数据结构 之 并查集(Disjoint Set)
一、并查集的概念:
首先,为了引出并查集,先介绍几个概念:
1、等价关系(Equivalent Relation)
自反性、对称性、传递性。
如果a和b存在等价关系,记为a~b。
2、等价类:
一个元素a(a属于S)的等价类是S的一个子集,它包含所有与a有关系的元素。注意,等价类形成对S的一个划分:S的每一个成员恰好互斥地出现在一个等价类中。为了确定是否a~b,我们仅需验证a和b是否属于同一个等价类即可。
3、并查集:
即为等价类,同一等价类(并查集)中元素两两存在等价关系,不同并查集元素之间没有等价关系。
4、相关性质:Find/Union
输入数据最初是N个集合的类(Collection),每个集合含有一个元素。初始的描述是所有的关系均为false(自反的除外)。每个集合都有一个不同的元素,从而S(i)&&S(j) = NULL,这使得这些集合是不相交的(Disjoint)。
此时有两种运算可以进行,即找出给定元素所属的集合和合并两个集合。
一种运算是Find,它返回包含给定元素的集合(即等价类)的名字。
另一种运算是添加关系。如果我们希望添加关系a~b,那么我们首先需要知道a和b是否已经存在关系。这可以通过对a和b执行Find检验它们是否属于同一个等价类来完成。如果它们不在同一类中,那么我们使用求并运算(Union),这种运算把含有a和b的两个等价类合并成一个新的等价类。
二、并查集的基本数据结构:
我们直接引出表示并查集的最佳数据结构,至于为什么不选择诸如链表等其他数据结构,可以参考《算法导论》和《数据结构和算法分析》。
在这里,我们使用树来表示每一个集合,因为树上的每一个元素都有相同的根。这样,我们就可以用根来命名所在的集合。
那么对于每一个元素,我们应该记录其所在的集合,这里,我们可以假设树被非显式地存储在一个数组中:数组的每个成员p[i]表示元素i的父亲。如果i是根,那么p[i]=0(也可以设置为p[i]=i)。
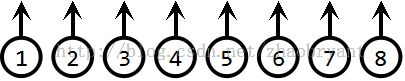
对于这样一个集合,当我们执行两个集合的Union运算,我们是一个节点的根指针指向另一棵树的根节点。
Union(5,6):
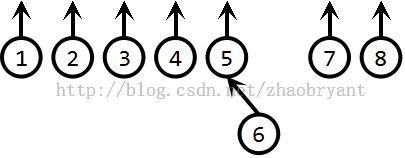
Union(7,8):
Union(5,7):
经过这样的过程后,上面的树的非显式表示(第一行为节点i的父节点p[i],第二行为节点i)即为:
|
0
|
0
|
0
|
0
|
0
|
5 |
5
|
7
|
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
或者(根节点p[i]=i)
| 1 |
2
|
3
|
4
|
5
|
5 |
5
|
7
|
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
三、并查集操作实现:
现在,我们考虑上面所提及的Find-Union操作的具体实现。
并查集操作:
makeSet(int x[]):建立一个新的集合,其唯一成员就是x。
unionSet(int x, int y):将包含x和y的动态集合(比如S(x)和S(y))合并为一个新的集合(即这两个集合的并集)。
int findSet(int x):返回x所在的集合编号。
声明:
p[]数组——p[i]的值即为节点i的父节点
NumSets——const常量,表示初始集合的个数,亦即初始元素的个数
makeSet(int x[])函数:
void makeSet(int x[])
{
int i;
for(i=0;i<NumSets;i++)
{
p[i] = 0;//Or p[i] = i
}
}
函数解析:
这个初始化过程,即是将数组中每个元素进行父节点赋值,这样即可确定元素的所属集合。由于初始化时,每个元素各自为单独的集合,因此,我们设置每一个元素的父节点为0(或节点自己)。
unionSet(int x, int y)函数:
void unionSet(int x, int y)
{
int a = findSet(x);
int b = findSet(y);
p[b] = a;
}
函数解析:
unionSet函数实现的是将两个元素对应的集合合并起来。在这里,我们实现的是基础方法,其优化方法在后面的优化部分会有讲解。
