算法导论第十二(12)章 二叉查找树
12.1 二叉查找树
定义:设x为二叉查找树中的一个结点。如果y是x的左子树中的一个结点,则key[y]≤key[x]。如果y是x的右子树中的一个结点,则key[x]≤key[y].
前序遍历:先遍历根再遍历左右子树,简称根-左-右。
中序遍历:先遍历左子树再遍历根再遍历右子树,简称左-根-右。
后序遍历:先遍历左右子树再遍历根,简称左-右-根。
书中中序遍历代码:
//中序遍历
void INORDER-TREE-WALK(struct Tree *p)
{
if (p->key)
{
INORDER-TREE-WALK(p->lchild);
cout<<p->key<<" ";
INORDER-TREE-WALK(p->rchild);
}
}
定理12.1 如果x是一棵包含n个结点的子树的根,则调用INORDER-TREE-WALK(x)过程时间为θ(n).
12.1-1 略。
12.1-2 二叉查找树性质与最小堆(见6.1节)之间有什么区别?能否利用最小堆性质在O(n)时间内,按序输出含有n个结点的树中的所有关键字?行的话,解释该怎么做,不行的话,说明原因。
二叉查找树:根的左子树小于根,根的右子树大于根。而最小堆:根的左右子树均大于根。
不能。原因是含有n个结点的最小堆的结点key大小是根<左<右或者根<右<左,左右子树是无序的。导致结果就是不能按照树的前中后序遍历在O(n)时间内来有序的输出他们。再看二叉查找树,按照中序遍历,正好是左<根<右,他们是有序的。
12.1-3 给出一个非递归的中序树遍历算法。(提示:有两种方法,在较容易的方法中,可以采用栈作为辅助数据结构;较复杂的方法中,不采用栈结构,但假设可以测试两个指针是否相等)。
请看二叉树的递归与非递归遍历 这是以前写得一遍文章。里面有一段是非递归辅助栈遍历是前序遍历法。
现在给出非递归辅助栈中序遍历法,这段代码直接替换上面这篇文章的那段非递归前序遍历代码即可运行,如果写得有问题,请举例说明,谢谢!
void InOrderTraversal(struct Tree *root)
{
if (root == NULL) return;
s.top=-1;
s.push(root);
struct Tree *p=root;
while (1) {
if (p->lchild->key != 0)
{
p=p->lchild;
s.push(p);
}
else
{
cout<<p->key<<" ";
s.pop();
if (p->rchild->key)
{
s.push(p->rchild);
}
else
{
p=reinterpret_cast<struct Tree *>(s.Array[s.top]);//将数组中的数据恢复为编译器所能识别的指针
if (s.empty()) break;
cout<<p->key<<" ";
}
s.pop();
if (!p->rchild->key)
{
p=reinterpret_cast<struct Tree *>(s.Array[s.top]);
if (s.empty()) break;
cout<<p->key<<" ";
s.pop();
}
p=p->rchild;
s.push(p);
}
}
}
12.1-4 对一棵含有n个结点的树,给出能在θ(n)时间内,完成前序遍历和后序遍历的递归算法。
请看二叉树的递归与非递归遍历
12.1-5 论证:在比较模型中,最坏情况下排序n个元素的时间为Ω(nlgn),则为从任意的n个元素中构造出一棵二叉查找树,任何一个基于比较的算法在最坏情况下,都要花Ω(nlgn)的时间。
构造二叉查找树的同时也是对一组杂乱无章的数据排序的过程,而基于比较的排序的时间为Ω(nlgn),所以构造这棵树也要Ω(nlgn)。
12.2查询二叉查找树
查询特定关键字代码:
//递归版本的二叉查找树查找函数
struct Tree*TREE_SEARCH(struct Tree*x,int k)
{
if (0==x->key||k==x->key)return x;
if (k<x->key) return TREE_SEARCH(x->lchild,k);
else return TREE_SEARCH(x->rchild,k);
}
//非递归版本的二叉查找树查找函数
struct Tree*ITERATIVE_TREE_SEARCH(struct Tree*x,int k)
{
while (x->key!=NULL&&k!=x->key)
{
if (k<x->key)
{
x=x->lchild;
}
else x=x->rchild;
}
return x;
}
查询最小关键字与最大关键字代码:
//非递归版本的查找二叉查找树的最大值
struct Tree*ITERATIVE_TREE_MAXIMUM(struct Tree*x)
{
while (x->rchild->key!=NULL)
{
x=x->rchild;
}
return x;
}
//非递归版本的查找二叉查找树的最小值
struct Tree*ITERATIVE_TREE_MINIMUM(struct Tree*x)
{
while (x->lchild->key!=NULL)
{
x=x->lchild;
}
return x;
}
查询某个关键字的后继
//查找二叉查找树的后继
struct Tree*TREE_SUCCESSOR(struct Tree*x)
{
if (x->rchild->key!=NULL)
{
return TREE_MINIMUM(x->rchild);
}
struct Tree*y=x->parent;
while (y->key!=NULL&&x==y->rchild)
{
x=y;
y=y->parent;
}
return y;
}
定理12.2 对一棵高度为h的二叉查找树,动态集合操作SEARCH,MINIMUM,MAXIMUM,SUCCESSOR和PREDECESSOR等的运行时间均为O(h).
