CVPR 2015 Oral概览 - 第三天上午
第三天上午两大主题:在传统中探索新方向的行为识别,以及黑科技之计算摄影
D3-AM-A. Action and Event Recognition
【How Many Bits Does it Take for a Stimulus to Be Salient】
一个显著的刺激需要多少比特?
显著性 = 用周围的信息预测目标的不确定性。
本文用视频压缩后的比特数OBDL(operational block description length)来描述显著性。
另外用MRF来添加全局时序约束。
效果达到state of art,计算开销很低。
由于大部分摄像头都自带视频编码器,这个方法可以用于摄像头内部的显著性监测。
数据和源码公开。
【Deeply Learned Attributes for Crowded Scene Understanding】
深度学习特征用于群众场景理解
(港中文)
建立了数据库:WWW。包含1万视频,涵盖8257个人群场景,49种标签。
方法:Deep model。注意其中利用了视频的运动信息,来描述collectiveness、stability、conflict等性质。
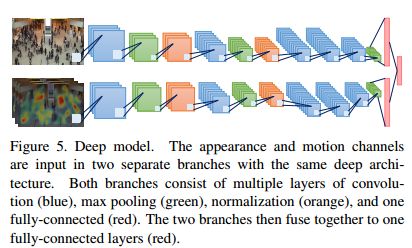
结果:

【Joint Inference of Groups, Events and Human Roles in Aerial Videos】
航空摄影中分组、时间、角色的联合推断
分析无人机拍摄的空中视频。特点:面积广阔,低画质。
同时给出信息(joint inference):分组,时间识别,分配人物角色。
Inference方法:Markov Chain Monte Carlo(MCMC) + Dynamic Programing(DP)
一个事件(交换盒子)用Spatial-Temporal-And-Or-Graph(ST-AOG)描述。
在XYT(空间-时间)坐标系中,交换盒子时间的模板可以如下表示。青:delivier,蓝:receiver,紫:盒子。

【modeling video evolution for action recognition】
视频演化建模用于动作识别
视频中不同动作的持续时间不同,难以划定一个界限分割“是此动作”/“不是此动作”。
核心思想称为VideoDarwin,改为用一个Ranking machine来给视频帧排名:越靠近事件发生点的帧,排名越靠前。
这个Ranking machine的参数即为视频帧的特征,可以用来识别动作。
下图:“move out from the house”动作的排名。
识别precision从60%提高到75%。速度与原方法相当。
【space time tree ensemble for action recognition】
时空树集合用于动作识别
(Disney)
用分层的树状结构来表示动作。红圈:root action word,篮圈:part action word。
从训练数据中发现(discover)这样的树状结构,之后学习这个结构上的action model。
【Social saliency prediction】
社会显著性预测
研究的问题很新颖。可以用于机器人路径规划:不光要找空地走,还要不影响别人的视线。
数据:第一人称视角视频,其自身运动即代表视线运动。
亮点:从social formation(社群形态)中预测joint attention,不需要gaze检测。
social formation:人群的空间分布,如蓝点所示。

用一个圆盘表示焦点s(joint attention)和人群中心c(center of mass)的性质。蓝色扇形表示人群的方向和距离。
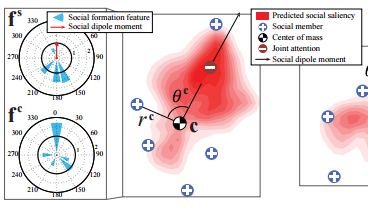
通过训练,可以从人群预测s。
使用线性规划方法把所有人围绕joint attention聚成群。

D3-AM-B. Computational Photography
【Visual Vibrometry: Estimating Material Properties From Small Motion in Video】
视觉抖动:利用视频中微笑运动估计材料属性
(MIT, Google)
从微小波动分析材质。这都啥脑洞。
【Recovering Inner Slices of Translucent Objects by Multi-Frequency Illumination】
利用多频率照明探究半透明物体的内部层次
恢复被半透明层遮盖的图像。原理:不同深度的图案具有不同的点扩散函数(PSF),对应不同频率。

借鉴HFI(high-frequency illumination method)技术[26]。HFI技术把镜头收到的反射光分为两部分:直接从光源获得直射部分/从环境中获得漫反射部分。
在光源发出带有细纹理的光,直射部分也会带纹理,但漫反射部分无纹理。

本文在细纹里的频率和图层深度之间建立了某种关系。详参第4章。
【Fast Bilateral-Space Stereo for Synthetic Defocus】
用于合成失焦的快速双边带空间双目重建方法
从双目图像虚化背景。10~100倍提速,质量更好。单张需约0.5s。

利用双边滤波(一种保留边缘的模糊算法)把图像分成不规则的vertex,在每个vertex之间计算偏差,进而估计深度。
【Simultaneous Video Defogging and Stereo Reconstruction】
视频同时去雾和双目重建
双目重建依赖视差。在远距离时表现不佳,原因是视差小,另外远处细节模糊。
但雾信息(fog transmission information)在远距离时能起补充作用。
另一方面,去雾依赖于颜色的鲜艳程度,但物体本身颜色会混淆这一因素。
双目重建的深度信息能够起补充作用。
480*280,10min一帧。
【One-day outdoor photometric stereo via skylight estimation】
利用天光完成一日室外双目重建
photometric stereo:从若干张(一般>3)光照不同的照片恢复形状。需要控制光照,可精确到图像解析度级别。
本文使用同一已知地点不同时间拍摄的户外照片,建立一个日照模型,进而恢复形状。
另外,传统此类方法需要长达若干月的图片,以避免光源的同平面问题,但本文利用了天空的自然光照,只需要一天内的图片。
