PL/SQL简介
前言
正文
PL/SQL
(Procedure Language,过程化语言)SQL 1999各大数据库厂商通用的一种结构化语言 PL/SQL只支持Oracle数据库
基本语法
多行注释 /* */ 单行注释 --
PLSQL程序块
结构
[declare]
定义变量
begin
过程语句
[exception]
处理 异常
end;
例子 输出helloworld
begin
dbms_output.put_line('hello');
end;
--如果过程执行完没有输出,必须将服务器输出打开
执行
SQL> set serveroutput on/off;
SQL>
SQL> begin
2 dbms_output.put_line('hello');
3 end;
4 /
hello
PL/SQL procedure successfully completed
变量
declare
变量名称 变量类型;
begin
end;
标识符:不能以数字开始 长度不能超过30个字符
变量初始化
采用:= 进行赋值
v_age number(10) := 10;
变量类型
number(m,n) 数字类型
char() 固定长度字符串
varchar2() 可变长度字符串
date 日期类型
boolean(true/false/null) 布尔类型
binary_integer 有符号整型
注意:布尔类型不能直接输出
代码示例:
注意:变量名称不能是SQL关键字,最好不要和表中字段同名
变量命名:
v_实际含义的单词
常量命名:
c_实际含义
参数命名
p_实际含义
游标类型
名称_cursor
表类型
名称_table
记录类型
名称_record
变量作用域
变量从声明开始到对应模块的end结束为它的作用域
--变量作用域代码示例
变量的其他类型
1.表类型
定义表类型
type 表类型名称 is table of 表类型存储的基本类型 index by binary_integer
声明变量为表类型
变量名称 表类型名称
表类型类似java中的数组,用来存储具有同种类型的数据
属性:
first 表示获得表类型的第一个下标
last 表示获得表类型的最后一个下标
count 表示表类型的数据个数
next(下标) 表示下一个下标
prior(下标) 表示前一个下标
代码示例:
表类型通过下标操作
2.记录类型
用来存储一条记录
type 记录类型名称 is record(field1 类型,field2 类型)
定义变量,将变量类型设置成记录类型
v_record 记录类型名称
代码示例
定义记录类型的简单方式
%rowtype 定义记录类型
表名%rowtype
代码示例
<div></div>
定义表类型的简单方式
%type 定义表类型
表名.字段名%type
代码示例: 将表中的所有记录存在一个变量中
操作符
算数运算符
跟java一致
v_age number(3) := 0;
v_age := v_age +1;
比较运算符
> < >= = 不等于!= <> ~= ^=
逻辑运算符
and or not
between and
赋值运算符
:=
流程控制
分支:
1.if分支
if 布尔表达式 then
…………
else
…………
end if;
多个分支:
if 布尔表达式 then
…………
elsif 布尔表达式 then
…………
elsif 布尔表达式 then
…………
else
…………
end if;
案例: --查找员工,根据职位进行工资的增加
2.case分支,类似java中的switch````case
case 变量
when 条件 then
语句·····
when 条件 then
语句·····
when 条件 then
语句·····
else
语句·····
end case;
案例
循环:
1.loop循环
定义一个循环指数
v_index binary_integer := 0;
loop
if v_index=循环次数 then
exit;
end if;
循环体
循环指数自增
v_index := v_index+1;
end loop;
案例:
--loop循环
declare
--定义循环指数
v_index binary_integer :=1;
begin
--定义loop循环
loop
--定义推出循环的条件
if v_index=5 then
exit;
end if;
--执行循环体
dbms_output.put_line(v_index);
--循环指数自增
v_index := v_index+1;
end loop;
end;
2.for循环
定义一个循环指数
v_index binary_integer;
for 循环指数 in 下限指数..上限指数 loop
循环体
end loop;
案例:
--for循环
注意:循环指数的开始一定要小于结束
通过reverse关键字实现循环反转
--for循环反转
declare
v_index binary_integer;
begin
for v_index in reverse 10..20 loop
dbms_output.put_line(v_index);
end loop;
end;
3.while循环
定义循环指数
v_index binary_integer := 1;
while 布尔表达式 loop
循环体
循环指数自增