练习:
12.2-1 假设在某二叉查找树中,有1到1000之间的一些数,现要找出363这个数。下列的结点序列中,哪一个不可能是所检查的序列?
a)2,252, 401,398,330,344,397,363 b)924,220,911,244,898,258,362,363
c)925,202,911,240,912,245,363 d)2,399,387,219,266,382,381,278,363
e)935,278,347,621,299,392,358,363
c. 911与912不符合二叉查找树规则。e.347与299不符合二叉查找树规则。
12.2-2 写出TREE-MINIMUM和TREE-MAXIMUM过程的递归版本。
//递归版本的查找二叉查找树的最小值
struct Tree*TREE_MINIMUM(struct Tree*x)
{
if (x->lchild->key==NULL)return x;
else return TREE_MINIMUM(x->lchild);
}
//递归版本的查找二叉查找树的最大值
struct Tree*TREE_MAXIMUM(struct Tree*x)
{
if (x->rchild->key==NULL)return x;
else return TREE_MINIMUM(x->rchild);
}
12.2-3 写出TREE-PREDECESSOR过程。
写出二叉查找树前驱之前,我有必要给出带有父结点的二叉树创建函数。
void create(struct Tree **p)
{
static struct Tree *p1=NULL;//p1保存当前结点的父亲结点
*p=new struct Tree [LEN];
cin>>(*p)->key;
(*p)->parent=p1;
p1=*p;
if ((*p)->key!=0)
{
create((&(*p)->lchild));
p1=*p;
create((&(*p)->rchild));
}
}
//查找二叉查找树的前驱
struct Tree*TREE_PREDECESSOR(struct Tree*x)
{
if (x->lchild->key!=NULL)
{
return TREE_MAXIMUM(x->lchild);
}
struct Tree*y=x->parent;
while (y->key!=NULL&&x==y->lchild)
{
x=y;
y=y->parent;
}
return y;
}
12.2-4 Bun教授认为他发现了二叉查找树的一个重要性质。假设在二叉查找树中,对某关键字k的查找在一个叶结点结束,考虑三个集合:A,包含查找路径左边的关键字;B,包含查找路径上的关键字;C,包含查找路径右边的关键字。Bunyan教授宣称,任何三个关键字a∈A,b∈B,c∈C,必定满足a≤b≤c.请给出该命题的一个最小可能的反例。

查找路径(1→3→4)∈b ,2∈a,所以a>b。
12.2-5 证明:如果二叉查找树中的某个结点有两个子女,则其后继没有左子女,其前驱没有右子女。
设这个结点为x其左孩子x1右孩子x2,则有key[x1]≤key[x]≤key[x2]。若其后继x2有左子女x3,则key[x3]≤key[x2],而key[x的右子树]≥key[x],所以key[x2]≥key[x3]≥key[x],那么x3就为结点x的后继而非x2了。前驱没有右子女也有类似的证明。这里略过。
12.2-6 考虑一棵其关键字各不相同的二叉查找树T,证明:如果T中某个结点x的右子树为空,且x有一个后继y,那么y就是x的最低祖先,且其左孩子也是x的祖先。(注意每个节点都是它自己的祖先。)
若x是其后继y的左孩子,那么key[x]≤key[y],所以y是x的最低祖先,y的左孩子为x的祖先也就是x本身。
若x是其后继y的右孩子,那么key[x]≥key[y],这明显与后继定义矛盾,y是x的前驱。所以x不可能是后继y的右子树。
若x是y的左孩子y1的右孩子,那么有key[y1]≤key[x],后继y的左孩子y1是x的祖先,同时y是x的最低祖先。
12.2-7 对于一棵包含n个结点的二叉查找树,其中序遍历可以这样来实现:先用TREE-MINIMUM找出树中的最小元素,然后再调用n-1次TREE-SUCCESSOR。证明这个算法的运行时间为θ(n).

