Mahout安装与第一次使用--用户协同过滤
1.下载Mahout
http://archive.apache.org/dist/mahout/
因为我用的是Ubuntu,所以下载的是
2.解压缩
下载之后存在/home/user/Downloads目录下(具体的user可以根据自己的用户名做更改),我希望它解压缩到/home/user/目录下,所以命令如下,注意,-C选项后的目录必须要是存在的,要不就会报错的哦。
解压缩之后,在/home/user目录下就会出现mahout目录啦。
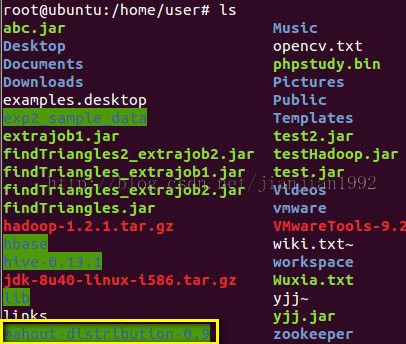
3.环境变量的配置
修改环境变量我喜欢修改/etc/profile文件
如下图所示,在profile文件的最后加入MAHOUT_HOME,MAHOUT_CONF_DIR,HADOOP_HOME,HADOOP_CONF_DIR以及PATH
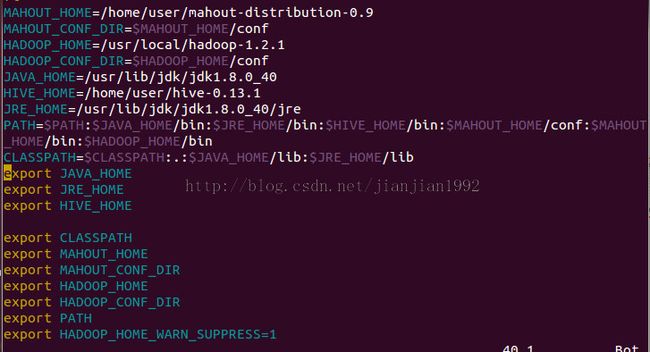
修改好之后不要忘记了最重要的一步,就是让profile重新生效一下。
所以要用source命令,要不然mahout命令是识别不了的哦
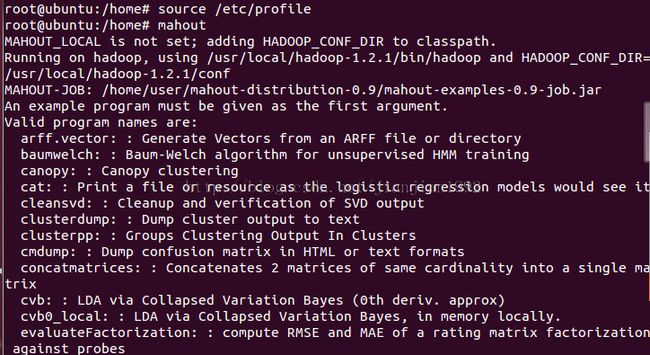
4.测试mahout命令
直接输入mahout命令,出现如下所示画面,就ok啦!
5.使用命令行的方式生成maven项目
可以使用命令行方式生成,不过我还是觉得使用eclipse直接生成maven项目更方便,可以参考 http://blog.csdn.net/jianjian1992/article/details/46957811
root@ubuntu:/home/user# mvn archetype:generate -DarchetypeGroupId=org.apache.maven.archetypes
root@ubuntu:/home/user# whereis eclipse
eclipse: /usr/lib/eclipse
eclipse: /usr/lib/eclipse
下面使用generate方式的命令生成项目ok!
-DartifactId=myMahout
-DgroupId=com.mavendemo.maventest
-Dversion=1.0
是三个要填写的参数,artifactId是项目名,groupId则是包名,version是版本号。
root@ubuntu:/home/user/workspace# mvn archetype:generate -DgroupId=com.mavendemo.maventest -DartifactId=myMahout -Dversion=1.0
如下使用create的方式创建会报错:
root@ubuntu:/home/user/workspace# mvn archetype:create -DgroupId=com.mavendemo.maventest -DartifactId=myMahout
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-archetype-plugin:2.3:create (default-c
li) on project standalone-pom: Unable to parse configuration of mojo org.apache.maven.plugins:maven-
archetype-plugin:2.3:create for parameter #: Cannot create instance of interface org.apache.maven.ar
tifact.repository.ArtifactRepository
li) on project standalone-pom: Unable to parse configuration of mojo org.apache.maven.plugins:maven-
archetype-plugin:2.3:create for parameter #: Cannot create instance of interface org.apache.maven.ar
tifact.repository.ArtifactRepository
生成项目的过程选择默认项就ok,关于各个选择的具体意义
可以参考http://www.cnblogs.com/yjmyzz/p/3495762.html
最后出现如下图就表示创建项目成功啦!
