操作系统概念学习笔记 15 内存管理(一)
操作系统概念学习笔记 15
内存管理(一)
背景
内存是现代计算机运行的中心。内存有很大一组字或字节组成,每个字或字节都有它们自己的地址。CPU根据程序计数器(PC)的值从内存中提取指令,这些指令可能会引起进一步对特定内存地址的读取和写入。
一个典型指令执行周期,首先从内存中读取指令。接着该指令被解码,且可能需要从内存中读取操作数。在指令对操作数执行后,其结果可能被存回到内存。内存单元只看到地址流,而并不直到这些地址是如何产生的(由指令计数器、索引、间接寻址、实地址等)或它们是什么地址(指令或数据)。
基本硬件:
CPU所能直接访问的存储器只有内存和处理器内的寄存器。机器指令可以用内存地址作为参数,而不能用磁盘地址作为参数。如果数据不在内存中,那么CPU使用前必须先把数据移到内存中。
CPU内置寄存器通常可以在一个CPU时钟周期内完成访问。对于寄存器的内容,绝大多数CPU可以在一个时钟周期内解析并执行一个或多个指令,而对于内存就不行。完成内存访问需要多个CPU时钟周期,由于没有数据以便完成正在执行的指令,CPU通常需要暂停(stall)。由于内存访问频繁,这种情况是难以忍受的,解决方法是在CPU与内存之间增加高速内存。这种协调速度差异的内存缓冲去,称为高速缓存(cache)。
除了保证访问物理内存的相对速度之外,还要确保操作系统不会被用户进程所访问,以及确保用户进程不会被其他用户进程访问。
其中一种可能方案为:
首先确保每个进程都有独立的内存空间,为此,需要确定进程可访问的合法地址的范围,并确保进程只能访问其合法地址。通过基地址寄存器(base register)和界限地址寄存器(limit register)可以实现这种保护。基地址寄存器(base register)含有最小的物理内存地址,界限地址寄存器(limit register)决定了范围的大小。例如:如果基地址寄存器为300040而界限寄存器为120900,那么程序可以访问从300040到420940的所有地址。
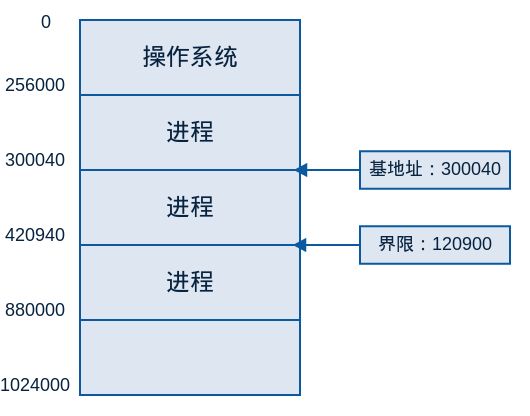
内存空间保护的实现,是通过CPU硬件对用户模式所产生的每个地址与寄存器的地址进程比较来完成的。如果访问了不该访问的地址,则会陷入到操作系统中,并作为致命错误处理。
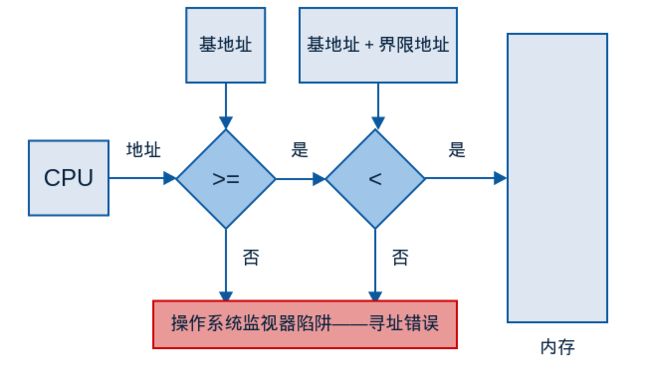
操作系统在内核模式下,可以无限制地访问操作系统和用户内存。因此操作系统可以将用户程序装入用户内存,在出错时输出这些程序,访问并修改系统调用的参数等。
地址绑定:
通常,程序以二进制可执行文件的形式存储在磁盘上。为了执行,程序被调入内存并放入进程空间内。
根据所使用的内存管理方案,进程在执行时,可以在磁盘和内存之间移动。在磁盘上等待调入内存以便执行的进程形成输入队列(input queue)。
通常的步骤是从输入队列中选取一个进程并装入内存。进程在执行时,会访问内存中的指令和数据。最后,进程终止,其地址空间将被释放。
许多系统允许用户进程放在物理地址的任意位置。这种组合方式会影响用户程序能够使用的地址空间。在绝大多数情况下,用户程序在执行前,会经过好几个步骤,在这些步骤中,地址可能有不同的表示形式,源程序中的地址通常是用符号(如count)来表示,编译器通常将这些符号地址绑定(bind)在可重定位的地址(如:从本模块开始的第14字节)。链接程序或加载程序再将这些可重定位的地址绑定成绝对地址(如74014)。每次绑定都是从一个地址空间到另一地址空间的映射。