这个图是任意结点树中的一个小部分,但是他们的情况是类似的,都是从1-6顺序遍历的。本题的关键是这个算法在一个包含n个结点的二叉查找树的n-1个边上,通过这n-1分支中的每条边至多2次,也就是说总时间是T<h+2(n-1)=lgn+2(n-1)<cn=>T(n)=O(n)
12.2-8证明:在一棵高度为h的二叉查找树中,无论从哪一个结点开始,连续k次调用TREE-SUCCESSOR所需时间都是O(k+h).
如果简单的利用定义:每调用一次该函数就需要O(h)时间,调用k次就需要O(kh)时间。这种想法是没有深入分析题目中函数具体调用过程。如果明白12.2-7题目核心内容。就知道,除了第一次调用该函数需要O(h)时间外,其余的连续k-1次遍历了连续的k-1个结点,这k-1个结点有k-2个边,而每条边最多遍历2次。所以总时间T=O(h)+2(k-2)=O(h+k).
12.2-9 设T为一棵其关键字均不相同的二叉查找树,并设x为一个叶子结点,y为其父结点。证明:key[y]或者是T中大于key[x]的最小关键字,或者是T中小于key[x]的最大关键字
x是y的左孩子,y是在结点t的左子树上,如图a表达的关系可知:key[x]≤key[y]≤key[y的右子树]≤key[t],可见 "key[y]或者是T中大于key[x]的最小关键字" .如图b表达关系可知:key[t]≤key[x]≤key[y]≤key[y的右子树]。也得到相同的答案,无非如图ab两种情况。

x是y的右孩子,y是在结点t的左子树上,如图a表达的关系可知:key[y的左子树]≤key[y]≤key[x]≤key[t],可见 "或者key[y]是T中小于key[x]的最大关键字" .如图b表达关系可知:key[t]≤key[y的左子树]≤key[y]≤key[x],也可以得到相同的答案。 无非如图ab两种情况。
12.3二叉查找树的插入与删除
书上插入函数代码(为了使上下节代码的一致性,请注意我最后我特别添加的3行):
void TREE_INSERT(struct Tree*root,struct Tree*z)
{
struct Tree*y=NULL;
struct Tree*x=root;
while (x->key!=NULL)
{
y=x;
if (z->key<x->key)
x=x->lchild;
else x=x->rchild;
}
z->parent=y;
if (y->key==NULL)
{
root=z;
}
else if(z->key<y->key)
{
y->lchild=z;
}
else y->rchild=z;
z->lchild=new struct Tree[LEN];//根据此函数,带插入的空位一定是空结点,也就是0结点。不存在插入两个已存在的结点之间的情况。
z->rchild=new struct Tree[LEN];//插入后,一定要记得给其左右孩子赋值为空。
z->lchild->key=z->rchild->key=0;//所以要设置待插入的结点的左右孩子为0。
}
书上删除代码(第三版新代码,这个版本的删除代码虽然比上个版本复杂些,但是保证了删除无副作用):
//移植函数 把根为u的子树移植到根为v的子树上
void TRANSPLANT(struct Tree*root,struct Tree*u,struct Tree*v)
{
if (u->parent->key==NULL)
{
root=v;
}
else if(u==u->parent->lchild)
{
u->parent->lchild=v;
}
else u->parent->rchild=v;
if (v->key!=NULL)
{
v->parent=u->parent;
}
}
void TREE_DELETE(struct Tree*root,struct Tree*z)
{
if (z->lchild->key==NULL)
{
TRANSPLANT(root,z,z->rchild);
}
else if (z->rchild->key==NULL)
{
TRANSPLANT(root,z,z->lchild);
}
else
{
struct Tree*y=TREE_MINIMUM(z->rchild);
if (y->parent!=z)
{
TRANSPLANT(root,y,y->rchild);
y->rchild=z->rchild;
y->rchild->parent=y;
}
TRANSPLANT(root,z,y);
y->lchild=z->lchild;
y->lchild->parent=y;
}
}
练习:
12.3-1 给出过程TREE-INSERT的一个递归版本。
//递归的插入函数
void TREE_INSERT(struct Tree*x,struct Tree*z)
{
static struct Tree*y=NULL;
static struct Tree*root=x;
if (x->key!=NULL)
{
y=x;
if (z->key<x->key)
TREE_INSERT(x->lchild,z);
else
TREE_INSERT(x->rchild,z);
}
else
{
z->parent=y;
if (y->key==NULL)
{
root=z;
}
else if(z->key<y->key)
{
y->lchild=z;
}
else y->rchild=z;
z->lchild=new struct Tree[LEN];//根据此函数,带插入的空位一定是空结点,也就是0结点。不存在插入两个已存在的结点之间的情况。
z->rchild=new struct Tree[LEN];
z->lchild->key=z->rchild->key=0;//所以要设置待插入的结点的左右孩子为0,
}
}
12.3-2 假设我们通过反复插入不同的关键字的做法来构造一棵二叉查找树。论证:为在树中查找一个关键字,所检查的结点数等于插入该关键字时所检查的结点数加1.