end loop;
案例:
--while循环
declare
v_index binary_integer := 1;
begin
while v_index<5 loop
dbms_output.put_line(v_index);
v_index := v_index+1;
end loop;
end;
循环嵌套
通过<<label>>标签方式来控制循环
案例:
4.goto跳转
PL/SQL中书写定义sql
1.DQL语言
select 语句要求:1.必须写into关键字
2.查询语句只能有一条返回值
异常示例: 没有值 no_data_found; 值过多 too_many_rows
2.DML(insert/update/delete)
注意:执行DML语句要处理事务
动态传参
&+变量来实现动态传参
--执行DML语句
declare
begin
--普通DML语句
delete from emp where empno=&xx;
--事务处理
commit;
end;
3.DDL(create/drop/alter/truncate)
DDL语句要在 execute immediate('DDL')
游标(cursor)
sql语句执行时会在内存中开辟一个区域,用来存放执行的sql语句以及返回的数据,我们把这个内存区域叫做上下文环境(context);游标就是指向这个上下文环境的指针。
游标分类
隐式游标:由数据库管理系统创建执行
显示游标:有程序员负责创建执行和关闭的游标
游标的属性
%rowcount 存储的是游标执行时所影响的记录条数
操作属性
显示游标:自定义游标名称%rowcount
隐式游标:sql%rowcount
%found 判断当前数据有没有下一条 true/fase
%notfound 判断当前数据有没有下一条 true/fase
%isopen 判断游标是否开启
显示游标
1.创建游标
cursor 游标名称 is 查询语句
2.开启游标
open 游标名称
3.获取数据
fetch 游标名称 into 变量
4.关闭游标
close 游标名称
案例: --显示游标
for循环来循环游标
定义游标时传递参数
注意:设置形参时不要写参数的长度,实参是在开启游标的时候传递
游标不能重复开启和关闭
定义游标类型的变量
1.定义游标类型
type 游标类型名称 is ref cursor return 返回结果类型
2.定义游标类型的变量
变量名称 游标类型名称
过程和函数
过程(procedure)又叫存储过程(stored procedure),是一个有名称的PL/SQL程序块
过程相当于java中的方法, 它注重的是实现某种业务功能
函数(function)也相当于java中的方法,它 注重计算并且总是有返回结果
过程和函数都是能够永久存储在数据库中的程序代码块,应用时通过调用执行
过程的基本结构
create [or replace ] procedure 过程名称(形参名称 形参类型,形参名称 形参类型······)
is | as
定义变量
begin
过程体
exception
异常
end;
1.含有输入参数的过程
输入参数 用in 标识 可省略
2.无参的过程
3.有输出参数的过程
输出参数用 out 标识
过程的调用
1.通过匿名块调用
输入参数
输出参数过程
无参的过程
begin
mypro_noparam;
end;
2.命令行调用
调用输入参数
SQL> exec mypro(7788,3000);
输出参数
SQL> var v_sal number; 注册变量
SQL> exec mypro(7788,:v_sal); :变量名称 使用变量接收输出
调用无参
SQL> exec mypro;
示例代码:
1.写一个过程封装emp表中的数据
2.写一个过程输入员工编号,通过游标获取输出该员工对应下属的信息
3.通过java调用过程
java调用过程代码示例
自定义函数
异常
自定义异常
包
触发器 trigger
注:触发器的执行顺序
系统触发器
总结
使用SQL*PLUS登陆远程数据库的配置
手工编辑
$ORACLE_HOME/network/admin/tnsnames.ora文件。
工具编辑
通过Net Configuration Assistant或 Net Manager进行本地网络服务名配置。
UNIX系统
使用“sqlplus”命令登陆。
例如:DEV =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 172.11.11.11)(PORT = 1521))
)
(CONNECT_DATA =
(SERVICE_NAME = m11oti11on11)
)
)
使用SET命令配置环境
SQL*PLUS系统提供了许多SET命令。使用SET命令可以控制当前环境的设置。SET命令的语法形式如下:
SET system_variable value
在上面的语法中, system_variable变量用来控制当前环境,value是该系统变量的当前值。
如果希望得到当前指定SET命令的设置,那么可以使用SHOW [ALL]命令显示当前环境设置。
建立数据库
CREATE DATABASE database;
建立顺序号
CREATE SEQUENCE CINOSEQ MINVALUE 1 MAXVALUE 4000000000 START WITH 41 INCREMENT BY 1 NOCYCLE;