通常,将指令与数据绑定到内存地址有以下几种情况:
编译时(compile time):如果编译时就知道进程将在内存中的驻留地址,那么就可以生成绝对代码(absolute code)。如果将来开始地址发生变化,那么就必须重新编译代码。
加载时(load time):当编译时不知道进程将驻留在内存的什么地方,那么编译器就必须生成可重定位代码(reloadable code)。绑定会延迟到加载时才进行。如果开始地址发生变化。只需要重新加载用户代码已引入改变值。
执行时(execution time):如果进程在执行时可以从一个内存段移到另一个内存段,那么绑定必须延迟到执行时才发生。绝大多数通用计算机操作系统采用这种方法。
逻辑地址空间与物理地址空间:
CPU生成的地址通常称为逻辑地址(logical address),而内存单元所看到的地址(即加载到内存地址寄存器(memory-address register)中的地址)通常称为物理地址(physical address)。
编译和加载时的地址绑定方法生成相同的逻辑地址和物理地址。但是,执行时的地址绑定方案导致不同的逻辑地址和物理地址。对于这种情况,通常称逻辑地址为虚拟地址(virtual address)。由程序所生成的所有逻辑地址称为逻辑地址空间(logical address space),与这些逻辑地址相对应的物理地址的集合称为物理地址空间(physical address space)。
运行时从虚拟地址到物理地址的映射由被称为内存管理单元(memory-management unit,MMU)的硬件设备来完成。有很多可选择的方法来完成这种映射,如使用一个简单的MMU方案来实现这种映射,这是一种基地址寄存器方案的推广,基地址寄存器在这里称为重定位寄存器(relocation register),用户进程所生成的地址在送交内存之前,都加上重定位寄存器的值。
假如,基地址为14000,那么用户对地址346的访问将映射为地址14346。
用户程序绝对不会看到真正的物理地址。如,程序可以创建一个指向位置346的指针,将他保存在内存中,使用它,与其他地址进行比较等等,所有这些操作都是基于346进行的。用户程序处理逻辑地址时,内存映射硬件将逻辑地址转变为物理地址。所引用的内存地址只有在引用时才最后定位。
逻辑地址空间绑定到单独的一套物理地址空间。
动态加载(dynamic loading):
一个进程的整个程序和数据如果都必须处于物理内存中,则进程的大小受物理内存大小的限制。
为了获得更好的内存空间使用率,使用动态加载(dynamic loading),即一个子程序只有在调用时才被加载。
所有的子程序都以可重定位的形式保存在磁盘上。主程序装入内存并执行。当一个子程序需要调用另外一个子程序的时候,调用子程序首先检查另一个子程序是否已经被加载。如果没有,可重定位的链接程序将用来加载所需要的子程序,并更新程序的地址表以反应这一变化。接着控制传递给新加载的子程序。
动态加载的优点是不用子程序绝不会被加载,如果大多数代码需要用来处理异常情况,如错误处理,那么这种方法特别有用。对于这种情况,虽然总体上程序比较大,但是所使用的部分可能小很多。
动态加载不需要操作系统提供特别的支持。利用这种方法来设计程序主要是用户的责任。