这里的基础方法,实现的思想为:将两个集合合并的方法,即是将一个集合的根节点的父节点设置为另一个集合的根节点。
根据上面的思想,这里的步骤就显而易见了:
首先通过findSet函数得到两个元素对应的集合编号,然后将其中一个集合的根节点父节点设置为另一集合的根节点,即完成了所有的合并操作。
findSet(int x)函数:
int findSet(int x)
{
if( p[x] <= 0) // Or if( p[x] == x )
return x;
else
return findSet(p[x]);
}
函数解析:
根据查找步骤,如果节点的父节点为0(或节点自己),那么就返回节点自己,因为该节点即为该树的根节点;如果节点的父节点不为0(或者不是节点自己),那么就说明该节点存在父节点,那么就返回该父节点所在的集合编号,此集合编号亦为该节点的集合编号。
根据上面的代码,我们发现其是由递归的算法思想来实现的,递归终止条件为查找到根节点处,递归模式的理论基础为节点所属集合与节点的父节点所属集合是同一集合。
四、并查集操作的优化:
首先,我们先看这样一个例子:
初始时,我们有5个元素,各自形成5个独立的集合:
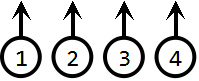
现在,我们按照前面的unionSet函数进行这样一些集合合并操作:
unionSet(2,1):
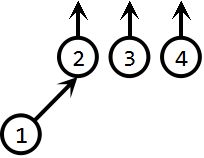
unionSet(3,1):
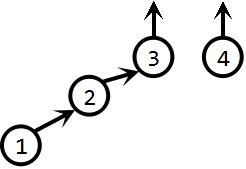
unionSet(4,1):
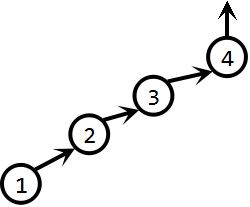
现在,我们考查这个过程,当我们执行完三次unionSet操作后,这个集合便成为了一个链表形式。这样导致的问题就是查找效率会很低。
为什么链表的整体性能较差呢?
对于并查集,我们经常使用的是Find-Union操作。如果使用链表数据结构来存储并查集,我们常常指定链表的第一个元素作为它所在集合的代表。那么对于查找Find操作,对于尾端的元素,要查找至链表头节点,需要遍历整个链表,其时间复杂度为O(n)。而对于合并union操作,将两个元素所在的集合合并起来,即将两个链表合并起来,一般可以使用两种方法,一种是头头相连,一种是头尾相连。但是,无论是哪种合并方法,都需要经历查找过程,找到链表的头节点,然后再进行连接操作。综合看来,其查找和合并操作所需的时间复杂度高于根树的实现方法。
在这里,我们所采用的优化方式是尽量避免合并之后树的深度过分增加的启发式策略。
第一种启发式是按秩合并(Union by Rank)。其思想是使包含较少节点的树的根指向包含较多节点的树的根。对每个节点,用秩表示节点高度的一个上界。在按秩合并中,具有较小秩的根在Union操作中要指向具有较大秩的根。
第二种启发式即路径压缩(Path Compression)。路径压缩在一次findSet2操作期间执行而与用来执行unionSet的方法无关。设操作为findSet2(x),此时路径压缩的效果是,从x到根的路径上的每个节点都使它的父节点变为根。
现在,一一讲解这两种方法:
1、按秩合并(Union by Rank):
这里,我们需要增加字段rank。在初始化过程中,需要对每个节点(集合)进行rank字段的初始化。
(1)、makeSet(int x[])
void makeSet(int x[])
{
int i;
for(i=0;i<NumSets;i++)
{
p[x[i]] = 0;//Or p[i] = i
rank[i] = 0;
}
}
(2)、按秩合并过程:具有较小秩的根在Union操作中要指向具有较大秩的根。
void unionByRank(int x, int y)
{
int fx = findSet(x);
int fy = findSet(y);
if( rank[fx] > rank[fy])
p[fy] = fx;
else
{
p[fx] = fy;
if(rank[fx] == rank[fy])
rank[fy]++;
}
}
函数解析:
这里主要集中这样几个问题:
a、为什么要找到根节点?
b、哪些情况下需要更新秩?
c、对于不同的秩的大小比较情况应采取何种不同的措施?