从插入和查找函数的while循环遍历结构来看是完全一样的,区别就是查找函数遍历到关键字位置后就结束了,而插入函数遍历到待插入关键字的位置前一个位置便停止遍历转而进行插入工作,所以比查找函数少遍历一个结点。
12.3-3 可以这样来对n个数进行排序;先构造一棵包含这些数的二叉查找树(重复应用TREE-INSERT来逐个地插入这些数),然后按中序遍历来输出这些数。这个排序算法的最坏情况和最好情况运行时间怎么样?
最坏情况是树的高度为θ(n),此时T(n)=θ(1+2+...+n)+θ(n)=θ(n²) 最好情况是树的高度为θ(h),(h<n),此时T(n)=θ(lg1+lg2+...lgn)+θ(n)=lgn!+θ(n)=θ(nlgn)
12.3-4删除操作可交换的吗?(也就是说,先删除x,再删除y的二叉查找树与先删除y再删除x的一样)说明为什么是,或者给出一个反例。
不能交换,若交换删除后,虽然按中序输出顺序一样,但是树的内部结构可能不一样了。以书中图12-3为例:我们首先插入结点8,有9->left=8;先删除2后再删除5,结果为12->left=8,9->left=8,9->right=0,其他结构相同。而先删5再删2,12->left=9,8->left=0,8->right=9; 可见内部结构不同中序输出顺序相同。
12.3-5假设为每个节点换一种设计,属性x.p指向x的双亲,属性x.succ指向x的后继。试给出使用这种表示法的二叉搜索树T上SEARCH,INSERT和DELETE操作的伪代码。这些伪代码应在O(h)时间内执行完,其中h为T的高度。(提示:应该设计一个返回某个结点的双亲的子过程。)
似乎感觉,这种表示法和左右子树表示法类似。二叉查找树左子树相当于它的双亲,而右子树相当于它的后继。我的思路就这么多。如果有更好思路的可以在这里12.3-5回复我
12.3-6当TREE-DELETE中的结点z有两个子结点时,可以将其前驱(而不是后继)拼接掉。有些人提出一种公平的策略,即为前驱和后继结点赋予相同的优先级,从而可以得到更好的经验性能。那么,应如何修改TREE-DELETE来实现这样一种公平策略?
可以等概率随机选取前驱或后继结点以达到相同的优先级。以下是代码:
//移植函数 把根为u的子树移植到根为v的子树上
void TRANSPLANT(struct Tree*&root,struct Tree*u,struct Tree*v)
{
if (u->parent->key==NULL)
{
root=v;
}
else if(u==u->parent->lchild)
{
u->parent->lchild=v;
}
else u->parent->rchild=v;
if (v->key!=NULL)
{
v->parent=u->parent;
}
}
//将后继拼接掉的删除函数
void TREE_DELETE_SUCCESSOR(struct Tree*&root,struct Tree*z)
{
if (z->lchild->key==NULL)
{
TRANSPLANT(root,z,z->rchild);
}
else if (z->rchild->key==NULL)
{
TRANSPLANT(root,z,z->lchild);
}
else
{
struct Tree*y=TREE_MINIMUM(z->rchild);
if (y->parent!=z)
{
TRANSPLANT(root,y,y->rchild);
y->rchild=z->rchild;
y->rchild->parent=y;
}
TRANSPLANT(root,z,y);
y->lchild=z->lchild;
y->lchild->parent=y;
}
}
//将前驱拼接掉的删除函数
void TREE_DELETE_PREDECESSOR(struct Tree*&root,struct Tree*z)
{
if (z->lchild->key==NULL)
{
TRANSPLANT(root,z,z->rchild);
}
else if (z->rchild->key==NULL)
{
TRANSPLANT(root,z,z->lchild);
}
else
{
struct Tree*y=TREE_MAXIMUM(z->lchild);
if (y->parent!=z)
{
TRANSPLANT(root,y,y->lchild);
y->lchild=z->lchild;
y->lchild->parent=y;
}
TRANSPLANT(root,z,y);
y->rchild=z->rchild;
y->rchild->parent=y;
}
}
//改进的删除函数
void TREE_DELETE(struct Tree*&root,struct Tree*z)
{
srand( (unsigned)time( NULL ) );
int priority=rand()%2;
if (priority==0)
{
TREE_DELETE_PREDECESSOR(root,z);//若优先级为0,则把待删除的z的前驱移出原来的位置进行拼接,替换原来的z。
}
else TREE_DELETE_SUCCESSOR(root,z);//若优先级为1,则把待删除的z的后继移出原来的位置进行拼接,替换原来的z。
}//优先级priority是等概率出现的,所以有相同的优先级。
12.4 随机构建二叉搜索树
二叉查找树各种操作时间均是O(h),构建二叉查找树时,一般只用插入函数,这样便于分析,如果按严格增长顺序插入,那么构造出来的树就是一个高度为n-1的链。另一方面练习B.5-4说明了h≥lgn.这里我特别证明下。
证明:一个有n个结点的非空二叉树的高度至少为lgn.