动态链接(dynamically linking)与共享库:
有的操作系统只支持* 静态链接(static linking)*此时系统语言库的处理与其他目标模块一样,由加载程序合并到二进制程序镜像中。
动态链接的概念与动态加载相似。只是这里不是将加载延迟到运行时,而是将链接延迟到运行时。这一特点通常用于系统库,如语言子程序库。没有这一点,系统上的所有程序都需要一份语言库的副本,这一需求浪费了磁盘空间和内存空间。
如果有动态链接,二进制镜像中每个库程序的应用都有一个存根(stub)。存根是一小段代码,用以指出如何定位适当的内存驻留的库程序,或如果该程序不在内存中应如何安装入库。不管怎样,存根会用子程序地址来代替自己,并开始执行子程序。因此,下次再执行该子程序代码时,就可以直接进行,而不会因动态链接产生任何开销。采用这种方案,使用语言库的所有进程只需要一个库代码副本就可以了。
动态连接也可用于库更新。一个库可以被新的版本所替代,且使用该库的所有程序会自动使用新的版本。没有动态链接,所有这些程序必须重新链接以便访问。
为了不使程序错用新的、不兼容版本的库,程序和库将包括版本信息。多个版本的库都可以装入内存,程序通过版本信息来确定使用哪个库副本。
因此,只有用新库编译的程序才会收到新库的不兼容变化影响。在新程序装入之前所链接的其他程序可以继续使用老库。这种系统也称为共享库。
与动态加载不同,动态链接通常需要操作系统帮助。如果内存中的进程是彼此保护的,那么只有操作系统才可以检查所需子程序是否在其他进程内存空间内,或是允许多个进程访问同一内存地址。
交换
进程需要在内存中以便执行。进程也可以暂时从内存中交换(swap)到备份存储(backing store)上,当需要再次执行时在调回到内存中。
在交换策略的变种被用在基于优先级的调度算法中。如果有一个更高优先级的进程且需要服务,内存管理器可以交换出低优先级的进程,以便装入和执行更高优先级的的进程。当高优先级进程执行完后,低优先级进程可以交换回内存继续执行,这种交换有时候称为滚入(roll in/swap in)和滚出(roll out/swap out)。
通常,一个交换出的进程需要交换回它原来所占有的内存空间。这一限制是由地址绑定方式决定的。如果绑定是在汇编时或加载时所定的,那么就不可以移动到不同的位置。如果绑定在运行时才确定,由于物理地址是在运行时才确定,那么进程可以移动到不同的地址空间。
交换需要备份存储。备份存储通常是快速磁盘。这必须足够大,以便容纳所有不同用户的内存镜像副本,它也必须提供对这些内存镜像的直接访问。系统有一个就绪队列,它包括在备份存储或内存中等待运行的所有进程。当CPU调度程序决定执行进程时,它调用调度程序。调度程序检查队列中的下一进程是否在内存中,如果不在内存中且没有空闲内存空间,调度程序讲一个已在内存中的进程交换出去,并换入所需要的进程。然后,它重新装载寄存器,并将控制转交给所选择的进程。
交换系统的上下文切换时间比较长。为了有效使用CPU,需要使每个进程的执行时间比交换时间长。
注意交换时间主要部分是转移时间。总的转移时间与所交换的内存空间总量成正比。因此如果只需交换真正使用的内存,便可以减少交换时间。为有效使用这种方法,用户需要告诉系统其内存需求情况。因此,具有动态内存需求的进程要通过系统调用(请求内存和释放内存)来通知操作系统其内存需求变化情况。