解答:
a、我们合并两个元素,即是合并两个元素分别对应的集合,也就是两棵不同的树。为了使合并后的树的深度的增加尽可能小,我们应该考虑的是树的秩,即根节点的秩,而不是儿子节点的秩。
b、更新秩的原因在于合并后的集合的秩发生了变化。而发生变化的情况只有一种:那就是合并前的两个集合的秩相等,这样必然会有其中一个集合的树的根指向另外一个集合的树的根节点,这样新的集合的秩必然增加1。
c、我们在合并时采用秩小的树合并到秩大的树,比较之后,通过改变p[i]即可实现合并过程。
举例说明这样合并的好处:
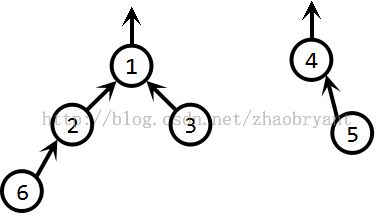
现有操作union(5,3):
对于传统的Union操作,即函数unionSet(5,3):
首先,找到5,3对应的集合,即findSet(5)=4, findSet(3)=1;
然后,p[1] = 4;
于是得到如下集合1:
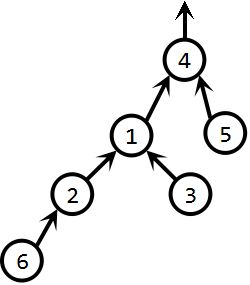
对于按秩合并,即函数unionByRank(5,3):
首先,找到5,3对应的集合,即findSet(5)=4, findSet(3)=1;
然后,由于4的rank小于1的rank,从而有p[4] = 1;
于是得到如下集合2:
通过对比集合1和集合2,显然集合2的构造更为均匀,会给查找操作带来很大的便利。
2、路径压缩(Path Compression):
对于路径压缩,其关键过程在于一定要使树的结构偏向于直连根节点的节点数增加,从而减少Find操作。
对于整个路径压缩过程,其核心就在于每次findSet操作过后均需将遍历到的节点动态直连到根节点上。也就是说,每次findSet时都会对整个集合的树结构进行调整。
void findSetWithPathCompression(int x)
{
if(p[x] == 0) //Or if(p[x] == x)
return x;
else
return p[x] = findSetWithPathCompression(p[x]);
}
函数解析:
仔细观察findSetWithPathCompression()函数与findSet()函数的区别,其区别就在于 p[x] = findSetWithPathCompression(p[x])。这个区别所产生的影响在什么地方呢?
举个例子:
对于下图所示的集合(根树),我们希望找到6所对应的集合编号:
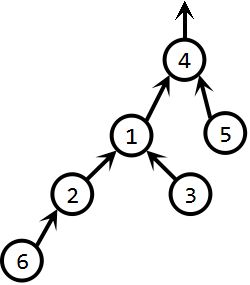
显然,对于findSet(6),其需要遍历节点6,2,1,4,经过四个步骤才能找到根节点,得到集合编号4。
而对于findSetWithPathCompression(6),其同样会遍历节点6,2,1,4,但是,由于p[x] = findSetWithPathCompression(p[x])的作用,p[6] = p[2] = p[1] =4。
从而,整个集合的根树就发生了结构性调整:
树的结构发生的变化带来的是后面查找操作的简化,同时没有改变整个集合的内容(我们不关注集合是怎样实现和存放的,我们关注的是集合中到底有哪些关系和元素)。
五、并查集应用实例:
描述
若某个家族人员过于庞大,要判断两个是否是亲戚,确实还很不容易。现给出某个亲戚关系图,求任意给出的两个人是否具有亲戚关系。 规定:x和y是亲戚,y和z是亲戚,那么x和z也是亲戚。如果x,y是亲戚,那么x的亲戚都是y的亲戚,y的亲戚也都是x的亲戚。
Input
第 一行:三个整数n、m、p (n< =5000,m< =5000, p< =5000),分别表示有n个人,m个亲戚关系,询问p对亲戚关系。
接下来的m行:每行两个数Mi、Mj (1< =Mi、Mj< =N),表示Mi和Mj具有亲戚关系。
接下来的p行:每行两个数Pi、Pj,询问Pi和Pj是否具有亲戚关系。
Output
p行,每行一个’Yes’或’No’。表示第i个询问的答案为“具有”或“不具有”亲戚关系。
问题分析
对于该问题,初步的感觉是利用图的连通性来实现,但是,由于数据量的巨大,要使用图来实现这样一个过程是不现实的。
注意,题目中的规定实质上指定了x与y的等价关系。因此,综合此题,我们可以使用并查集的方式来实现题目求解。这样,题意就转换为:
n个元素,通过m个等价关系构建集合,判断p对元素是否在同一集合中。
代码解答
#include <stdio.h>
#define MAX 5000
int p[MAX];
void makeSet(int x);
void unionSet(int x, int y);
void findSetWithPathCompression(int x);
int main(void)
int main(void)
{
int n,m,p;
int a,b;
int x,y;
scanf("%d %d %d", &n, &m, &p);
makeSet(n);
while(m--)
{
scanf("%d %d", &a, &b);
unionSet(a,b);
}
while(p--)
{
scanf("%d %d",&x,&y);
if( findSetWithPathCompression(x) == findSetWithPathCompression(y) )
printf("Yes\n");
else
printf("No\n");
}
}
void makeSet(int x)
{
int i;
for(i = 0; i < x; i++ )
p[i] = 0;
}
Other Functions is Writen in above Content.