机器学习系统构建
看了NG视频关于机器学习系统构建的建议,感觉很实用,记录下来作为听课笔记。
首先是机器学习系统构建的流程:

NG推荐方法:首先快速实现一个可能并不是很完美的算法系统,进行交叉验证,画出学习曲线去学习算法问题之处,是high bias or high variance 细节看这篇博文介绍:bias和variance在机器学习中应用
最重要一步:错误分析,手工检验算法错误学习的样本,找到算法在什么类型例子上犯错误!然后几种经历在处理这类错误上。
下面以垃圾邮件系统举例:

反垃圾邮件系统发现误分类最多的是Steal passwords所以集中经历去解决这部分问题!这样能比较高效率。
还有一个小窍门就是:学习算法我们需要有数值量化标准来评估算法!
课上NG提到Spam Email 中是否使用词干提取器,最好的办法就是实验两次分别使用和不适用,通过数值量化标准进行评估来选择是否采用词干提取器。
然后视频中特别提到需要在cross validation 集上进行错误分析验证,看下面题目:
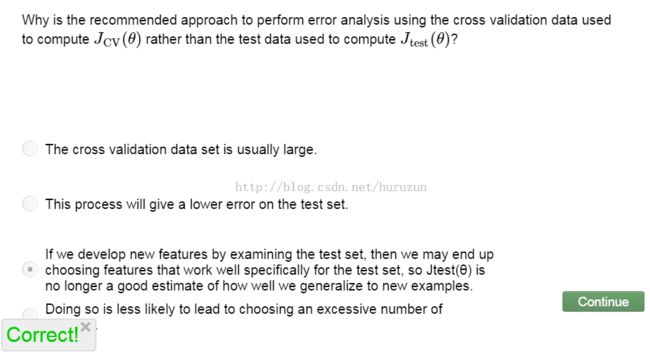
前面提到数值量化标准,有一种倾斜类状态看下图,会发现通常情况下的错误率衡量标准问题所在:
癌症病人比例为0.5% ,如果我们有一个算法错误率为1%,通常情况下这样的错误率是比较好,但是如果我不用任何算法就预测病人没有癌症,我的错误率也只有0.5%,所以需要引入新的数值评价标准:precision recall 见实例很好懂意思。
通常情况下,我们定义fscore来进行precision recall 的trade off

有句话可以参考:It's not who has the best algorithm that wins It's who has the most data。
意思在强调数据重要性,但是这个不完全对,在上一篇博文中提到,在某些状态下一味增加数据量是没有作用的!什么时刻增加数据是有意义的了?看下图
我们设定学习算法比较多参数,使用大的训练集,使得系统low bias low variance 这就是我们需要达到的目标!