交换也受其他因素限制。如果要换进的进程,那么必须确保该进程完全处于空闲状态。如果I/O异步访问用户内存的I/O缓冲区,那么该进程就不能被换出。假定由于设备忙,I/O操作在排队等待。如果换出进程P1换入进程P2,那么I/O操作可能试图使用现在已经属于进程P2的内存。
对于这个问题有两种解决方法:
一是,不能换出有待处理I/O的进程。
二是,I/O操作的执行只能使用操作系统缓冲区。仅当换入进程后,才执行操作系统缓冲与进程内存之间的数据转移。
交换空间通常作为磁盘的一整块,且独立与文件系统,因此使用就可能很快。
通常并不执行交换,但当有许多进程运行且内存空间吃紧时,交换开始启动。如果系统负荷降低,交换就暂停。
连续内存分配(contiguous memory allocation)
内存必须容纳操作系统和各种用户进程,因此应该尽可能有效地分配内存的各个部分。
内存通常分为两个区域:一个用于驻留操作系统,一个用于用户进程。操作系统可以位于低内存或高内存,影响这一决定的主要因素是中断向量的位置。由于中断向量通常位于低内存,因此程序员通常将操作系统放到低内存。
通常需要将多个进程同时放入内存中,因此需要考虑如何为输入队列中需要调入内存的进程分配内存空间。
采用连续内存分配(contiguous memory allocation)时,每个进程位于一个连续的内存区域。
内存映射与保护
通过采用重定位寄存器和界限地址寄存器可以实现保护。
重定位寄存器含有最小的物理地址值;界限地址寄存器含有逻辑地址的范围值。
这样每个逻辑地址必须小于界限地址寄存器。MMU动态第将逻辑地址加上重定位寄存器的值后影射成物理地址。映射后的物理地址再送交内存单元。
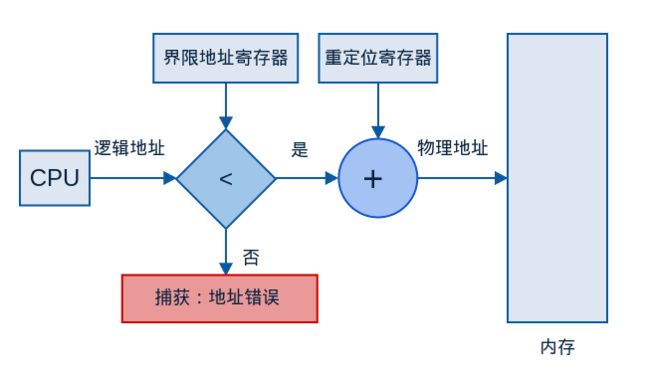
当CPU调度器选择一个进程来执行时,作为上下文切换工作的一个部分,调度程序会用正确的值来初始化重定位寄存器和界限地址寄存器,由于CPU所产生的每一地址都需要与寄存器进程核对,所以可以保证操作系统和其他用户程序和数据不受该进程运行所影响。
重定位寄存器机制为允许操作系统动态改变提供了一个有效方法。如某驱动程序(或其他操作系统服务)不常使用便可以不必在内存中,这类代码有时称为暂时(transient)操作系统代码,它们根据需要调入或调出。因此,使用这种代码可以在程序执行时动态改变操作系统的大小。
内存分配
最简单的内存分配方法之一是将内存分为多个固定大小的分区(partition)。每个分区只能容纳一个进程。那么多道程序的程度会受分区数限制。如果使用这种多分区方法(multiple-partition method),当一个分区空闲时,可以输入队列中选择一个进程,以调入到空闲分区。当进程终止时,其分区可以被其他进程所使用。这种方法现在已不再使用。对于固定分区方案的推广(称为MVT),它主要用于批处理环境。也可用于纯分段内存管理的分时操作系统。
在可变分区(variable-partition)方案中,操作系统有一个表,用于记录那些内存可用和哪些内存已被占用。一开始,所有内存都可用于用户进程,因此可以作为一大块可用内存,称为孔(hole),当新进程需要内存时,为该进程查找足够大的孔,如果找到,可以从该孔进程分配所需的内存,孔内未分配的内存可用于下次再用。
随着进程进入系统,它们将被加入输入队列中。操作系统根据调度算法来对输入队列进行排序。内存不断地分配给进程,直到下一个进程的内存需求不能满足为止,如果没有足够大的孔来装入进程,操作系统可以等到有足够大的空间,或者往下扫描输入队列以确定是否其他内存需求较小的进程可以被满足。