创建索引
语法
CREATE [ UNIQUE ] INDEX index
ON table "("
column [ ASC | DESC]
[, column [ ASC | DESC]]... ")" ;
修改表
在表的后面增加一个字段
ALTER TABLE 表名 ADD 字段名 字段名描述 [ DEFAULT expr ][ NOT NULL ][ ,字段名2 ……];
修改表里字段的定义描述
ALTER TABLE 表名 MODIFY 字段名1 字段名1描述 [ DEFAULT expr ][ NOT NULL ][ ,字段名2 ……];
删除表里的某个字段
ALTER TABLE 表名 DROP 字段名;
给表里的字段加上/禁止/启用约束条件
ALTER TABLE 表名 ADD | DISABLE | ENABLE CONSTRAINT 约束名 PRIMARY KEY (字段名1[,字段名2 ……]);
ALTER TABLE 表名 ADD | DISABLE | ENABLE CONSTRAINT 约束名 UNIQUE (字段名1[,字段名2 ……]);
删除表里的约束条件
ALTER TABLE 表名 DROP CONSTRAINTS 约束名 [CASCADE];
会把约束相关的索引一起删除,CASCADE能同时删去外键的约束条件。
删除索引
DROP INDEX 索引名;
删除顺序号
DROP SEQUENCE 顺序名;
删除数据库表
DROP TABLE 表名 [{CASCADE | CASCADE CONSTRAINTS | RESTRICT}] ;
查询
SELECT [ DISTINCT | ALL ]
{ * | column [[AS] alias] }
FROM { table | view }[ alias ]
[ WHERE condition]
[ { [ START WITH condition ]
CONNECT BY condition
| GROUP BY expr [, expr]...
| [HAVING condition] }]
单表查询
SELECT t.* FROM table t WHERE t.c1=‘…’;
内连接
SELECT t1.* FROM table1 t1 INNER JOIN table2 t2 ON t1.column1=t2.column2;
SELECT t1.* FROM table1 t1, table2 t2 WHERE t1.column1=t2.column2;
外连接
SELECT t1.* FROM table1 t1 { [ LEFT | RIGTH ] } [ OUTER ] JOIN table2 t2 ON t1.column1=t2.column2;
SELECT t1.* FROM table1 t1, table2 t2 WHERE t1.column1=t2.column2(+);
SELECT t1.* FROM table1 t1, table2 t2 WHERE t1.column1(+)=t2.column2;
子查询
SELECT … FROM (SELECT … FROM t1, [t2, …] WHERE condition1) WHERE condition2;
SELECT … FROM t1 WHERE t1.c1 IN (SELECT t2.c2 FROM t2 WHERE condition);
SELECT … FROM t1 WHERE t1 WHERE [NOT] EXISTS ( SELECT t2.c2 FROM t2 WHERE condition );
树查询(递归查询)
SELECT t1.* FROM table t1 START WITH t1.c1= … CONNECT BY PRIOR t1.c1=t1.c2;
connect by 是结构化查询中用到的,其基本语法是:
select * from tablename start with cond1
connect by cond2
where cond3;
oracle中的select语句可以用START WITH...CONNECT BY PRIOR子句实现递归查询,connect by 是结构化查询中用到的,其基本语法是:
select * from tablename start with cond1
connect by cond2
where cond3;
简单说来是将一个树状结构存储在一张表里,比如一个表中存在两个字段:
id,parentid那么通过表示每一条记录的parent是谁,就可以形成一个树状结构。
用上述语法的查询可以取得这棵树的所有记录。
其中COND1是根结点的限定语句,当然可以放宽限定条件,以取得多个根结点,实际就是多棵树。
COND2是连接条件,其中用PRIOR表示上一条记录,比如 CONNECT BY PRIOR ID=PRAENTID就是说上一条记录的ID是本条记录的PRAENTID,即本记录的父亲是上一条记录。
COND3是过滤条件,用于对返回的所有记录进行过滤。
对于oracle进行简单树查询(递归查询)
DEPTID NUMBER 部门id
PAREDEPTID NUMBER 父部门id(所属部门id)
NAME CHAR (40 Byte) 部门名称
通过子节点向根节点追朔.