对于一个高度为h的二叉树总结点数至多为n≤2^h-1(等于的情况就是完全二叉树),所以给这个不等式适当变型得:h≥lg(n+1)≥lgn,所以对于n个结点的数高度至少为lgn 虽然没有用归纳法,但是这种方法感觉简单易懂。
定理12.4 一棵有n个不同关键字的随机构建二叉搜索树的期望高度为O(lgn).
练习:
12.4-1 证明等式
12.4-2 请描述这样的一棵二叉查找树:其中每个结点的平均深度为θ(lgn),但树的深度为ω(lgn).对于一棵含n个结点的二叉查找树,如果其中每个结点的平均深度为θ(lgn),给出其高度的一个渐进上界。
问题一:猜想这样一棵树有个结点的完全二叉树,其中某一个叶子结点延伸一条含有个结点的直线链。
设完全二叉树部分高度h,则这棵二叉树的高度为h= ,那么完全二叉树部分的所有结点高度O().而另外一条直线链
,那么完全二叉树部分的所有结点高度O().而另外一条直线链
所有结点高度为O( ).这样n个结点二叉查找树平均高度为h=
).这样n个结点二叉查找树平均高度为h=
,所以这棵特意构造的二叉树符合题意的上界。故现在证明是否满足下界条件。
从完全二叉树叶子结点到直线链最底端的所有个结点高度为h≥,
所以这n个结点平均高度至少为 其中x是所有完全二叉树高度总和
其中x是所有完全二叉树高度总和
其中A是一个正数。由此可见这n个特别构造好的二叉查找树平均高度为θ(lgn).
再来看这个特别构造的树的高度为h=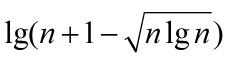 +
+ ≥ω(lgn)。问题一得证!
≥ω(lgn)。问题一得证!
问题二:首先证明:对于一个平均结点高度为θ(lgn)二叉查找树来说,树高的渐近上界为O(√nlgn).
证明:对于某棵含有n个结点的二叉查找树,我们定义某个叶子结点x(其深度为h)的路径上的所有结点深度d依次是0,1,...h,而其它非此路径上的结点深度为y.那么所有结点平均深度为h'=1/n(∑(d=0~h)+∑y)≥1/n(∑(d=0~h)=(1/n)θ(h^2),反证法:若h!=O(√nlgn)这个紧确上界,则当h=ω(√nlgn)或h=o(√nlgn)时,即(1/n)θ(h^2)=ω(lgn)或o(lgn)得到的却是非紧确界,这与树的平均高度为θ(lgn)这个紧确界不符,所以树高的渐进上界为O(√nlgn).