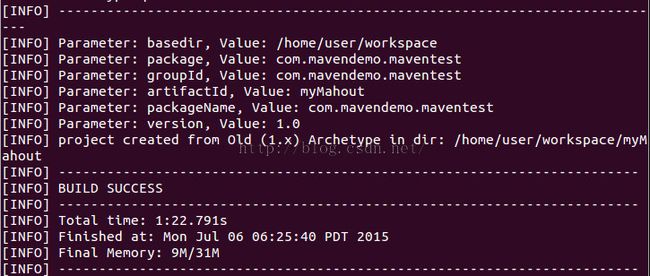
最后把这个项目的权限改一下
root@ubuntu:/home/user/workspace# chmod -R 777 myMahout
maven在Eclipse下的安装
将创建的maven项目导入到eclipse中。
之后需要修改
pom.xml
为了把mahout加进去,需要在<Properties></Propreties>里边把mahout的版本信息加进去,也就是
<mahout.version>0.9</mahout.version>
当然啦,mahout的系统变量也是早就加好了的啊!
然后就是在依赖项里边把需要加进去的包写上,依赖项写在<dependencies> /<dependencies>之间。
每个依赖项用<dependency></dependency>包含起来,
包括groupId,artifactId,version,scope四个属性
</pre><pre name="code" class="html"><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>yjj</groupId>
<artifactId>maven-mahout</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>maven-mahout</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<mahout.version>0.9</mahout.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-core</artifactId>
<version>0.9</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-integration</artifactId>
<version>0.9</version>
<scope>compile</scope>
<exclusions>
<exclusion>
<artifactId>jetty</artifactId>
<groupId>org.mortbay.jetty</groupId>
</exclusion>
<exclusion>
<artifactId>cassandra-all</artifactId>
<groupId>org.apache.cassandra</groupId>
</exclusion>
<exclusion>
<artifactId>hector-core</artifactId>
<groupId>me.prettyprint</groupId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
</project>
设置好pom.xml之后,在命令行里边进入工程目录,运行$mvn clean install命令,然后就可以把依赖项加进去啦。刷新一下工程ok!
比如说<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-core</artifactId>
<version>0.9</version>
<scope>compile</scope>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-core</artifactId>
<version>0.9</version>
<scope>compile</scope>
加进来之后如图所示
七.用户协同过滤推荐的使用
这次试验一下单机版的mahout编程,不需要使用到hdfs以及hadoop。
单机版的mahout会使用多线程充分利用单机的并行资源。
数据如下,三列分别如下所示:
用户id,物品id,用户对物品的评价喜好
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0
在项目的src/main/java包下面新建个类UserCF.java,用来编写基于用户协同过滤的推荐。
基于用户协同过滤的推荐算法可以简单描述为:
1.首先数据中有用户对各个物品的评价或喜好
比如上面的数据,我们便可以得到一个5*7的喜好矩阵
user id1 5.000000 3.000000 2.500000 0.000000 0.000000 0.000000 0.000000 user id2 2.000000 2.500000 5.000000 2.000000 0.000000 0.000000 0.000000 user id3 2.500000 0.000000 0.000000 4.000000 4.500000 0.000000 5.000000 user id4 5.000000 0.000000 3.000000 4.500000 0.000000 4.000000 0.000000 user id5 4.000000 3.000000 2.000000 4.000000 3.500000 4.000000 0.000000
2.根据两个用户比如1和2对物品的评价,可以计算他们之间的距离,计算距离的方式有很多种,这里采用欧式距离。
之和依次计算各个用户之间的距离。
3.得到各个用户之间的距离之和,便可以得到用户的最近邻,设定最近邻的个数,然后便可以根据最近邻的喜好来对用户没有评价过的item进行推荐了。
所以编写推荐算法代码的话,主要有几个部分:
- 数据模型DataModel,即存取数据的模型
- 用户之间相似性模型UserSimilarity,计算用户之间的距离,距离越小越相似
- 用户的最近邻NearestNUserNeighborhood,设定最近邻的选择方式
- 推荐算法模型UserBasedRecommender
代码如下:
public class UserCF {
final static int NEIGHBORHOOD_NUM = 3;
final static int RECOMMENDER_NUM = 2;
public static void main(String[] args) throws IOException, TasteException {
String file = "item.csv";//数据文件
DataModel model = new FileDataModel(new File(file));//创建数据模型
UserSimilarity user = new EuclideanDistanceSimilarity(model);//采用欧式距离计算相似度
NearestNUserNeighborhood neighbor = new NearestNUserNeighborhood(NEIGHBORHOOD_NUM, user, model);//设定最近邻选取个数
UserBasedRecommender r = new GenericUserBasedRecommender(model, neighbor, user);//生成基于用户的推荐模型
LongPrimitiveIterator iter = model.getUserIDs();
//遍历每个用户
while (iter.hasNext()) {
long uid = iter.nextLong();
List<RecommendedItem> list = r.recommend(uid, RECOMMENDER_NUM);//为用户uid生成RECOMMENDER_NUM个推荐
System.out.printf("uid:%s", uid);//输出推荐物品id以及预测uid对它的喜好度
for (RecommendedItem ritem : list) {
System.out.printf("(%s,%f)", ritem.getItemID(), ritem.getValue());
}
System.out.println();
}
}
因为是单机mahout,直接运行就可以了,不需要开启hadoop。
结果如下:
uid:1(106,4.000000)(104,3.853723) uid:2(105,4.055916) uid:3(106,4.000000)(103,3.258251) uid:4(105,3.884381)(102,3.000000) uid:5
下面来具体分析一下这个算法的运行过程
构造出这个5*7的喜好矩阵
首先从DataModel里边构造出这个5*7的喜好矩阵,关于DataModel提供的接口可以从mahout的docs目录里边import org.apache.mahout.cf.taste.impl.model.file.FileDataModel进行查找。
挺好玩的是这个包叫cf.taste。
double[][] a = new double[5][7];//首先创建一个5*7的二维数组,这样创建好以后数组中各个元素自动就初始化为了0哦!
