Spring Batch(7): 并行与扩展
1. 概述
Spring Batch提供了多种方式用于处理并行,提高性能。主要分为2大类:
- 单个进程,多线程
- 多个进程
因此,可以细分为以下几类:
- 多线程Step(Multi-thread Step,single process)
- 并行Step(Parallel Steps, single process )
- Remote Chunking of Step( multi process)
- Partitioning a step(single or multi process)
2. Multi-Thread Step
最直接的方式是给Step配置一个TaskExecutor
<step id="loading">
<tasklet task-executor="taskExecutor">...</tasklet>
</step>此时,taskExecutor的线程并行来执行Item处理(统一item的read,process,write在同一个线程中执行)。可以限制TaskExecutor的阈值(默认为4):
<step id="loading"> <tasklet
task-executor="taskExecutor"
throttle-limit="20">...</tasklet>
</step>需要注意的是,在多线程Step中,需要确保Reader、Processor和Writer是线程安全的,否则容易出现并发问题。Spring Batch提供的大部分组件都是非线程安全的,他们都保存有部分状态信息,主要是为了支持任务重启。
因此,使用多线程Step的核心任务是实现无状态化,例如不保存当前读取的item的cursor,而是同item的flag字段来区分item是否被处理过,已经被处理过的下次重启的时候,直接被过滤掉。
多线程Step实现的是单个Step的多线程化。
3. Parallel Steps
如果多个Step没有先后关系,可以并行执行,这是通过split和flow来实现的:
<job id="job1">
<split id="split1" task-executor="taskExecutor" next="step4">
<flow>
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>
</flow>
<flow>
<step id="step3" parent="s3"/>
</flow>
</split>
<step id="step4" parent="s4"/>
</job>
<beans:bean id="taskExecutor" class="org.spr...SimpleAsyncTaskExecutor"/>该种模式提供的是多个Step的并行处理。
4. Remote Chunking
Remote chunking 的示意图如下:
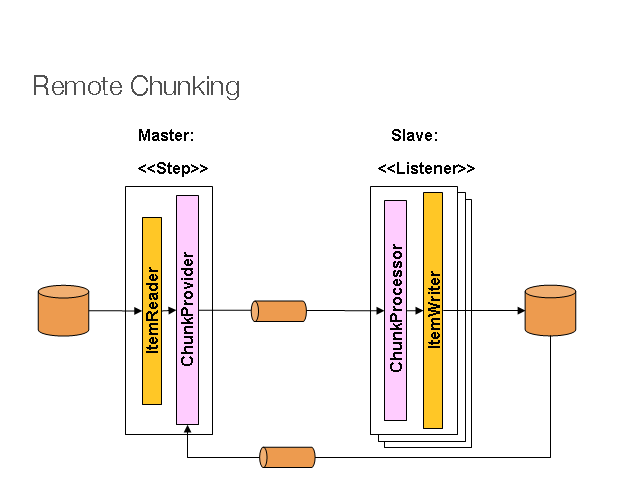
Master为单个进程,因此只有在处理所需要的时间远远大于读取所需要的时间的时候,这个方式才适用,否则Master容易成为瓶颈。
Master是一个常规的Step实现,只不过它的ItemWriter知道如何将Items分块,并发送到中间件(例如JMS),通过实现ChunkProvider接口来实现。
public interface ChunkProvider<T>{
Chunk<T> provide(StepContribution contribution) throws Exception;
void postProcess(StepContribution contribution, Chunk<T> chunk);
}Slave则充当中间件的Listener,通过ItemProcessor和ItemWriter来实现item处理,具体的是通过实现ChunkProcessor接口
public interface ChunkProcessr<T> {
void process(StepContribution contribution,Chunk<T> chunk) throws Exception;
}可以看到,remote chunking实现的是(Processor、Writer)的并行化。分区不需要对数据源的结构有很明确的了解。
5. Partitioning
Step分区处理示意图如下:
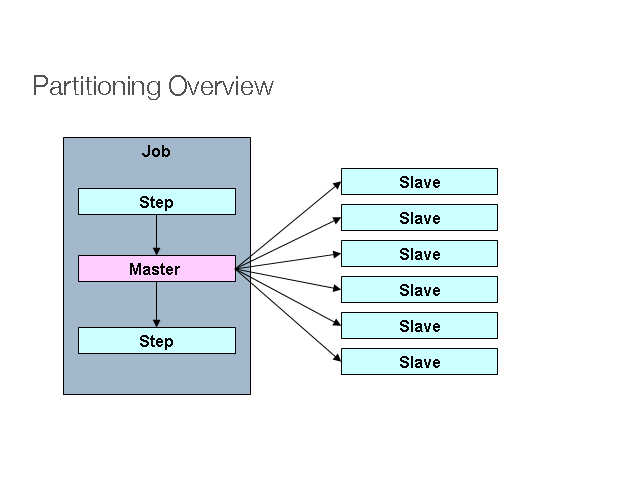