12.4-3 说明含有n个关键字的随机选择二叉搜索树的概念,这里每一棵n个结点的二叉搜索树是等可能地被选择,不同于本节中给出的随机构建二叉搜索树的概念。(提示:当n=3时,列出所有可能)。


如果你认真看这6张图,可以发现第4和第5张图是一样的。我要说明的是构建过程这两张图顺序是不一样的,分别是按2,1,3顺序与2,3,1的顺序插入,所以构建二叉搜索树是6种可能。如果选择这6张图中第4和第5张图结构是一样的,所以选择方式只有5种。故选择和构建是不同的概念。其实n>3时,也会出现类似的情况。这里就不多说了。
12.4-4 证明:f(x)=2^x是凹函数。(注意:原版书中的convex是凸,但是国外的语意和国内相反,所以翻译成凹才是符合题意。)
证明:根据凹函数定义:对于任意x,y,λ∈(0,1),有λ2^x+(1-λ)2^y≥2^(λx+(1-λ)y)......①这里有个重要不等式是证明的主要依据。即对于任意a,b,c都有c^a≥c^b+(a-b)(c^b)lnc而这个又根据e^x≥1+x而来。这里需要简要的证明下:设x=(a-b)lnc带入e^((a-b)lnc)≥1+(a-b)lnc 即c^(a-b)≥1+(a-b)lnc 两边都乘以c^b即得证!这样 我用2代替c,a代替x,b代替z,其中z=λx+(1-λ)y 便得:2^x≥2^z+(x-z)(2^z)ln2....②同理,a->y 其他一样,得2^y≥2^z+(y-z)(2^z)ln2....③ 把②和③式带入①式得:λ2^x+(1-λ)2^y≥λ(2^z+(x-z)(2^z)ln2)+(1-λ)(2^z+(y-z)(2^z)ln2)=(λ+1-λ)2^z+(λ(x-z)+(1-λ)(y-z))(2^z)ln2 将z用x,y表达式带入(λ(x-z)+(1-λ)(y-z))=0,所以λ2^x+(1-λ)2^y≥2^z=2^(λx+(1-λ)y),得证!
//思考题12-1 具有相同关键字的BST_b,d种处理方法。
#include <iostream>
#include <time.h>
using namespace std;
#define LEN sizeof(struct Tree)
#define m 10//栈的最大容纳空间可以调整
struct Tree
{
int key;
struct Tree*lchild;
struct Tree*rchild;
struct Tree*parent;
};
//非递归的插入函数处理含有相同关键字的BST_b
void ITERATIVE_TREE_INSERT_b(struct Tree*root,struct Tree*z)
{//这种对相同关键字处理的结果是O(nlgn),即使n个关键字都一样运行时间也是O(nlgn)。
struct Tree*y=NULL;
struct Tree*x=root;
static bool blag=false,BLAG=false;
while (x)
{
y=x;
if (z->key==x->key)
{
if (!blag)
{
x=x->lchild;
}
else
{
x=x->rchild;
}
blag=!blag;
continue;
}
if (z->key<x->key)
x=x->lchild;
else x=x->rchild;
}
z->parent=y;
if (y==NULL)
{
root=z;
}
else if(z->key==y->key)
{
if (!BLAG)
{
y->lchild=z;
}
else
{
y->rchild=z;
}
BLAG=!BLAG;
}
else if(z->key<y->key)
{
y->lchild=z;
}
else y->rchild=z;
z->lchild=z->rchild=NULL;//所以要设置待插入的结点的左右孩子为0,
}
//非递归的插入函数处理含有相同关键字的BST_d
void ITERATIVE_TREE_INSERT_d(struct Tree*root,struct Tree*z)
{//这种对相同关键字处理的结果是平均情况O(nlgn),既然是随机选择左右孩子,那么可能很不凑巧都选择了左孩子或者右孩子,最坏为O(n^2)
struct Tree*y=NULL;
struct Tree*x=root;
srand( (unsigned)time( NULL ) );
while (x)
{
y=x;
int flag=rand()%2;
if (z->key==x->key)
{
if (!flag)
{
x=x->lchild;
}
else
{
x=x->rchild;
}
continue;
}
if (z->key<x->key)
x=x->lchild;
else x=x->rchild;
}
z->parent=y;
if (y==NULL)
{
root=z;
}
else if(z->key==y->key)
{
int BLAG=rand()%2;
if (!BLAG)
{
if (!y->lchild->key)
{
y->lchild=z;
}
else y->rchild=z;
}
else
{
if (!y->rchild->key)
{
y->rchild=z;
}
else y->lchild=z;
}
}
else if(z->key<y->key)
{
y->lchild=z;
}
else y->rchild=z;
z->lchild=z->rchild=NULL;//所以要设置待插入的结点的左右孩子为0,
}
//中序遍历
void InOderTraverse(struct Tree *p)
{
if (p)
{
InOderTraverse(p->lchild);
cout<<p->key<<" ";
InOderTraverse(p->rchild);
}
}
void main()
{
struct Tree*p=NULL;
struct Tree*root=new struct Tree[LEN];
cin>>root->key;
ITERATIVE_TREE_INSERT_b(p,root);
int i=0;
while (i!=3)
{
struct Tree*z=new struct Tree[LEN];
cin>>z->key;