select * from persons.dept start with deptid=76 connect by prior paredeptid=deptid
通过根节点遍历子节点.
select * from persons.dept start with paredeptid=0 connect by prior deptid=paredeptid
可通过level 关键字查询所在层次.
select a.*,level from persons.dept a start with paredeptid=0 connect by prior deptid=paredeptid
PS:start with 后面所跟的就是就是递归的种子,也就是递归开始的地方;
connect by prior后面的字段顺序是有讲究的;
若prior缺省:则只能查询到符合条件的起始行,并不进行递归查询;例如:
select * from emp start with empno=7839 connect by empno=mgr;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
----- ---------- --------- ----- ----------- --------- --------- ------
7839 KING PRESIDENT 1981-11-17 5000.00 10
例:
select * from table
start with org_id = 'HBHqfWGWPy'
connect by prior org_id = parent_id;
简单说来是将一个树状结构存储在一张表里,比如一个表中存在两个字段:
org_id,parent_id那么通过表示每一条记录的parent是谁,就可以形成一个树状结构。
用上述语法的查询可以取得这棵树的所有记录。
其中:
条件1 是根结点的限定语句,当然可以放宽限定条件,以取得多个根结点,实际就是多棵树。
条件2 是连接条件,其中用PRIOR表示上一条记录,
比如 CONNECT BY PRIOR org_id = parent_id就是说上一条记录的org_id 是本条记录的parent_id,即本记录的父亲是上一条记录。
条件3 是过滤条件,用于对返回的所有记录进行过滤。
简单介绍如下:
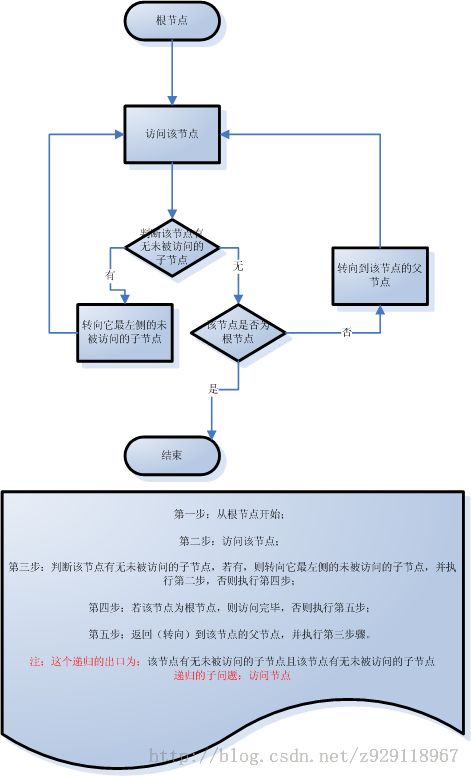
在扫描树结构表时,需要依此访问树结构的每个节点,一个节点只能访问一次,其访问的步骤如下:
第一步:从根节点开始;
第二步:访问该节点;
第三步:判断该节点有无未被访问的子节点,若有,则转向它最左侧的未被访问的子节点,并执行第二步,否则执行第四步;
第四步:若该节点为根节点,则访问完毕,否则执行第五步;
第五步:返回到该节点的父节点,并执行第三步骤。
总之:扫描整个树结构的过程也即是中序遍历树的过程。
1. 树结构的描述
树结构的数据存放在表中,数据之间的层次关系即父子关系,通过表中的列与列间的关系来描述,如 EMP 表中的 EMPNO 和 MGR 。 EMPNO 表示该雇员的编号, MGR 表示领导该雇员的人的编号,即子节点的 MGR 值等于父节点的 EMPNO 值。在表的每一行中都有一个表示父节点的 MGR (除根节点外),通过每个节点的父节点,就可以确定整个树结构。
select * from emp start with empno=7839 connect by prior empno=mgr;
在 SELECT 命令中使用 CONNECT BY 和 START WITH 子句可以查询表中的树型结构关系。其命令格式如下:
SELECT ...
