checkpoint
配置文件:core-site.xml
fs.checkpoint.period、fs.checkpoint,size、
fs.checkpoint.dir、fs.checkpoint.edits.dir
三、BackupNode
提供了一个真正意义上的备用节点。
BackupNode在内存中维护了一份从NameNode同步过来的fsimage,同时它还从namenode接收edits文件的日志流,并把它们持久化硬盘。
BackupNode在内存中维护与NameNode一样的Matadata数据。
启动命令:hdfs namenode -backup
配置文件:hdfs-site.xml
dfs.backup.address、dfs.backup.http.address
[root@master current]# hdfs namenode --helpUsage: java NameNode [-backup] | [-checkpoint] | [-format [-clusterid cid ] [-force] [-nonInteractive] ] | [-upgrade] | [-rollback] | [-finalize] | [-importCheckpoint] | [-initializeSharedEdits] | bootstrapStandby] | [-recover [ -force ] ]
四、HDFS HA的自动failover
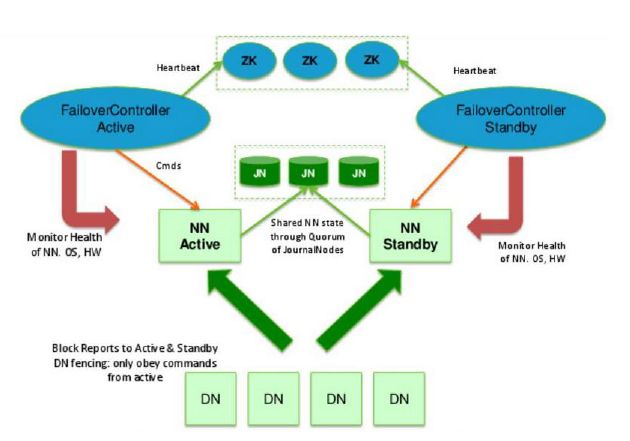
HDFS的HA,指的是在一个集群中存在两个NameNode, 分别运行在独立的物理节点上。在任何时间点, 只有一个NameNodes是处于Active状态,另一种是在Standby状态。
Active NameNode负责所有的客户端的操作,而Standby NameNode用来同步Active NameNode的状态信息,以提供快速的故障恢复能力。
为了保证Active NN与Standby NN节点状态同步,即元数据保持一致。除了DataNode需要向两个NN发送block位置信息外,还构建了一组独立的守护进程”JournalNodes” ,用来同步FsEdits信息。当Active NN执行任何有关命名空间的修改,它需要持久化到一半以上的JournalNodes上。而Standby NN负责观察JNs的变化,读取从Active NN发送过来的FsEdits信息,并更新其内部的命名空间。
一旦Active NN遇到错误, Standby NN需要保证从JNs中读出了全部的
FsEdits, 然后切换成Active状态。
在这个图里,我们可以看出HA的大致架构,其设计上的考虑包括:
利用共享存储来在两个NN间同步edits信息。
以前的HDFS是share nothing but NN,现在NN又share storage,这样其实是转移了单点故障的位置,但中高端的存储设备内部都有各种RAID以及冗余硬件包括电源以及网卡等,比服务器的可靠性还是略有提高。
通过NN内部每次元数据变动后的flush操作,加上NFS的close-to-open,数据的一致性得到了保证。社区现在也试图把元数据存储放到BookKeeper上,以去除对共享存储的依赖, Cloudera也提供了Quorum Journal Manager(QJM)的实现和代码。
DataNode同时向两个NN汇报块信息。这是让Standby NN保持集群最新状态的必需步骤。
用于监视和控制NN进程的FailoverController进程,显然,我们不能在NN进程内进行心跳等信息同步,最简单的原因,一次FullGC就可以让NN挂起
十几分钟,所以,必须要有一个独立的短小精悍的watchdog来专门负责监控。这也是一个松耦合的设计,便于扩展或更改,目前版本里是用ZooKeeper(以下简称ZK)来做同步锁,但用户可以方便的把这个ZooKeeper FailoverController(以下简称ZKFC)替换为其他的HA方案或leader选举
方案。
隔离(Fencing),防止脑裂,就是保证在任何时候只有一个主NN,包括三个方面:
共享存储fencing,确保只有一个NN可以写入edits。
客户端fencing,确保只有一个NN可以响应客户端的请求。
DataNode fencing,确保只有一个NN可以向DN下发命令,譬如删除块,复制块等等。
五、HDFS2的Federation
HDFS Federation设计可解决单一命名空间存在的以下几个问题:
1 、HDFS集群扩展性。多个NameNode分管一部分目录,使得一个集群可以扩展到更多节点,不再像Hadoop1.x中那样由于内存的限制制约文件存储数目。
2、性能更高效。多个NameNode管理不同的数据,且同时对外提供服务,将为用户提供更高的读写吞吐率。
3、良好的隔离性。用户可根据需要将不同业务数据交由不同NameNode管理,这样不同业务之间影响很小。
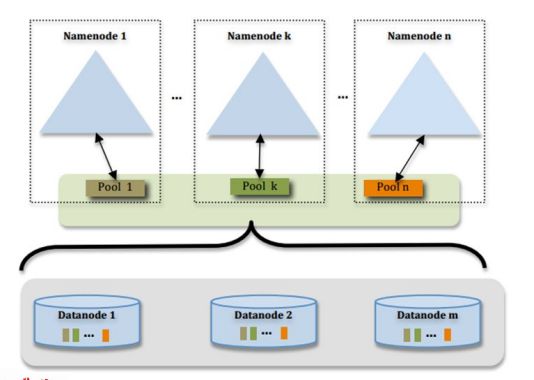
由上图,我们可以看到多个NN共用一个集群里DN上的存储资源,每个NN都可以单独对外提供服务每个NN都会定义一个存储池,有单独的id,每个DN都为所有存储池提供存储。
DN会按照存储池id向其对应的NN汇报块信息,同时, DN会向所有NN汇报本地存储可用资源情况
如果需要在客户端方便的访问若干个NN上的资源,可以使用客户端挂载表,把不同的目录映射到不同的NN,但NN上必须存在相应的目录。
这样设计的好处有:
改动最小,向前兼容。
现有的NN无需任何配置改动。
如果现有的客户端只连某台NN的话,代码和配置也无需改动。
分离命名空间管理和块存储管理。
提供良好扩展性的同时允许其他文件系统或应用直接使用块存储池。
统一的块存储管理保证了资源利用率。
可以只通过防火墙配置达到一定的文件访问隔离,而无需使用复杂的Kerberos认证
客户端挂载表通过路径自动对应NN使Federation的配置改动对应用透明。