Java SE之旅_07_集合框架
在Java中,我们经常使用对象封装特有的数据,而对象多了就需要存储,但是对象的个数又不确定.怎么办?集合框架来了!
集合框架就是用来存储对象的,不可以存储基本数据类型(JDK1.5后可以,因为有自动装箱)
集合容器因为内部的数据结构不同,有多种具体容器,如:List,Set,Map. 将这些容器不断的向上抽取,就形成了集合框架.
用个简单的图(只画出了常用的集合类)描述是:
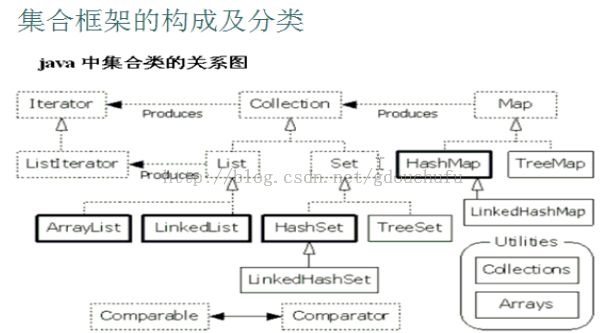
Collection
Collection是集合框架的顶层接口, 一次添加一个元素, 其下有两个常用的子类: List,Set.(还有Queue有时也用到)
List
List里的元素有序的(存入和取出的顺序一致), 且元素都有索引(角标),元素可以重复.
List下有三个常用的子类:ArrayList, LinkedList, Vector(基本淘汰了...)
ArrayList
LinkedList
Vector
Set
Set里的元素不能重复,且是无序的.
Set下有两个常用的子类: HashSet, TreeSet.
HashSet
HashSet:的内部数据结构是哈希表,通过对象的hashCode和equals方法来确定对象的唯一性:
如果对象的hashCode值不同, 那么不用判断equals方法, 就直接存储到哈希表中;
如果对象的hashCode值相同, 那么要再次判断对象的equals方法是否为true.
如果为true, 视为相同元素, 不进行存储; 如果为false, 那么视为不同元素, 进行存储.
所以如果要将元素要存储到HashSet集合中, 须覆盖对象的hashCode方法和equals方法, 否则HashSet将不会按照我们想要的方式存储元素.
TreeSet
TreeSet:可以对Set集合中的元素进行排序, 是不同步的.在TreeSet中判断元素唯一性的方式是根据对象的equals方法的返回结果, 如果是0则为相同元素,不会对其进行存储.
TreeSet对元素进行排序的方式有两种:
1. 让元素自身具备比较功能, 元素就需要实现Comparable接口, 覆盖compareTo方法;
2. 让集合自身具备比较功能, 定义一个类实现Comparator接口, 覆盖compare方法, 然后将该类对象作为参数传递给TreeSet集合的构造函数.
Map
Map类似于C#中的Dictionary, 一次添加一对元素,由键值对Key和Value组成, 且必须保证键的唯一性.
Map下的常用子类有: HashMap, TreeMap, HashTable.
HashMap
TreeMap
Hashtable
容器的结构和所属体系
这么多容器, 如何理解每一个容器的结构和所属体系呢?
不难发现, 容器的前缀名就是该集合的数据结构,后缀名就是该集合所属的体系~
如:ArrayList的前缀为Array,说明其内部数据结构是数组,后缀为List,说明其所属集合框架体系是List,这样很容易理解吧!
总结几个常见的数据结构的特点和用途如下:
Array: 数组, 特点:查询快,有角标.
Link: 链表, 特点:增删快, 常用方法有:add(), get(), remove()
Hash: 哈希表, 特点: 具有唯一性.
Tree: 二叉树, 用途: 排序.
集合框架的一些技巧
if(一次存储一个元素?){
if(元素需要唯一?){
//使用Set
if(需要有序?){
//使用TreeSet
}else{
//使用HashSet
}
}else{
//元素不需要唯一,使用List
if(查找速度必须快?){
//使用ArrayList
}else{
//使用LinkedList(增删速度快)
}
}
}else{//一次存储一对元素, 使用Map
if(需要有序?){
//使用TreeMap
}else{
if(key和value允许为null?){
//使用HashMap
}else{
//使用HashTable
}
}
}