HashMap、Hashtable、ConcurrentHashMap等深入分析
Map用于存储“key-value”元素对,它将一个key映射到一个而且只能是唯一的一个value。Map可以使用多种实现方式,HashMap的实现采用的是Hash表;而TreeMap采用的是红黑树。
1、HashMap的实现原理:
HashMap使用hash的方式实现。而hash表最常见的实现方式就是数组+链表的形式。Hash表结合了数组和链表两者的优点,数组寻址容易但插入删除困难,而链表寻址困难但插入删除容易。HashMap其实就是一个“链表的数组”。
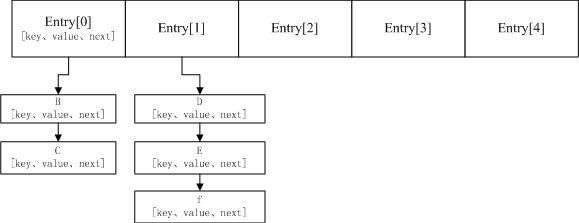
上图是HashMap的结构示意图。HashMap底层就是一个数组,而数组中的每一项又是一个链表。当HashMap新建时,就会初始化数组,Entry就是数组中的元素。而一个元素到底该存在什么位置是怎么确定的呢?一般情况是通过hash(key)&(len-1)获得的结果表示数组的下标,也就是元素的key的哈希值对数组长度取模得到。如果通过此方法获取到相同的下标,则会根据Entry来形成链表。Entry是HashMap中的一个静态内部类,它包括key、value、next等属性,其中next的作用是指向下一个Entry。打个比方, 第一个键值对A进来,通过计算其key的hash得到的index=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其index也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起。所以疑问不用担心。也就是说数组中存储的是最后插入的元素。
HashMap里面也包含一些优化方面的实现。比如:Entry[]的长度一定后,随着map里面数据的越来越长,这样同一个index的链就会很长,会不会影响性能?HashMap里面设置一个负载因子(也称为容客率),随着map的size越来越大,Entry[]会以一定的规则加长长度。
2、HashMap的存取实现:
存储操作:
public V put(K key, V value) {
return putImpl(key, value);
}
V putImpl(K key, V value) {
Entry<K,V> entry;
// HashMap允许存放null键和null值。
if(key == null) {
<span style="white-space:pre"> </span> // 当key为null时,调用putForNullKey方法,将value放置在数组第一个位置。
entry = findNullKeyEntry();
if (entry == null) {
modCount++;
entry = createHashedEntry(null, 0, 0);
if (++elementCount > threshold) {
rehash();
}
}
} else {
// 根据key的hashCode重新计算hash值。
int hash = key.hashCode();
// 搜索指定hash值所对应table中的索引。
int index = hash & (elementData.length - 1);
entry = findNonNullKeyEntry(key, index, hash);
if (entry == null) {
modCount++;
entry = createHashedEntry(key, index, hash);
if (++elementCount > threshold) {
rehash();
}
}
if ((cache != null) && (hash >> CACHE_BIT_SIZE == 0)
&& (key instanceof Integer)) {
cache[hash] = value;
}
}
V result = entry.value;
entry.value = value;
return result;
}
从源代码中可以看出:当我们往HashMap中put元素的时候,先根据key的hashCode重新计算hash值,根据hash值得到这个元素在数组中的位置(即下标),如果数组该位置上已经存放有其他元素了,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
读取操作:
public V get(Object key) {
if (key != null && cache != null && key instanceof Integer) {
int index = ((Integer) key).intValue();
if (index >> CACHE_BIT_SIZE == 0) {
return (V) cache[index];
}
}
Entry<K, V> m = getEntry(key);
if (m != null) {
return m.value;
}
return null;
}
有了上面存储时的hash算法作为基础,理解起来这段代码就很容易了。从上面的源代码中可以看出:从HashMap中get元素时,首先计算key的hashCode,找到数组中对应位置的某一元素,然后通过key的equals方法在对应位置的链表中找到需要的元素。
