Hadoop自定义分区Partitioner
一:背景
为了使得MapReduce计算后的结果显示更加人性化,Hadoop提供了分区的功能,可以使得MapReduce计算结果输出到不同的分区中,方便查看。Hadoop提供的Partitioner组件可以让Map对Key进行分区,从而可以根据不同key来分发到不同的reduce中去处理,我们可以自定义key的分发规则,如数据文件包含不同的省份,而输出的要求是每个省份对应一个文件。
二:技术实现
自定义分区很简单,我们只需要继承抽象类Partitioner,实现自定义的getPartitioner()方法即可,另外还要给任务设置分区:job.setPartitionerClass(),就可以了。
案例
阿里巴巴旗下三个子网站site1、site2、site3,每个网站对商品销售进行了统计,现在要汇总这三个网站的销售量,数据如下:
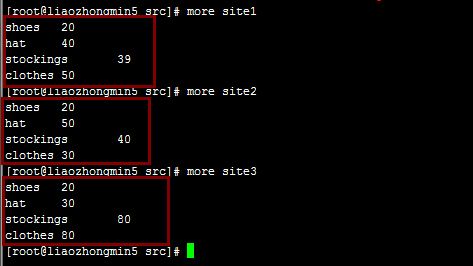
从上图可以看到有4种商品,很显然我们应该设置4个分区,代码如下:
public class MyPartitionerTest extends Configured implements Tool{
// 定义输入路径
private static String INPUT_PATH = "";
// 定义输出路径
private static String OUT_PATH = "";
public static void main(String[] args) {
try {
//运行
ToolRunner.run(new MyPartitionerTest(), args);
} catch (Exception e) {
e.printStackTrace();
}
}
public static class MyPartitionerMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
// 创建map输出的key
private Text product = new Text();
// 创建map输出的value
private LongWritable saleNum = new LongWritable();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException,
InterruptedException {
// 对行文本内容进行切分
String[] splits = value.toString().split("\t");
System.out.println(splits[0] +":"+ splits[1]);
// 获取商品和销售量写出去
product.set(splits[0]);
saleNum.set(Long.parseLong(splits[1]));
// 写出去
context.write(product, saleNum);
}
}
public static class MyPartitionerReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
// 定义商品的销售量
private LongWritable saleSum = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException,
InterruptedException {
// 定义商品的总数
Long sum = 0L;
// 遍历集合对商品销售进行汇总
for (LongWritable saleNum : values) {
sum += saleNum.get();
}
// 设置商品的总销售量
saleSum.set(sum);
// 写出去
context.write(key, saleSum);
}
}
public static class MyPartitioner extends Partitioner<Text, LongWritable> {
@Override
public int getPartition(Text key, LongWritable value, int numPartitions) {
if (key.toString().equals("shoes")) // 当key为"shoes"时,分一个区
return 0;
if (key.toString().equals("hat"))// 当key为"hat"时分一个区
return 1;
if (key.toString().equals("stockings"))// 当key为stockings"时分一个区
return 2;
// 其他的记录都分到一个区中
return 3;
}
}
public int run(String[] args) throws Exception {
try {
//为路径设置参数
INPUT_PATH = args[0];
OUT_PATH = args[1];
// 创建配置信息
Configuration conf = new Configuration();
// 创建文件系统
FileSystem fileSystem = FileSystem.get(new URI(OUT_PATH), conf);
// 如果输出目录存在,我们就删除
if (fileSystem.exists(new Path(OUT_PATH))) {
fileSystem.delete(new Path(OUT_PATH), true);
}
// 创建任务
Job job = new Job(conf, MyPartitionerTest.class.getName());
//打成jar包
job.setJarByClass(MyPartitionerTest.class);
//1.1 设置输入目录和设置输入数据格式化的类
FileInputFormat.setInputPaths(job, INPUT_PATH);
job.setInputFormatClass(TextInputFormat.class);
//1.2 设置自定义Mapper类和设置map函数输出数据的key和value的类型
job.setMapperClass(MyPartitionerMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 1.3 设置分区和reduce数量(reduce的数量,和分区的数量对应,因为分区为一个,所以reduce的数量也是一个)
job.setPartitionerClass(MyPartitioner.class);
job.setNumReduceTasks(4);//注:这个分区的数量是我们实现要规定好的,因为我们有四种商品,所以我们分了四个区
//1.4 排序、分组
//1.5 归约
job.setCombinerClass(MyPartitionerReducer.class);
// 2.1 Shuffle把数据从Map端拷贝到Reduce端。
//2.2 指定Reducer类和输出key和value的类型
job.setReducerClass(MyPartitionerReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//2.3 指定输出的路径和设置输出的格式化类
FileOutputFormat.setOutputPath(job, new Path(OUT_PATH));
job.setOutputFormatClass(TextOutputFormat.class);
// 提交作业 退出
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
return 0;
}
}
打包运行程序:
hadoop jar MyPartitioner.jar hdfs://liaozhongmin5:9000/files/* hdfs://liaozhongmin5:9000/out
程序运行结果:
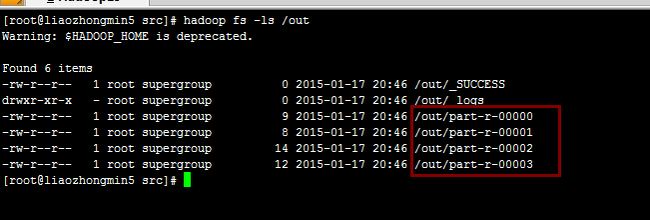
如我们所愿,程序分了四个分区!
程序运行的日志:
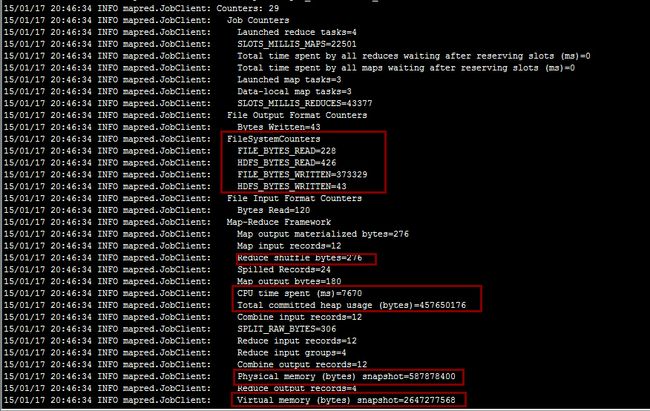
有兴趣的可以去分析一下程序运行所消耗的资源:基于计算机资源分析MapReduce运行。
注:一个有意思的问题是,我直接使用Eclipse插件连接远程的Hadoop集群去跑这个程序就会报错,提示分区非法,在网上看到有人说,如果分区数大于1的时候,就必须打成jar包才能正常运行,天知道呢,就这样吧,反正也没有更好的解释了!