ITERATIVE_TREE_INSERT_b(root,z);
i++;
}
InOderTraverse(root);
}
//思考题12-1 具有相同关键字的BST_c种处理方法。
/*#include <iostream>
#include <time.h>
using namespace std;
#define LEN sizeof(struct Tree)
#define m 10//栈的最大容纳空间可以调整
struct Tree
{
int key;
struct Tree*lchild;
struct Tree*rchild;
struct Tree*parent;
struct Tree*next;
};
//非递归的插入函数处理含有相同关键字的BST_c
void ITERATIVE_TREE_INSERT_c(struct Tree*root,struct Tree*z)
{//这种对相同关键字处理的结果是O(nlgn),即使n个关键字都一样运行时间也是O(nlgn),因为相同关键字插入到列表中只需要O(1)时间。
struct Tree*y=NULL;
struct Tree*x=root;
while (x)//&&x->key!=NULL
{
y=x;
if (z->key==x->key)
{
break;
}
if (z->key<x->key)
x=x->lchild;
else x=x->rchild;
}
z->parent=y;
z->next=NULL;
if (!y)//||y->key==NULL
{
root=z;
}
else if(z->key==y->key)
{
if (y->next)
{
y->next->parent=z;
}
z->next=y->next;//插入到列表用头插法。
y->next=z;
}
else if(z->key<y->key)
{
y->lchild=z;
}
else y->rchild=z;
z->lchild=z->rchild=NULL;//所以要设置待插入的结点的左右孩子为空,
}
//中序遍历
void InOderTraverse(struct Tree *p)
{
if (p)//p->key
{
InOderTraverse(p->lchild);
struct Tree *p1=p;
while (p)
{
cout<<p->key<<" ";
p=p->next;
}
p=p1;
InOderTraverse(p->rchild);
}
}
void main()
{
struct Tree*p=NULL;
struct Tree*root=new struct Tree[LEN];
cin>>root->key;
root->next=NULL;
ITERATIVE_TREE_INSERT_c(p,root);
int i=0;
while (i!=13)
{
struct Tree*z=new struct Tree[LEN];
cin>>z->key;
ITERATIVE_TREE_INSERT_c(root,z);
i++;
}
InOderTraverse(root);
}
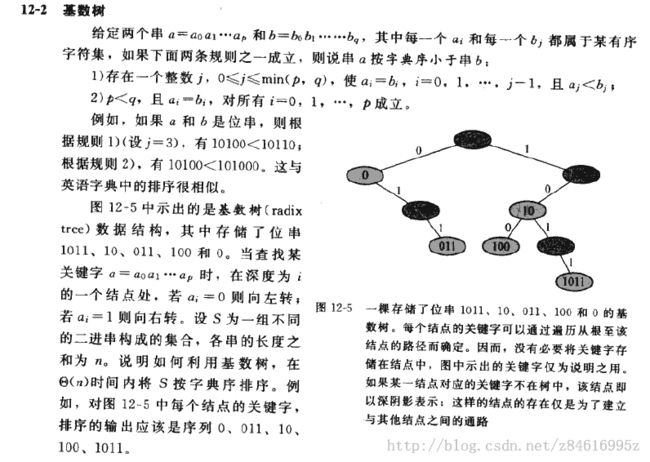
//思考题12-2基数树
#include <iostream>
#include <string>
#include <time.h>
using namespace std;
#define LEN sizeof(struct Tree)
#define m 10//栈的最大容纳空间可以调整
struct Tree
{
string key;
bool flag;//false代表不是用户输入结点,true代表是用户输入结点。
struct Tree*lchild;
struct Tree*rchild;
struct Tree*parent;//其实给基数树排序不需要父结点,这个结点适用于删除以及查找前驱和后继。
};
//非递归的插入函数
void ITERATIVE_TREE_INSERT(struct Tree*&root,struct Tree*z)
{
struct Tree*x=root;
int i=0;
while (i!=z->key.size()-1)
{//这个循环是找到待插入位置的父结点
if (z->key[i++]=='1')
{
if (!x->rchild)//x的右孩子为空,那么给其增加一个结点
{
x->rchild=new struct Tree[LEN];
x->rchild->key=z->key.substr(0,i);
x->rchild->flag=false;//这个结点是找到待插入结点必须经过的结点,但不是用户输入的结点,所以它的哨兵为false
x=x->rchild;
x->lchild=x->rchild=NULL;
}
else x=x->rchild;
}
else
{
if (!x->lchild)
{
x->lchild=new struct Tree[LEN];
x->lchild->key=z->key.substr(0,i);
x->lchild->flag=false;
x=x->lchild;
x->lchild=x->rchild=NULL;
}
else x=x->lchild;
}
}
if (x==NULL)//这组if-else结构是找到位置进行插入的。
{
root=z;
}
else if ((z->key[i]=='1'&&(!x->rchild))||(z->key[i]=='0'&&(!x->lchild)))
{//如果待插入结点位置没有数据,那么将
z->parent=x;
z->flag=true;
if(z->key[i]=='1')
{
x->rchild=z;
}
else x->lchild=z;
}
else
{
if (z->key[i]=='1'&&x->rchild)
{
x->rchild->flag=true;
}
if (z->key[i]=='0'&&x->lchild)
{
x->lchild->flag=true;
}
}
z->lchild=z->rchild=NULL;
}//从找到待插入的父结点位置到插入结点,总的执行步骤是该串的长度,进行N次插入其运行时间就是总串长度O(n).
