caffe hinge _loss layer
铰链损失函数(Hinge Loss)
这个loss就是SVM用到的loss。Hinge loss就是0-1 loss的改良版,这个改良主要在两个方面,一个是在t.y在【0 1】之间不再是采用hard的方式,而是一个soft的方式。另外一个就是在【-inf,0】之间不再采用固定的1来定义能量的损失,而是采用一个线性函数对于错误分类的情况进行惩罚。
For an intended output t = ±1 and a classifier score y, the hinge loss of the prediction y is defined as
![]()
Note that y should be the "raw" output of the classifier's decision function, not the predicted class label. E.g., in linear SVMs,
![]()
It can be seen that when t and y have the same sign (meaning y predicts the right class) and
, the hinge loss
![]()
, but when they have opposite sign,
![]()
increases linearly with y (one-sided error).
来自 <http://en.wikipedia.org/wiki/Hinge_loss>
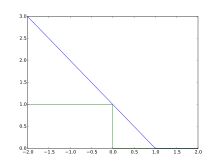
Plot of hinge loss (blue) vs. zero-one loss (misclassification, green:y < 0) for t = 1 and variable y. Note that the hinge loss penalizes predictions y < 1, corresponding to the notion of a margin in a support vector machine.
来自 <http://en.wikipedia.org/wiki/Hinge_loss>
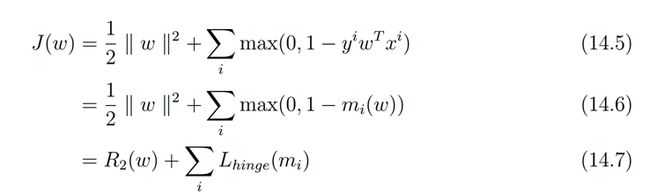
在Pegasos: Primal Estimated sub-GrAdient SOlver for SVM论文中
这里把第一部分看成正规化部分,第二部分看成误差部分,注意对比ng关于svm的课件
不考虑规则化
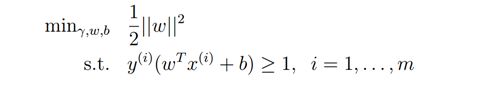
考虑规则化
输入:
形状: ![]()
![]()
![]()
![]() 预测值
预测值 ![]()
![]()
![]()
![]()
![]()
![]()
![]() 代表着预测
代表着预测 ![]()
![]() 个类中的得分(注:CHW表示着在网络设计中,不一定要把预测值进行向量化,只有其拉直后元素的个数相同即可。) . 在SVM中,
个类中的得分(注:CHW表示着在网络设计中,不一定要把预测值进行向量化,只有其拉直后元素的个数相同即可。) . 在SVM中, ![]() 是 D 维特征
是 D 维特征 ![]()
![]()
![]() , 和学习到的超平面参数
, 和学习到的超平面参数 ![]()
![]()
![]() 内积的结果
内积的结果 ![]()
![]()
所以,一个网络如果仅仅只有全连接层 + 铰链损失函数,而没有其它的可学习的参数,那么它就等价于SVM
标签值:
![]()
![]()
![]()
![]()
![]()
![]() 标签
标签 ![]() , 是一个整数类型的数
, 是一个整数类型的数 ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() 其代表在 个类中的正确的标签。
其代表在 个类中的正确的标签。
输出:
形状: ![]()
![]()
![]()
![]()
![]()
![]()
损失函数计算: ![]()
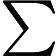
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() ,
, ![]()
![]() 范数 (默认是
范数 (默认是 ![]()
![]()
![]() , 是 L1 范数; L2 范数,正如在 L2-SVM中一样,也有实现),
, 是 L1 范数; L2 范数,正如在 L2-SVM中一样,也有实现),
其中 ![]()
![]() 条件
条件![]()
![]()
![]()
![]()
![]() 成立不成立
成立不成立
应用场景:
在一对多的分类中应用,类似于SVM.
Computes the hinge loss for a one-of-many classification task.
- Parameters
-
bottom input Blob vector (length 2)  the predictions , a Blob with values in indicating the predicted score for each of the classes. In an SVM, is the result of taking the inner product of the D-dimensional features and the learned hyperplane parameters , so a Net with just an InnerProductLayer (with num_output = D) providing predictions to a HingeLossLayer and no other learnable parameters or losses is equivalent to an SVM.
the predictions , a Blob with values in indicating the predicted score for each of the classes. In an SVM, is the result of taking the inner product of the D-dimensional features and the learned hyperplane parameters , so a Net with just an InnerProductLayer (with num_output = D) providing predictions to a HingeLossLayer and no other learnable parameters or losses is equivalent to an SVM.- the labels
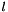 , an integer-valued Blob with values indicating the correct class label among the
, an integer-valued Blob with values indicating the correct class label among the 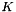 classes
classes
top output Blob vector (length 1)  the computed hinge loss:
the computed hinge loss: ![$ E = \frac{1}{N} \sum\limits_{n=1}^N \sum\limits_{k=1}^K [\max(0, 1 - \delta\{l_n = k\} t_{nk})] ^ p $](http://img.e-com-net.com/image/info5/42d14e99d13f485ea433272b9e76fc24.jpg) , for the norm (defaults to , the L1 norm; L2 norm, as in L2-SVM, is also available), and
, for the norm (defaults to , the L1 norm; L2 norm, as in L2-SVM, is also available), and
In an SVM,  is the result of taking the inner product of the features and the learned hyperplane parameters . So, a Net with just an InnerProductLayer (with num_output =
is the result of taking the inner product of the features and the learned hyperplane parameters . So, a Net with just an InnerProductLayer (with num_output = 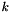 ) providing predictions to a HingeLossLayer is equivalent to an SVM (assuming it has no other learned outside theInnerProductLayer and no other losses outside the HingeLossLayer).
) providing predictions to a HingeLossLayer is equivalent to an SVM (assuming it has no other learned outside theInnerProductLayer and no other losses outside the HingeLossLayer).
Computes the hinge loss error gradient w.r.t. the predictions.
Gradients cannot be computed with respect to the label inputs (bottom[1]), so this method ignores bottom[1] and requires !propagate_down[1], crashing if propagate_down[1] is set.
- Parameters
-
top output Blob vector (length 1), providing the error gradient with respect to the outputs - This Blob's diff will simply contain the loss_weight* , as is the coefficient of this layer's output
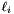 in the overall Net loss
in the overall Net loss  ; hence
; hence  . (*Assuming that this top Blob is not used as a bottom (input) by any other layer of the Net.)
. (*Assuming that this top Blob is not used as a bottom (input) by any other layer of the Net.)
propagate_down see Layer::Backward. propagate_down[1] must be false as we can't compute gradients with respect to the labels. bottom input Blob vector (length 2) - the predictions ; Backward computes diff
- the labels – ignored as we can't compute their error gradients