锋利的SQL2014:基于窗口的聚合计算
摘自作者新书《锋利的SQL》(第2版),网购京东:http://item.jd.com/11692900.html
实际上,窗口聚合与分组聚合在功能上是相同的,唯一的差别是,分组聚合是通过GROUP BY进行分组计算,而窗口聚合是通过OVER子句定义的窗口进行计算。前面我们讲了,这个所谓的窗口,实际上也是一组数据。
SQL Server提供的聚合函数包括:AVG、CHECKSUM_AGG、COUNT、COUNT_BIG、GROUPING、GROUPING_ID、MAX、MIN、SUM、STDEV、STDEVP、VAR、VARP。除了GROUPING和GROUPING_ID,都可以跟在OVER子句后面用于窗口的聚合计算。
开窗聚合函数支持分区、排序和框架三种元素,语法格式如下:
函数名称( < 参数 > ) OVER ( [ <PARTITION BYclause> ]
[ <ORDER BY clause> [<ROWS or RANGE clause> ] ]
)
PARTITION BY用于指定按哪列进行分区,如果不指定分区的话,也就是说OVER子句的圆括号中内容为空时,聚合函数实际上是对整个行集进行计算。
ORDER BY与<ROW or RANGE>子句共同对框架所涉及的行进行限定。通常情况下,框架都会涉及到排序问题,就像9.1节介绍的实例——在每一行计算第1~第n名的平均成绩一样。
9.2.1 窗口的分区
通过分区,可以将窗口限定为与当前行的分区列具有相同值的那些行。分区与分组有些类似,但是,在一条语句中指定分组列后,对于整个语句你只能按此列进行分组,而分区则可以在一条语句中指定多个不同的分区。我们通过下面的示例来说明这个问题,首先创建演示用的Orders表。表中存放着雇员ID、销售年份、销售季度和销售额四列数据。
IF OBJECT_ID('dbo.Orders','U') IS NOT NULL
DROP TABLEdbo.Orders;
CREATE TABLE dbo.Orders
(
EmpID int,
SalesYearint,
SalesQuarter int,
SubTotalmoney
);
INSERT INTO dbo.Orders VALUES
(1, 2013,1, 100.00),
(1, 2013,2, 200.00),
(1, 2013,3, 300.00),
(1, 2013,4, 400.00),
(1, 2014,1, 200.00),
(1, 2014,2, 200.00),
(1, 2014,3, 100.00),
(1, 2014,4, 100.00),
(2, 2013,1, 150.00),
(2, 2013,2, 250.00),
(2, 2013,3, 350.00),
(2, 2013,4, 450.00),
(2, 2014,1, 250.00),
(2, 2014,2, 250.00),
(2, 2014,3, 150.00),
(2, 2014,4, 150.00);
假设要计算年度销售合计和每年中每季度的销售合计,两种不同的分组,在下面一条分区语句就可以实现,查询结果如表9-3所示。可以看到,2013年和2014年的销售合计是分别是2200和1400,并且为年中的每个季度都计算出了合计,例如,2013年1季度是250,2季度是450。
SELECT EmpID, SalesYear, SalesQuarter, SubTotal,
SUM(SubTotal) OVER (PARTITION BY SalesYear)AS YSubTotal,
SUM(SubTotal) OVER (PARTITION BY SalesYear,SalesQuarter) AS QSubTotal
FROM dbo.Orders
ORDER BY SalesYear, SalesQuarter, EmpID;
表9-3 使用分区同时计算按年和按年+季度的分组合计
EmpID |
SalesYear |
SalesQuarter |
SubTotal |
YSubTotal |
QSubTotal |
1 |
2013 |
1 |
100 |
2200 |
250 |
2 |
2013 |
1 |
150 |
2200 |
250 |
1 |
2013 |
2 |
200 |
2200 |
450 |
2 |
2013 |
2 |
250 |
2200 |
450 |
1 |
2013 |
3 |
300 |
2200 |
650 |
2 |
2013 |
3 |
350 |
2200 |
650 |
1 |
2013 |
4 |
400 |
2200 |
850 |
2 |
2013 |
4 |
450 |
2200 |
850 |
1 |
2014 |
1 |
200 |
1400 |
450 |
2 |
2014 |
1 |
250 |
1400 |