//前序遍历
void InOderTraverse(struct Tree *p)
{
static struct Tree *p1=p;
if (p)//p->key
{
if (p!=p1&&p->flag)
{
cout<<p->key<<" ";
}
InOderTraverse(p->lchild);
InOderTraverse(p->rchild);
}
}
void main()
{
struct Tree*p=new struct Tree[LEN];
p->key="0";
p->parent=NULL;
struct Tree*root=NULL;
ITERATIVE_TREE_INSERT(root,p);
int i=0;
while (i!=5)
{
struct Tree*z=new struct Tree[LEN];
cin>>z->key;
ITERATIVE_TREE_INSERT(root,z);
i++;
}
InOderTraverse(root);
}





数组S,所有在S中的其他元素将被与y进行比较。因而,快速排序执行的比较是和插入到二叉查找树时进行的比较次序是一样的。
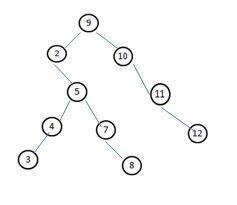
//12-3快排与二叉查找树比较顺序不同 比较元素相同
#include <iostream>
#include <time.h>
using namespace std;
#define LEN sizeof(struct Tree)
#define m 10//栈的最大容纳空间可以调整
struct Tree
{
int key;
struct Tree*lchild;
struct Tree*rchild;
struct Tree*parent;
};
//非递归的插入函数
void ITERATIVE_TREE_INSERT(struct Tree*&root,struct Tree*z)
{
struct Tree*y=NULL;
struct Tree*x=root;
while (x)
{
y=x;
if (z->key<x->key)
x=x->lchild;
else x=x->rchild;
}
z->parent=y;
if (y==NULL)
{
root=z;
}
else if(z->key<y->key)
{
y->lchild=z;
}
else y->rchild=z;
z->lchild=z->rchild=NULL;
}
int PARTITION(int A[],int p,int r)
{
int x=A[r];
int i=p-1;
for (int j=p;j<=r-1;j++)//O(n)
{
if (A[j]<=x)
{
i++;
swap(A[i],A[j]);
}
}
swap(A[i+1],A[r]);
return i+1;
}
void QUICKSORT(int A[],int p,int r)
{
if (p<r)//T(n)=2
{
int q=PARTITION(A,p,r);
QUICKSORT(A,p,q-1);
QUICKSORT(A,q+1,r);
}
}
//中序遍历
void InOderTraverse(struct Tree *p)
{
if (p)
{
InOderTraverse(p->lchild);
cout<<p->key<<" ";
InOderTraverse(p->rchild);
}
}
void main()
{
int A[10]={10,5,7,12,3,4,8,11,2,9};
int B[10]={9,2,10,5,11,4,3,7,8,12};
QUICKSORT(A,0,9);
for (int i=0;i<10;i++)
{
cout<<A[i]<<" ";
}
cout<<endl;
i=0;
struct Tree*root=NULL;
while (i!=10)
{
struct Tree*z=new struct Tree[LEN];
z->key=B[i++];
ITERATIVE_TREE_INSERT(root,z);
}
InOderTraverse(root);
}
<img width="1000" height="350" alt="" src="http://img.blog.csdn.net/20140618231216000?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvejg0NjE2OTk1eg==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast" />