3、HashMap和Hashtable主要区别:
(1)HashMap和Hashtable都实现了Map接口,但是Hashtable的实现是基于Dictionary抽象类。
(2)HashMap允许null值(key和value都可以),Hashtable不允许null值(key和value都不可以)。因此,HashMap使用get()方法获取到null,可能是某个键对于value为null,也可能是没有该键,需要使用containsKey()来判断是否包含某个键值。Hashtable没有该问题,两种方式都可以。
(3)HashMap中hash数组的默认大小是16,客座率是0.75,增加方式是直接翻倍,也就是2的指数, 当HashMap容量达到了16*0.75 = 12,它的容量便会拓展到16*2=32。Hashtable中hash数组默认大小是11,增加的方式是old*2+1。
(4)Hashtable使用Enumeration,HashMap使用Iterator。以上只是表面的不同,它们的实现也有很大的不同。
(5)两者最大的区别在于HashMap不是线程安全的,而Hashtble的方法是线程安全的,它的方法是同步过了的,所以在多线程场合要手动同步HashMap。但java中提供了两种生成同步的HashMap的方法。见下文。
4、潜在的线程安全问题:
Map m =Collections.synchronizedMap(new HashMap(...));
该方法返回的是一个SynchronizedMap的实例。SynchronizedMap类是定义在Collections中的一个静态内部类。它实现了Map接口,并对其中的每一个方法实现,通过synchronized关键字进行了同步控制。这种方式获取的map中每个方法都是同步的,但并不意味着就一定是线程安全的。如下面代码:
Map<String,String>map=Collections.synchronizedMap(new TreeMap<String,String>());
map.put("key1","value1");
map.put("key2","value2");
if(map.containsKey("key1")){
map.remove("key1");
}
Set<Entry<String,String>> entries = map.entrySet();
Iterator<Entry<String,String>> iter = entries.iterator();
while(iter.hasNext()){
System.out.println(iter.next()); //Willthrow ConcurrentModificationException
map.remove("key2");
}
上边这段代码是在map删除一个元素之前,先判断这个元素是否存在。如果两个有线程,A线程首先执行containsKey方法,返回true,准备执行remove操作,这个时候,如果线程B也执行了containsKey方法,同样会返回true,然后准备执行remove方法,线程A,B有一个先执行remove可以删除该元素,当另一个执行时,会发现该元素已经没有了。
5、线程安全的HsahMap:
Hashtable虽然是线程安全的,它采用的锁机制是一次锁住整个hash表,同一时间点只能有一个线程操作,所有访问Hashtable的线程都要竞争同一把锁。在JDK5中,新增了ConcurrentMap接口和它的一个实现类ConcurrentHashMap。这个map可以实现与Hashtable相同的线程安全,但效率要比其高很多。ConcurrentHashMap的锁机制是一次锁住一个桶,它将Hash表默认分成16个桶,对于常见操作如get、set、remove等,只需要操作当前桶即可。这样原来只能有1个线程操作,变成了最多可以16个线程同时操作,性能提高是显而易见的。
6、遍历方式:
HashMap的遍历有两种常用的方法,那就是使用keyset或者entryset来进行遍历,如下;
Map<String, String> map = new HashMap<String, String>();
//方式一:
Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, String> entry = iterator.next();
entry.getKey();
entry.getValue();
}
//方式二:
for (Entry<String, String> entry : map.entrySet()) {
entry.getKey();
entry.getValue();
}
//方式三:
Iterator iterator = map.keySet().iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
Object val = map.get(key);
}
//方式四:
for (String key : map.keySet()) {
Object value = map.get(key);
}
使用entrySet时,将map中key和value都放在了entry对象中,所以取的时候直接取即可。使用keySet时,其实是遍历了2次,第一次形成iterator,第二次在HashMap中取出key对应的value。