450 |
1 |
2014 |
2 |
200 |
1400 |
450 |
2 |
2014 |
2 |
250 |
1400 |
450 |
1 |
2014 |
3 |
100 |
1400 |
250 |
2 |
2014 |
3 |
150 |
1400 |
250 |
1 |
2014 |
4 |
100 |
1400 |
250 |
2 |
2014 |
4 |
150 |
1400 |
250 |
如果使用分组的方式计算每年度销售合计和年度中每季度的销售合计,至少需要通过下面两条语句来完成。但是,我们分析一下表9-3,如果我们需要计算雇员销售额占全年销售额的比例,或是占季度销售额的比例,是不是非常容易呢?直接SubTotal/YSubTotal、SubTotal/QSubTotal就可以实现。
SELECT SalesYear, SUM(SubTotal) AS YSubTotal
FROM dbo.Orders
GROUP BY SalesYear;
SELECT SalesYear, SalesQuarter, SUM(SubTotal) ASQSubTotal
FROM dbo.Orders
GROUP BY SalesYear, SalesQuarter;
还有一种观点,就像我们在9.1节介绍的示例一样,分区可以通过子查询来实现。例如,下面两条语句的查询结果是相同的,都是计算雇员销售额占全年的比例,查询结果如表9-4所示。
SELECT SalesYear, SalesQuarter, EmpID, SubTotal,
SubTotal / SUM(SubTotal) OVER (PARTITION BY SalesYear) AS PerSubTotal
FROM dbo.Orders
ORDER BY SalesYear, SalesQuarter, EmpID;
SELECT O1.SalesYear, O1.SalesQuarter, O1.EmpID,O1.SubTotal,
O1.SubTotal / (SELECT SUM(SubTotal)
FROM dbo.Orders AS O2
WHERE O2.SalesYear = O1.SalesYear) ASPerSubTotal
FROM dbo.Orders AS O1
ORDER BY O1.SalesYear, O1.SalesQuarter, O1.EmpID;
表9-4 使用分区和子查询方式查询雇员销售额占全年销售额的比例
SalesYear |
SalesQuarter |
EmpID |
SubTotal |
PerSubTotal |
2013 |
1 |
1 |
100 |
0.0454 |
2013 |
1 |
2 |
150 |
0.0681 |
2013 |
2 |
1 |
200 |
0.0909 |
2013 |
2 |
2 |
250 |
0.1136 |
2013 |
3 |
1 |
300 |
0.1363 |
2013 |
3 |
2 |
350 |
0.159 |
2013 |
4 |
1 |
400 |
0.1818 |
2013 |
4 |
2 |
450 |
0.2045 |
2014 |
1 |
1 |
200 |
0.1428 |
2014 |
1 |
2 |
250 |
0.1785 |
2014 |
2 |
1 |
200 |
0.1428 |
2014 |
2 |
2 |
250 |
0.1785 |
2014 |
3 |
1 |
100 |
0.0714 |
2014 |
3 |
2 |
150 |
0.1071 |
2014 |
4 |
1 |
100 |
0.0714 |
2014 |
4 |
2 |
150 |
0.1071 |
两条语句的执行结果虽然一样,但是工作原理却并不相同。对于分区而言,它会按照指定的分区列(SalesYear)一次分隔计算完毕,也就是说,这些独立的小窗口是同时存在的,如图9-2所示;而对于子查询,却需要为每行数据执行一次表扫描。不言而喻,两者的效率是存在差异的。
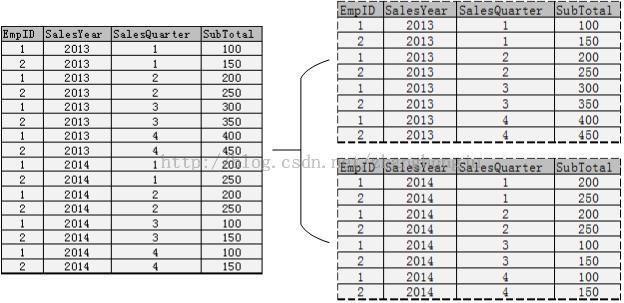
图9-2 分区后的所有窗口是同时存在的
9.2.2 窗口的排序与框架
框架可以对窗口进行进一步的分区,对于开窗聚合函数而言,按什么元素排序是至关重要的,排序一旦确定,框架的范围也就确定了下来。框架有两种范围限定方式,一种是使用ROWS子句通过指定当前行之前或之后的固定数目的行来限制分区中的行数,另一种是使用RANGE子句按照排序列的当前值,根据相同值来确定分区中的行数。例如,ROWS限定范围为当前行和前一行,那应当有两行数据;RANGE也是把范围限定为当前行和前一行,如果前一行的值与再前面行的值相同,那这个范围会自动扩大到3行。
1.ROWS子句
首先来看ROWS子句的语法格式:
ROWS BETWEEN UNBOUNDED PRECEDING |