CONNECT BY {PRIOR 列名 1= 列名 2| 列名 1=PRIOR 裂名 2}
[START WITH] ;
其中: CONNECT BY 子句说明每行数据将是按层次顺序检索,并规定将表中的数据连入树型结构的关系中。 PRIORY 运算符必须放置在连接关系的两列中某一个的前面。对于节点间的父子关系, PRIOR 运算符在一侧表示父节点,在另一侧表示子节点,从而确定查找树结构的顺序是自顶向下还是自底向上。在连接关系中,除了可以使用列名外,还允许使用列表达式。 START WITH 子句为可选项,用来标识哪个节点作为查找树型结构的根节点。若该子句被省略,则表示所有满足查询条件的行作为根节点。
START WITH: 不但可以指定一个根节点,还可以指定多个根节点。
2. 定义查找起始节点
在自顶向下查询树结构时,不但可以从根节点开始,还可以定义任何节点为起始节点,以此开始向下查找。这样查找的结果就是以该节点为开始的结构树的一枝。
3.使用 LEVEL
在具有树结构的表中,每一行数据都是树结构中的一个节点,由于节点所处的层次位置不同,所以每行记录都可以有一个层号。层号根据节点与根节点的距离确定。不论从哪个节点开始,该起始根节点的层号始终为 1 ,根节点的子节点为 2 , 依此类推。
4.节点和分支的裁剪
在对树结构进行查询时,可以去掉表中的某些行,也可以剪掉树中的一个分支,使用 WHERE 子句来限定树型结构中的单个节点,以去掉树中的单个节点,但它却不影响其后代节点(自顶向下检索时)或前辈节点(自底向顶检索时)。
5.排序显示
像在其它查询中一样,在树结构查询中也可以使用 ORDER BY 子句,改变查询结果的显示顺序,而不必按照遍历树结构的顺序。
插入数据insert
INSERT INTO { table | view } ["("column [, column]...")"]{ VALUES "(" expression[, expression]...")" | subquery };
说明
使用INSERT语句一次只能插入一行数据。
update
UPDATE { table | view } [ alias ] SET column = { expression | subquery } [, column = { expr | subquery }]...[WHERE condition] ;
说明
在修改表中数据时,不能破环表的完整性约束。如果修改的数据与完整性约束有冲突,那么这种修改操作不能成功。
delete
DELETE FROM { table | view }[WHERE condition] ;
说明
就像修改数据一样,删除数据时也不能破坏数据库的完整性约束。
事务
事务是一个逻辑上的单元。要么全部成功,要么全部失败。
在下面的情况下系统自动地结束一个事务:
COMMIT或ROLLBACK命令;
DDL,如CREATE TABLE语句;
退出SQL*PLUS;
系统失败。
语法
COMMIT [WORK] ;
ROLLBACK [{ WORK | TO savepoint_name }] ;
SAVEPOINT savepoint_name ;
REMOVE SAVEPOINT <savepoint_name>;
数据的导入和导出的例子
将数据库TEST完全导出,用户名system 密码manager 导出到daochu.dmp中
exp system/manager@TEST file=d:daochu.dmp full=y
将数据库中的表inner_notify、notify_staff_relat导出
exp aichannel/aichannel@TESTDB2 file= datanewsmgnt.dmp tables= (inner_notify,notify_staff_relat)
例子:导入
将daochu.dmp 中的数据导入 TEST数据库中
imp system/manager@TEST file=daochu.dmp
将daochu.dmp中的表table1 导入
imp system/manager@TEST file=d:daochu.dmp tables=(table1)