//从DataModel里边得到UserIDs和ItemIds都是以LongPrimitiveIterator的形式保存的,之后用迭代器的方式一一访问。
LongPrimitiveIterator iterUser = model.getUserIDs();
while (iterUser.hasNext()) {
long uid = iterUser.nextLong();
FastIDSet items = model.getItemIDsFromUser(uid);
long[] lItems = items.toArray();
for (int i = 0; i < lItems.length; i++){
int itemid = (int)lItems[i];
a[(int) uid - 1][(itemid-100-1)] = model.getPreferenceValue(uid, itemid);
}
}
for (int i = 0; i < 5; i++){
System.out.print("user id" + (i+1) + " ");
for (int j = 0; j < 7; j++){
System.out.printf("%f\t", a[i][j]);
}
System.out.println();
}
FastIDSet是mahout自定义的一个类似于HashSet的集合
下面这一段摘自 http://www.aboutyun.com/thread-10906-1-1.html
内存问题
FastIDSet的每个元素平均占14字节, 而HashSet而需要84字节;
* 和 HashMap一样, FastByIDMap也是基于 hash的。不过 FastByIDMap使用的是线性探测来解决 hash冲突, 而不是分割链;
Java自带的HashMap和HashSet占用内存较大, 因此Mahout对这两个常用的数据结构也做了为减少内存开销的精简实现。
FastIDSet的每个元素平均占14字节, 而HashSet而需要84字节;
FastByIDMap的每个Entry占28字节, 而HashMap则需要84字节。
改进如此显著的原因在于:
* 和 HashMap一样, FastByIDMap也是基于 hash的。不过 FastByIDMap使用的是线性探测来解决 hash冲突, 而不是分割链;
*
FastByIDMap的key和值都是
long类型, 而不是
Object, 这是基于节省内存开销和改善性能所作的改良;
*
FastByIDMap类似于一个缓存区, 它有一个
maximum size的概念, 当我们添加一个新元素的时候, 如果超过了这个size, 那些使用不频繁的元素就会被移除。
用户之间的距离
使用如下函数来计算用户之间的欧式距离。
这里有个问题,对于不同的用户来说,它们对同一件item,很可能一个有评价,一个没有评价,那怎么计算距离呢?
我认为计算两个用户之间的距离,只有当他们对同一个item都有评价的时候才有意义,所以我下面的距离只计算两个用户之间共同评价过的item的欧式距离。
如果两个用户之间没有任何交集,则返回最大距离。
public static double getDis(double[][] a, int id1, int id2){
double ret = 0;
double num = 0;
for (int i = 0; i < 7; i++){
double d1 = a[id1][i], d2 = a[id2][i];
if (d1 != 0 && d2 != 0){
double dSub = d1 - d2;
ret += dSub * dSub;
num += 1.0;
}
}
if (num != 0)
return (Math.sqrt(ret/num));
else
return Double.MAX_VALUE;
}之后计算5个用户之间的距离并输出
double[][] dis = new double[5][5];
for (int i = 0; i < 5; i++){
for (int j = 0; j < 5; j++){
dis[i][j] = getDis(a, i, j);
System.out.printf("%f\t", dis[i][j]);
}
System.out.println();
}得到结果如下:
0.000000 2.273030 2.500000 0.353553 0.645497 2.273030 0.000000 1.457738 2.533114 2.076656 2.500000 1.457738 0.000000 1.802776 1.040833 0.353553 2.533114 1.802776 0.000000 0.750000 0.645497 2.076656 1.040833 0.750000 0.000000为了验证下结果,用推荐模型来看看它对每个用户给出的最近邻情况是否满足上面情况
for (int i = 1; i <= 5; i++){
long[] users = r.mostSimilarUserIDs(i, 4);
System.out.println(users[0] + ":" + users[1] + ":" + users[2] + ":" + users[3]);
}结果为
4:5:2:3 3:5:1:4 5:2:4:1 1:5:3:2 1:4:3:2与上面的距离矩阵的结果正好相符哦!