< n > PRECEDING|
< n > FOLLOWING|
CURRENT ROW
AND
UNBOUNDED FOLLOWING |
< n >PRECEDING |
< n >FOLLOWING |
CURRENT ROW
UNBOUNDED PRECEDING指定窗口从分区中的第一行开始。< n > PRECEDING和< n > FOLLOWING分别用于指定窗口从当前行之前和之后的n行开始。CURRENT ROW用于指定当前行。UNBOUNDED FOLLOWING指定窗口在分区的最后一行结束。
下面通过一个示例来说明ROWS子句的使用方法,下面的语句按销售年度和雇员ID列进行分区,对于每个雇员累积计算第1季度至当前季度的销售额。查询结果和每次的累积分区窗口如图9-3所示。
SELECT EmpID, SalesYear, SalesQuarter, SubTotal,
SUM(SubTotal) OVER(PARTITION BY SalesYear, EmpID
ORDER BY SalesYear,SalesQuarter
ROWS BETWEEN UNBOUNDEDPRECEDING
AND CURRENTROW) AS RunSub
FROM dbo.Orders;
上面语句中的CURRENTROW限定也可以省略,SQLServer将默认把当前行作为框架的限定,参考下面的语句。
SELECT EmpID, SalesYear, SalesQuarter, SubTotal,
SUM(SubTotal) OVER(PARTITION BY SalesYear, EmpID
ORDER BY SalesYear,SalesQuarter
ROWS UNBOUNDED PRECEDING) AS RunSub
FROM dbo.Orders;
再来看另外一个示例,下面的语句使用< n > PRECEDING和< n > FOLLOWING通过指定具体行数的方法进行范围限定。第一个聚合中上限和下限都是当前行的前一行,实际上只有一行,用于取出当前季度上一季度的销售额;第二个聚合中上限和下限都是当前行的后一行,实际上也是只有一行,用于取出当前季度下一季度的销售额,第三个聚合中,上限是当前行的前一行,下限是当前行的后一行,实际上是取出当前季度与上一季度和下一季度的平均值。语句中的MAX函数只是为了语法上的合法性,该函数在数据处理上不起任何作为,因为范围内只有一行,没有什么值大小之说。查询结果如表9-6所示。
SELECT EmpID, SalesYear, SalesQuarter,
MAX(SubTotal) OVER(PARTITION BY EmpID
ORDER BY EmpID,SalesYear, SalesQuarter
ROWS BETWEEN 1 PRECEDING
AND 1 PRECEDING)AS N'上季度',
SubTotal AS N'当前季度',
MAX(SubTotal) OVER(PARTITION BY EmpID
ORDER BY EmpID,SalesYear, SalesQuarter
ROWS BETWEEN 1 FOLLOWING
AND 1 FOLLOWING) AS N'下季度',
AVG(SubTotal) OVER(PARTITION BY EmpID
ORDER BY EmpID,SalesYear, SalesQuarter
ROWS BETWEEN 1 PRECEDING
AND 1FOLLOWING) AS N'当前及上下季度平均'
FROM dbo.Orders;
分析一下表9-6中的数据。从第1行和第9行可以看出,对于2013年1季度而言,雇员1和雇员2在上一季度是没有数据的,故而是NULL值。从第8行和最后一行可以看出,对于2014年第4季度,之后也是没有数据的,因此也是NULL。看一下第1行中的平均值,它实际上是当前行和后一行的平均值,因为上一季度没有数据。第4行的平均值300,我们使用大括号的方式列出了它的计算范围,分别来自于300、400和200这三个数值。
2.RANGE子句
RANGE子句的语法格式与ROWS子句是基本相同的,唯一的区别是ROWS根据指定的行数来限定范围,而RANGE是根据排序列的值来确定范围。RANG子句的语法格式如下,但是截至SQL Server 2014为止,仅支持UNBOUNDED PRECEDING和CURRENT ROW操作符。
ROWS BETWEEN UNBOUNDED PRECEDING |
< val > PRECEDING |
< val > FOLLOWING |
CURRENT ROW
AND
UNBOUNDED FOLLOWING |
< val > PRECEDING |
< val > FOLLOWING |
CURRENT ROW
下面通过一个示例来说明RANGE子句的范围限定方法,参考下面的语句:
