Python爬虫基础
python爬虫基础
python是一门用途非常广泛的语言,被经常用来写取网络爬虫程序。
网络爬虫,即Web Spider,是一个很形象的名字。 把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。 网络蜘蛛是通过网页的链接地址来寻找网页的。 从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址, 然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。 如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。 这样看来,网络爬虫就是一个爬行程序,一个抓取网页的程序。
今天就来介绍下最简单的爬虫程序,让大家初步了解爬虫。
1.urlib库
urllib是Python的一个获取URLs(Uniform Resource Locators)的组件,广泛应用于python爬虫程序。 它以urlopen函数的形式提供了一个非常简单的接口。 最简单的urllib的应用代码只需要四行。 我们新建一个文件test01.py来感受一下urllib的作用:
import urllib #导入urlib库
url = "http://www.baidu.com/"
html = urllib.urlopen(url)
print html.read()
现在分析一下代码:
urlib.urlopen() 获得类文件对像,在括号内填入URL地址,也可将URL地址设为变量,传入变量。
print html.read() 读取页面代码,并输出。
是不是很简单?
2.常用的几个url函数 (注意以下代码中的html即为上面代码中的html)
print html.info() 获取网页头文件
print html.getcode()获取网页状态码 200 正常访问 301重定向 404网页不存在 403禁止访问 500状态出错
print html.geturl() 获取网页地址
urllib.urlretrieve(url, "C:\\Users\\lxdn\\Desktop\\html.txt ") 下载网页到指定路径
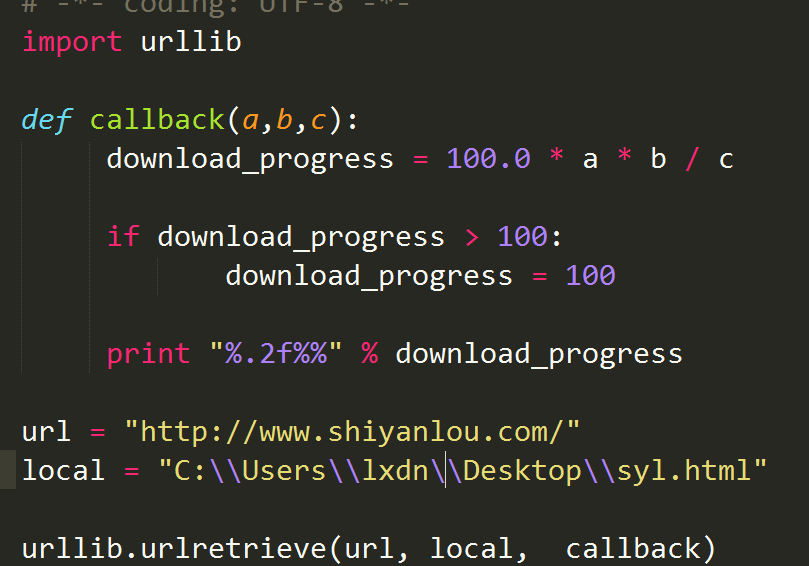
3.下面就写一个下载网站代码并保持在本地的小程序
# -*- coding: UTF-8 -*-
import urllib
def callback(a,b,c):
download_progress = 100.0 * a * b / c
if download_progress > 100:
download_progress = 100
print "%.2f%%" % download_progress
url = "http://www.shiyanlou.com/"
local = "C:\\Users\\lxdn\\Desktop\\syl.html"
urllib.urlretrieve(url, local, callback)
callback函数中 a:目前为止传递的数据块的数量 b:每个数据块的大小 c:远程文件的大小