一个分区配置如下:
<step id="step1.master">
<partition step="step1" partitioner="partitioner">
<handler grid-size="10" task-executor="taskExecutor"/>
</partition>
</step>
<step id="step1">
<tasklet>
<chunk reader="" writer"" processor="" .../>
</tasklet>
</step>主要包括2个步骤:
1. 数据分区
2. 分区处理
具体的分区执行流程如下:
PartitionHandler
其中PartitionHandler知道集群环境,根据下面要介绍的Splitter进行分区,发送执行请求(通过WebService ,RMI等方式) 并收集执行结果,聚合,最终反馈给Job。Spring Batch提供了一个同一台机器上的Handler实现,在同一机器上创建多个Step Execution。
<step id="step1.master">
<partition step="step1" handler="handler"/>
</step>
<bean class="org.spr...TaskExecutorPartitionHandler">
<property name="taskExecutor" ref="taskExecutor"/>
<property name="step" ref="step1" />
<property name="gridSize" value="10" />
</bean>Partitioner
Partitioner负责生成执行上下文,作为Step Execution的输入参数,其接口定义如下:
public interface Partitioner {
Map<String, ExecutionContext> partition(int gridSize);
}返回结果中Map的key,是一个唯一的名字,常见的实现方式是step_name + counter。或者通过PartitioneNameProvider来提供。 名字关联到对应的执行上下文。ExecutionContext只是一个key/value容器,因此它可能包含主键范围,行数等信息。
StepExecutionSplitter
Partitioner生成的ExecutionContext,经过StepExecutionSplitter处理之后形成StepExecution,然后交给Handler处理。StepExecutionSplitter接口定义如下:
public interface StepExecutionSplitter {
String getStepName();
Set<StepExecution> split(StepExecution stepExecution , int gridSize)
throws JobExecutionException;
}通常,Slave中的Step配置都是相同的,他们通过获取Partitioner划分好的ExecutionContext,获取Step的输入参数,动态绑定到Step中。例如划分的情况如下表:
| step execution name(key) | ExecutionContext(value) |
|---|---|
| filecopy:partition0 | file_name=/home/data/0 |
| filecopy:partition1 | file_name=/home/data/1 |
| filecopy:partition2 | file_name=/home/data/2 |
然后该文件名被绑定到Step的组件中:
<bean id="itemReader" scope="step"
class="org.spr...MultiResourceItemReader">
<property name="resource" value="#{stepExecutionContext[file_name]}/*"/>
</bean>整个具体流程如下:
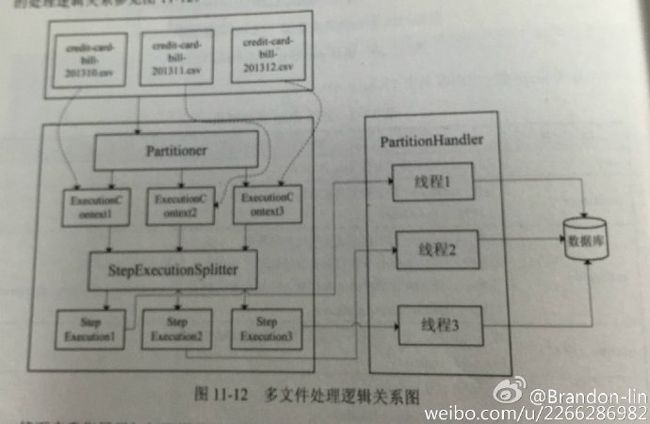
可以看出,Patitioning提供的是(Reader、Processor、Writer)的并行化。分区模式需要对数据源的结构有一定的了解,比如知道主键范围。