SELECT EmpID, SalesYear, SalesQuarter, SubTotal,
SUM(SubTotal)OVER(PARTITION BY EmpID
ORDER BY EmpID, SalesYear
RANGE BETWEEN UNBOUNDEDPRECEDING
AND CURRENT ROW) AS RunSubTotal
FROM dbo.Orders;
该语句的执行结果如表9-7所示。前4行RunSubTotal列都计算为1000,这是为什么呢?我们在前面强调过,排序对于范围的限定非常重要,注意上面的ORDER BY子句限定了按EmpID和SalesYear列排序。由表9-7中可以看到,前4行的EmpID和SalesYear值是相同的,因此RANGE将范围限定为这4行,所以SUM对这4行的SubTotal列进行求和,结果为1000。这里需要注意的是,我们说的用于限定范围的相同值,是指的排序列的值相同,而不是被聚合列的值相同。
上面示例中的排序列存在重复值,所以在使用RANGE时存在对多行聚合现象,当排序列的值具有唯一性时,RANGE和ROWS的限定范围实际上是一样的。例如,下面的两条语句一条使用了ROWS,一条使用了RANGE,其他完全相同。因为排序列EmpID+SalesYear+SalesQuarter的值具有唯一性,所以这两条语句的返回结果是相同的,如表9-8所示。
SELECT EmpID, SalesYear, SalesQuarter, SubTotal,
SUM(SubTotal) OVER(PARTITION BY EmpID
ORDER BY EmpID, SalesYear, SalesQuarter
RANGE BETWEEN UNBOUNDED PRECEDING
ANDCURRENT ROW) AS RunSubTotal
FROM dbo.Orders;
SELECT EmpID, SalesYear, SalesQuarter, SubTotal,
SUM(SubTotal) OVER(PARTITION BY EmpID
ORDER BY EmpID, SalesYear, SalesQuarter
ROWS BETWEEN UNBOUNDED PRECEDING
ANDCURRENT ROW) AS RunSubTotal
FROM dbo.Orders;
9.2.3 开窗聚合函数的嵌套
前面我们讲过,窗口的分区与数据分组有类似之处,但是,在一条语句中指定分组列后,对于整个语句你只能按此列进行分组,而分区则可以在一条语句中指定多个不同的分区方式,这两种方式似乎不存在相交之处。实际上,两者也可以结合在一起使用。
仍旧以9.2.1节创建的Orders表为例,假设现在要计算雇员的年度销售额和企业整体的年度销售额,可以使用下面的语句。雇员的年度销售额按SalesYear+EmpID列分区,企业的年度销售额直接按SalesYear分区。查询结果如表9-9所示。
WITH CTE
AS(
SELECTEmpID, SalesYear,
SUM(SubTotal) OVER(PARTITION BY SalesYear, EmpID) AS EmpSubTotal,
SUM(SubTotal) OVER(PARTITION BY SalesYear) AS YearSubTotal
FROMdbo.Orders
)
SELECT DISTINCT * FROM CTE;
表9-9 计算雇员年度销售额和企业年度销售额
EmpID |
SalesYear |
EmpSubTotal |
YearSubTotal |
1 |
2013 |
1000 |
2200 |
2 |
2013 |
1200 |
2200 |
1 |
2014 |
600 |
1400 |
2 |
2014 |
800 |
1400 |
由表9-9可以看出,企业2013年销售额是2200,2014年是1400。2013年雇员1和雇员2的销售额分别是1000和1200。2014年雇员1和雇员2的销售额分别是600和800。
再来看下面一条语句,它的执行结果与表9-5完全相同。
SELECT EmpID, SalesYear,
SUM(SubTotal) AS EmpSubTotal,
SUM(SUM(SubTotal)) OVER(PARTITION BYSalesYear) AS YearSubTotal
FROM dbo.Orders
GROUP BY EmpID, SalesYear
