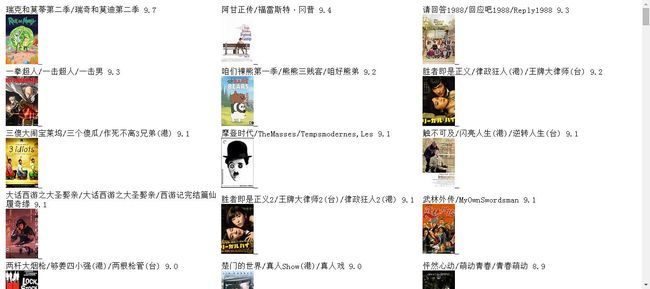
Pyhton抓取豆瓣电影示例
BeautifulSoup抓取豆瓣电影信息 #
Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree)。 它提供简单又常用的导航(navigating),搜索以及修改剖析树的操作。它可以大大节省你的编程时间。
BeautifulSoup4的安装
一、使用pip直接安装beautifulsoup4
F:\demo>pip install beautifulsoup4
Collecting beautifulsoup4
Downloading beautifulsoup4-4.4.0-py3-none-any.whl (80kB)
328kB/s
Installing collected packages: beautifulsoup4
Successfully installed beautifulsoup4-4.4.0
F:\demo>或者从官网下载Beautifulsoup的软件包,然后解压,cmd命令行进入解压包目录,输入以下命令安装:python setup.py install
网络爬虫实例代码,抓取新浪爱彩双色球开奖数据实例代码:
from bs4 import BeautifulSoup
import re
import urllib.request, urllib.parse, http.cookiejar
def getHtml(url):
cj = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
opener.addheaders = [('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.101 Safari/537.36'),('Cookie', '4564564564564564565646540')]
urllib.request.install_opener(opener)
html_bytes = urllib.request.urlopen(url).read()
html_string = html_bytes.decode('utf-8')
return html_string
html_doc = getHtml("http://zst.aicai.com/ssq/openInfo/")
soup = BeautifulSoup(html_doc, 'html.parser')
tr = soup.find('tr',attrs={"onmouseout": "this.style.background=''"})
#print(tr)
tds = tr.find_all('td')
opennum = tds[0].get_text() #彩票期号
time = tds[1].get_text() #开奖时间
reds = []
for i in range(2,8):
reds.append(tds[i].get_text())
#print(reds) 前面开出的普通号码
blue = tds[8].get_text() #特殊号码
print(opennum+'期开奖号码:'+ (',').join(reds)+", 蓝球:"+blue+", 开奖时间 :"+time)
$ python hello.py
2016009期开奖号码:10,14,24,25,27,32, 蓝球:04, 开奖时间 :2016-01-21soup = BeautifulSoup(html_doc)
soup 就是BeautifulSoup处理格式化后的字符串,soup.title 得到的是title标签,soup.p 得到的是文档中的第一个p标签,要想得到所有标签,得用find_all
函数。find_all 函数返回的是一个序列,可以对它进行循环,依次得到想到的东西.
get_text() 是返回文本,这个对每一个BeautifulSoup处理后的对象得到的标签都是生效的。你可以试试 print soup.p.get_text()
其实是可以获得标签的其他属性的,比如我要获得a标签的href属性的值,可以使用 print soup.a[‘href’],类似的其他属性,比如class也是可以这么得到的(soup.a[‘class’])。
特别的,一些特殊的标签,比如head标签,是可以通过soup.head 得到,其实前面也已经说了。
如何获得标签的内容数组?使用contents 属性就可以 比如使用 print soup.head.contents,就获得了head下的所有子孩子,以列表的形式返回结果
下面就开始进行一个小的实战操作,http://movie.douban.com/tag/%E5%96%9C%E5%89%A7 这个是豆瓣电影中的喜剧电影页面,我们就对这个页面操作,获取喜剧电影中评分最高的100个电影。
对这个页面需要提取两个信息:1、翻页链接;2、每部电影的信息(外链,图片,评分、简介、标题等)
当我们提取到所有电影的信息后再按评分进行排序,选出最高的即可,这里贴出翻页提取和电影信息提取的代码
from bs4 import BeautifulSoup
import urllib.request
import re
import urllib.parse, http.cookiejar
import sys
#定义程序运行过程中的日志函数
def LOG(*argv):
sys.stderr.write(*argv)
sys.stderr.write('\n')
class Grab():
url = ''
soup = None
#读取当前网页的源代码数据返回
def GetPage(self, url):
if url.find('http://',0,7) != 0:
url = 'http://' + url
self.url = url
LOG('input url is: %s' % self.url)
req = urllib.request.Request(url, headers={'User-Agent' : "Magic Browser"})
try:
page = urllib.request.urlopen(req)
except:
return
return page.read()
#解析当前页面数据并将所需要的数据通过列表元祖返回
def ExtractInfo(self,buf):
try:
#buf是传入的网页源代码,通过BeautifulSoup函数返回修正过的数据
self.soup = BeautifulSoup(buf,'html.parser')
except:
LOG('soup failed in ExtractInfo :%s' % self.url)
return
try:
#分析豆瓣电影网页中的代码,每个电影信息都被单独的放到一个item类中
items = self.soup.findAll(attrs={'class':'item'})
except:
LOG('failed on find items:%s' % self.url)
return
links = [] #电影的详细页面
objs = [] #电影的图片地址
titles = [] #电影名称
scores = [] #电影当前获取分数
comments = [] #评论
intros = [] #简单介绍
for item in items:
try:
pic = item.find(attrs={'class':'nbg'})
link = pic['href']
obj = pic.img['src']
info = item.find(attrs={'class':'pl2'})
title = re.sub('[ \t]+',' ',info.a.getText().replace(' ','').replace('\n',''))