通常,一组不同大小的孔分散在内存中。当新进程需要内存时,系统为进程查找足够大的孔。如果孔太大,那么就分成两块:一块分配给新进程,另一块还回到孔集合,当进程终止时,它将释放其内存,改内存将还给孔集合。如果孔与其他孔相邻,那么将这些孔合并为大孔。这时,系统可以检查是否有进程在等待内存空间,新合并的内存空间是否满足等待进程。
这种方法是通用动态存储分配问题的一种情况(根据一组空闲孔来分配大小为n的请求),这个问题有许多解决方法。从一组可用孔中选择一个空闲孔的最为常用方法有首次适应(first-fit)(第一个对够大的孔)、最佳适应(best-fit)(最小的最够大的孔)、最差适应(worst-fit)(分配最大的孔)。
首次适应(first-fit):分配第一个足够大的孔,查找可以从头开始,也可以从上次首次适应结束时开始。一旦找到足够大的空闲孔,就可以停止。
最佳适应(best-fit):分配最小的足够大的孔。必须查找整个列表,除非列表按照大小排序。这种方法可以产生最小剩余孔。
最差适应(worst-fit):分配最大的孔,同样必须查找整个列表,除非列表按照大小排序。这种方法可以产生最大剩余孔。该孔可能比最佳适应方法产生的最小剩余孔更有用。
模拟结果显示:首次适应和最佳适应方法在执行时间和利用空间方面都好于最差适应方法。首次适应和最佳适应方法在利用空间方面难分伯仲,首次适应方法更快些。
碎片(fragmentation)
首次适应和最佳适应算法都有外部碎片问题(external fragmentation)。随着进程装入和移出内存,空闲内存空间被分割为小分段,
当所有总的空用内存之和可以满足请求,但并不连续时,这就出现了外部碎片问题。最坏的情况下,每两个进程之间就有空闲块(或浪费)。如果这些内存是一整块,那么就可以再运行多个进程。
在首次适应和最佳适应之间的选择可能会影响碎片的量。另一个影响因素是从空闲块的哪端开始分配。不管使用哪种算法,外部碎片始终是个问题。
根据内存的总大小和平均进程大小的不同,外部碎片化的重要程度也不同。例如,对采用首次适应方法的统计说明,对于首次适应方法不管怎么优化,假定N个可分配块,那么可能有0.5N个块为外部碎片。即1/3内存可能不能使用,这一特性称为50%规则。
内存碎片可以是内部的,也可以是外部的。如果内存以固定大小的块为单元来分配,进程所分配的内存可能比所要的要大。这两个数字之差称为内部碎片(internal fragmentation)这部分内存在分区内,但又不能使用。
一种解决外部碎片问题的方法是紧缩(compaction),紧缩的目的是移动内存内容,以便所有空闲空间合并成一整块。但是紧缩并非总是可能的。如果重定位是静态的,并且在汇编时或装入时进行的,那么就不能紧缩。紧缩仅在重定位是动态的并在运行时可采用。如果地址被动态重定位,可以首先移动程序和数据,然后再跟据新基地址的值来改变基地址寄存器。如果采用紧缩,还要评估其开销,最简单的合并算法是简单地将所有进城移到内存的一端,而将所有的孔移到内存的另一端,以生成一个大的空闲块。这种方案开销较大。
另一种解决方法外部碎片问题的方法是允许物理地址为非连续的。这样只要有物理内存就可以为进程分配。这种方案有两种互补的实现技术:分页和分段。这两种技术也可以合并。