上面这条语句中使用GROUPBY按EmpID+SalesYear进行了分组计算,得到的是每位雇员的年度销售额SUM(SubTotal),而语句中的嵌套开窗函数SUM(SUM(SubTotal))(注意,最外层的SUM是开窗聚合函数,里面的SUM(SubTotal)是每位雇员的年度销售额)是对每位雇员的年度销售额进行求和,从而得到企业的年度销售额。当然,这里有一个问题,语句中第2行的SUM(SubTotal)是GROUP BY的计算结果,相对于第3行中的SUM(SUM(SubTotal))而言,它是一个中间结果,为什么这条语句能够正确执行呢?让我们再来回顾一下在5.10节中介绍的查询的逻辑处理顺序——SELECT子句是在GROUP BY后面执行的,因此SUM(SubTotal)这个中间结果对于开窗函数而言是可见的。不过,在这条语句中只能使用函数嵌套,而不能使用别名EmpSubTotal。我们在5.9节介绍过“同时操作”概念,这时候的别名EmpSubTotal对于后面的SUM函数并不可见。例如,下面语句将引发错误,提示“列名'EmpSubTotal'无效”。
SELECT EmpID, SalesYear,
SUM(SubTotal) AS EmpSubTotal,
SUM(EmpSubTotal) OVER(PARTITION BYSalesYear) AS YearSubTotal
FROM dbo.Orders
GROUP BY EmpID, SalesYear
从上面的分析可以看出,开窗聚合函数支持函数嵌套,但是对于语句可读性而言,增加了阅读难度。可以通过公用表表达式的方法进行简化,参考下面的语句。
WITH CTE AS (
SELECTEmpID, SalesYear, SUM(SubTotal) AS EmpSubTotal
FROMdbo.Orders
GROUP BYEmpID, SalesYear
)SELECT EmpID, SalesYear, EmpSubTotal,
SUM(EmpSubTotal) OVER(PARTITION BY SalesYear) AS YearSubTotal
FROM CTE;
9.2.4 分区聚合计算与联接的比较
前面我们讲过,分区可以使用子查询来代替,此外,也可以通过联结的方法实现类似功能,并且联结有时比子查询和分区更为高效。下面的示例使用在9.1节创建的Students表,现假设需要计算每名学生成绩与本班级平均成绩的差异。我们需要先计算每个班级的平均成绩,然后通过联接的方式将平均成绩关联到相应的学生成绩行,再计算差异。语句如下:
SELECT S1.ClassID,
S1.StudentName,
S1.Achievement,
S2.AvgAch ,
S1.Achievement - S2.AvgAch AS Diff
FROM Students AS S1
LEFT OUTERJOIN (SELECT ClassID, AVG(Achievement) AS AvgAch
FROM Students
GROUP BY ClassID) AS S2 --计算每个班级的平均成绩
ONS1.ClassID = S2.ClassID;
查询结果如表9-10所示。
表9-10 查询每名学生成绩与本班级平均成绩的差异
ClassID |
StudentName |
Achievement |
AvgAch |
Diff |
1 |
Grace |
99.00 |
90.500000 |
8.500000 |
1 |
Andrew |
99.00 |
90.500000 |
8.500000 |
1 |
Janet |
75.00 |
90.500000 |
-15.500000 |
1 |
Margaret |
89.00 |
90.500000 |
-1.500000 |
2 |
Steven |
86.00 |
83.000000 |
3.000000 |
2 |
Michael |
72.00 |
83.000000 |
-11.000000 |
2 |
Robert |
91.00 |
83.000000 |
8.000000 |
3 |
Laura |
75.00 |
85.250000 |
-10.250000 |
3 |
Ann |
94.00 |
85.250000 |
8.750000 |
3 |
Ina |
80.00 |
85.250000 |
-5.250000 |
3 |
Ken |
92.00 |
85.250000 |
6.750000 |
在使用OVER子句的情况下,查询语句会简洁许多,下面语句的查询结果与表9-10相同。
SELECT ClassID,
StudentName,
Achievement,
AVG(Achievement) OVER(PARTITION BY ClassID) AS AvgAch,
Achievement - AVG(Achievement) OVER(PARTITION BY ClassID) AS Diff
FROM Students;
虽然语句有所简洁,但是在性能方面该语句不如上面的联接方式。查询优化器为该语句生成的查询计划比较复杂,与联接语句在同一个批中执行时,含有OVER子句的查询开销占了66%,如图9-3所示。
图9-3 联接方式与OVER子句的性能比较