star = info.find(attrs={'class':'star clearfix'})
score = star.find(attrs={'class':'rating_nums'}).getText().replace(' ','')
comment = star.find(attrs={'class':'pl'}).getText().replace(' ','')
intro = info.find(attrs={'class':'pl'}).getText().replace(' ','')
except Exception as e:
LOG('process error in ExtractInfo: %s' % self.url)
continue
links.append(link)
objs.append(obj)
titles.append(title)
scores.append(score)
comments.append(comment)
intros.append(intro)
return [links, objs, titles, scores, comments, intros]
#获取所有相邻页面url
def ExtractPageTurning(self,buf):
links = set([])
if not self.soup:
try:
self.soup = BeautifulSoup(buf,'html.parser')
except:
LOG('soup failed in ExtractPageTurning:%s' % self.url)
return
try:
pageturning = self.soup.find(attrs={'class':'paginator'})
a_nodes = pageturning.findAll('a')
for a_node in a_nodes:
href = a_node['href']
if href.find('http://',0,7) == -1:
href = self.url.split('?')[0] + href
links.add(href)
except:
LOG('get pageturning failed in ExtractPageTurning:%s' % self.url)
return set(links)
def Destroy(self):
del self.soup
self.soup = None
grab = Grab()
#添加网页文件的格式
file_object = open('info.html', 'w+')
file_object.write('<html><body><center><table>\r\n')
#buf是当前页面经过转换之后的源代码
buf = grab.GetPage('http://movie.douban.com/tag/%E5%96%9C%E5%89%A7')
if not buf:
print('GetPage failed!')
sys.exit()
#pageturning是当前页面相关连接的集合
pageturning = grab.ExtractPageTurning(buf)
pageturning.add('http://movie.douban.com/tag/%E5%96%9C%E5%89%A7')
links=[]
objs=[]
titles=[]
comments=[]
intros=[]
scores=[]
for page in pageturning:
buf = grab.GetPage(page)
[link, obj, title, score, comment, intro]= grab.ExtractInfo(buf)
print()
links+=link
objs+=obj
titles+=title
scores+=score
comments+=comment
intros+=intro
#zip函数返回一个可迭代的元组,是一个zip object而非直接的元组
tu=zip(links, objs, titles, scores, comments, intros)
tu1=[]
#将zip对象中的数据一次添加到序列中
for link, obj, title, score, comment, intro in tu:
item=[link, obj, title, score, comment, intro]
tu1.append(item)
#将列表转换成为元组
tu1=tuple(tu1)
#将每个条目按照电影的豆瓣评分重新降序排序
tu1=sorted(tu1,key=lambda t:t[3],reverse = True)
index=0
for link, obj, title, score, comment, intro in tu1:
if index%3==0 and(index+1)%6!=0:
file_object.write('<tr>')
file_object.write('<td>')
str=title+' '+score+'<br>\r\n <a href='+link+'><img src='+obj+'> </img></a>\r\n';
file_object.write(str.encode('gbk','ignore').decode('gbk'))
file_object.write('<br></td>')
if (index+1)%6==0 :
file_object.write('</tr>')
index+=1
grab.Destroy()
file_object.write('</table><center></body><html>')
file_object.close( )
#运行情况
$ python hello.py
input url is: http://movie.douban.com/tag/%E5%96%9C%E5%89%A7
input url is: http://movie.douban.com/tag/%E5%96%9C%E5%89%A7?start=7880&type=T
input url is: http://movie.douban.com/tag/%E5%96%9C%E5%89%A7
input url is: http://movie.douban.com/tag/%E5%96%9C%E5%89%A7?start=7860&type=T
input url is: http://movie.douban.com/tag/%E5%96%9C%E5%89%A7?start=60&type=T
input url is: http://movie.douban.com/tag/%E5%96%9C%E5%89%A7?start=160&type=T
input url is: http://movie.douban.com/tag/%E5%96%9C%E5%89%A7?start=120&type=T
input url is: http://movie.douban.com/tag/%E5%96%9C%E5%89%A7?start=40&type=T
input url is: http://movie.douban.com/tag/%E5%96%9C%E5%89%A7?start=80&type=T
input url is: http://movie.douban.com/tag/%E5%96%9C%E5%89%A7?start=20&type=T
input url is: http://movie.douban.com/tag/%E5%96%9C%E5%89%A7?start=140&type=T
input url is: http://movie.douban.com/tag/%E5%96%9C%E5%89%A7?start=100&type=T做出的网页效果比较简陋,如下图所示: