文件共享及fork函数
<UNIX环境高级编程>文件共享及fork函数
http://www.cnblogs.com/qiuyi116/p/4322466.html
UNIX系统支持在不同进程间共享打开文件。内核使用3种数据结构表示打开文件,它们之间的关系决定了文件共享方面一个进程对另一个进程可能产生的影响。
内核维持了3个表,即进程表,文件表和v节点表。具体如下:
1>每个进程在进程表中都有一个纪录项,记录项中包含一张打开文件描述符表,每个描述符占用一项。与每个文件描述符相关联的是:
a. 文件描述符标志(close_on_exec);
b. 指向一个文件表项的指针。
2>内核为所有打开文件维持一张文件表。每个文件表项包含:
a. 文件状态标志(读、写、添写、同步和非阻塞等);
b. 当前文件偏移量;
c. 指向该文件v节点表项的指针。
3>每个打开文件(或设备)都有一个v节点(v-node)结构。v节点包含了文件类型和对此文件进行各种操作函数的指针。对于大多数文件,v节点还包含了该文件的i节点(i-node,索引节点),这些信息是在打开文件是从磁盘上读入内存用的。i节点包含了文件的所有者、文件长度、指向文件实际数据块在磁盘上所在位置的指针。(UNIX文件系统中有更多关于i节点的介绍。另,Linux没有使用v节点,而是采用了一个与文件系统相关的i节点和一个与文件系统无关的i节点)
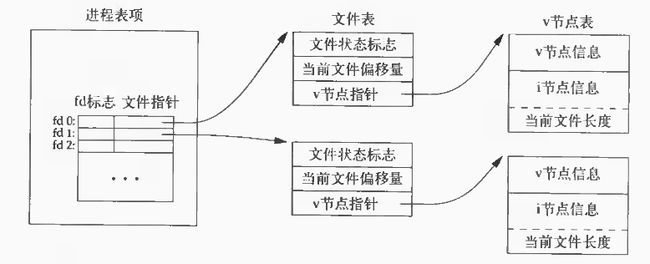
图1 打开文件的内核数据结构
上图显示了一个进程对应的3张表之间的关系。该进程有两个不同打开文件:一个文件从标准输入打开(文件描述符0),另一个文件从标准输出打开(文件描述符1)。
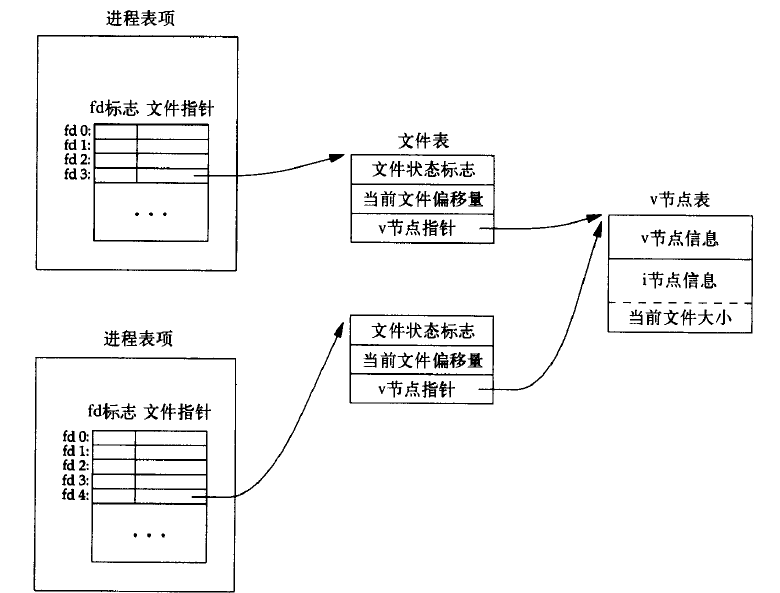
图2 两个福利进程各自打开同一个文件
一个现有的进程可以调用fork函数创建一个新进程。由fork进程创建的进程称为子进程,frok函数调用一次,返回两次。子进程的返回值是0,父进程的返回是子进程的进程ID。子进程和父进程继续执行fork调用之后的指令。(两个都会执行,但是执行先顺序不定,这取决于内核所使用的调度算法。) 子进程是父进程的副本,如子进程获得父进程数据空间、堆和栈的副本。父进程与子进程并不共享存储空间,但共享正文段。但许多实现并不执行父进程数据的完全副本,而是使用写时复制(Copy-On-Write, COW)技术。
下列代码中可以看到子进程对变量所做的改变并不影响父进程中该变量的值。
如果执行该程序,则可得到:
可以看到,第一次为直接执行,输出到标准输出;而第二次重定向到文件了。导致两次执行同样的代码,得到的结果却不同。我们知道,文件I/O函数是不带缓冲的,标准I/O库是带缓冲的。而标准输出连接到终端设备,则它是行缓冲的;否则它是全缓冲的。第一次执行中,printf函数输出到标准输出,缓冲区由换行符冲洗。而重定向到文件时,缓冲区是全缓冲的,在fork调用之前调用了printf一次。但当调用fork时,该行数据仍在缓冲区中,然后再将父进程数据空间复制到子进程中时,该缓冲区数据也被复制到子进程中,此时父进程和子进程各自有个带该行的缓冲区。在exit之前的第二个printf将其数据追加到已有的缓冲区中。当进程终止时,其缓冲区中的内容都被写到相应文件中。
对上述程序,需要注意的一点是:在重定向父进程的标准输出时,子进程的标准输出也被重定向。fork的一个特性是父进程所有打开文件描述符都复制到子进程中。父进程和子进程每个相同的打开描述符共享一个文件表项。重要的一点是,父进程和子进程共享同一个文件偏移量。
转载请注明地址<http://www.cnblogs.com/qiuyi116/p/4322466.html>,谢谢!
参考《UNIX环境编程》第三版