Linux 内核源代码情景分析 chap 2 存储管理 (四)
物理页面的使用和周转
1. 几个术语
1.1 虚存页面
指虚拟地址空间中一个固定大小, 边界与页面大小 4KB 对齐的区间及其内容
1.2 物理页面
与虚存页面相对的, 需要映射到某种物理存储介质上面的页面。 根据他是否在内存中, 我们可以分为 内存页面 和 盘上页面。
另外, 通常说物理内存页面的分配和释放是指 物理介质, 而谈及页面的换入和换出的时候, 是指他的内容。
1.3 交换技术
当系统内存不够用的时候,我们可以把暂时不用的信息 放到磁盘上, 为其他急用的信息腾出空间, 到需要的时候, 再从磁盘上读进来。
(linux 中 主要使用swap 分区, windows 中使用虚拟内存技术)
早期是基于段式交换的, 可是效率太低, 于是发展成按需页面交换技术。这是一种典型的用时间换空间的做法。
2. 对物理页面的抽象描述
2.1 内存物理页面
在系统的初始化阶段, 内核会根据检测到的物理内存的大小, 为每一个页面都建立一个page结构, 形成一个page数组, 并使用一个全局量 mem_map 指向这个数组。(不过个人感觉, 这是对于UMA 均匀介质而言的, 对于NUMA page 数组应该是从属于 某个node 的)

同时, 又按照需要将这些页面拼合成物理地址连续的许多内存页面块, 然后根据块的大小建立起若干管理区 zone, 而在每个管理区中则设置了一个空闲队列, 以便物理内存页面的分配使用
2.2 交换设备物理页面
2.2.1 swap_info_struct
内核中定义了一个swap_info_struct 数据结构, 用来描述和管理用于页面交换的文件和设备。
==================== include/linux/swap.h 49 64 ====================
49 struct swap_info_struct {
50 unsigned int flags;
51 kdev_t swap_device;
52 spinlock_t sdev_lock;
53 struct dentry * swap_file;
54 struct vfsmount *swap_vfsmnt;
55 unsigned short * swap_map;
56 unsigned int lowest_bit;
57 unsigned int highest_bit;
58 unsigned int cluster_next;
59 unsigned int cluster_nr;
60 int prio; /* swap priority */
61 int pages;
62 unsigned long max;
63 int next; /* next entry on swap list */
64 };其中, swap_map 指向一个数组, 数组中的每个值代表了盘上的一个物理页面, 数组下标决定了页面在盘或者文件中的位置。数组大小与pages 相关。
感觉这个swap_map 和 我们的 mem_map 指针指向一个page 数组的效果非常相似=_=!! <~~ ~.~
特别需要注意的是, 设备上的第一个页面, ie, swap_map[0]所代表的页面时不用于做页面交换的, 他包含了该设备或者文件自身的一些信息, 以及表明哪些页面是可以使用的位图。
我们利用 lowest_bit 和 highest_bit 字段,标记文件从什么地方开始到什么地方结束。利用 max 字段, 标记设备的物理大小。
由于, 我们的磁盘通常都是转动的, 所以在分配盘面空间的时候, 尽可能按照集群cluster 的方式进行, cluster_next 和 cluster_nr 就是为这个来设计的。
由于 linux 允许使用多个页面交换设备(文件), 所以在内核中定义了一个 swap_info_struct 数组
struct swap_info_struct swap_info[MAX_SWAPFILES];同时, 内核还建立了一个队列 swap_list, 将各个可以分配物理页面的磁盘设备或者文件的 swap_info_struct 结构按优先级高低连接在一起。
==================== mm/swapfile.c 23 23 ====================
23 struct swap_list_t swap_list = {-1, -1};
==================== include/linux/swap.h 153 156 ====================
153 struct swap_list_t {
154 int head; /* head of priority-ordered swapfile list */
155 int next; /* swapfile to be used next */
156 };2.2.2 swap_entry_t 页面交换项
类似于 内存中 的pte_t 数据结构, 把物理内存页面和虚存页面建立联系一样, 盘上页面也有一个swp_entry_t 数据结构, 实现类似功能。
==================== include/linux/shmem_fs.h 8 18 ====================
8 /*
9 * A swap entry has to fit into a "unsigned long", as
10 * the entry is hidden in the "index" field of the
11 * swapper address space.
12 *
13 * We have to move it here, since not every user of fs.h is including
14 * mm.h, but m.h is including fs.h via sched .h :-/
15 */
16 typedef struct {
17 unsigned long val;
18 } swp_entry_t;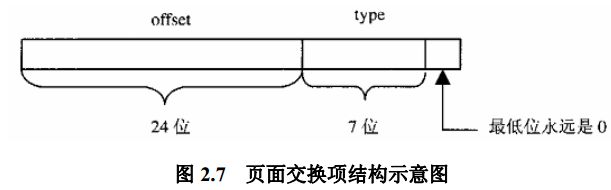
在这里, offset 表示页面在 某个磁盘设备或者文件中的位置, ie, 文件中的逻辑页面号。 直白点讲, 他对应着swap_map 所指向的数组中的下标。
而 type 则是指 该页面在哪个文件中, 是个序号。 直白点来讲, 对应的是swap_info, 这个表征多个页面交换设备的数组中的下标。
另外, swp_entry_t 结构和 pte_t 结构关系非常密切。他们有着相同大小的数据结构。
当一个页面在内存中的时候, 最低位 P 为 1, 其余各位描述该物理内存页面的地址和页面属性。
而当这个页面在磁盘上的时候, 最低位P 为 0, 其余位表示这个页面的去向
3. 磁盘周转
3.1 物理空间管理 __swap_free
==================== mm/swapfile.c 141 182 ====================
141 /*
142 * Caller has made sure that the swapdevice corresponding to entry
143 * is still around or has not been recycled.
144 */
145 void __swap_free(swp_entry_t entry, unsigned short count)
146 {
147 struct swap_info_struct * p;
148 unsigned long offset, type;
149
150 if (!entry.val)
151 goto out;
152
153 type = SWP_TYPE(entry);
154 if (type >= nr_swapfiles)
155 goto bad_nofile;
156 p = & swap_info[type];
157 if (!(p->flags & SWP_USED))
158 goto bad_device;
159 offset = SWP_OFFSET(entry);
160 if (offset >= p->max)
161 goto bad_offset;
162 if (!p->swap_map[offset])
163 goto bad_free;
164 swap_list_lock();
165 if (p->prio > swap_info[swap_list.next].prio)
166 swap_list.next = type;
167 swap_device_lock(p);
168 if (p->swap_map[offset] < SWAP_MAP_MAX) {
169 if (p->swap_map[offset] < count)
170 goto bad_count;
171 if (!(p->swap_map[offset] -= count)) {
172 if (offset < p->lowest_bit)
173 p->lowest_bit = offset;
174 if (offset > p->highest_bit)
175 p->highest_bit = offset;
176 nr_swap_pages++;
177 }
178 }
179 swap_device_unlock(p);
180 swap_list_unlock();
181 out:
182 return;需要注意的是, 释放磁盘页面内容的操作, 实际上并不涉及磁盘操作, 只是内存中的 “账面操作”, 表示磁盘上那个页面的内容已经作废了。 因而, 花费是非常小的。
3.2 内存页面周转的含义
含义有两方面:
1. 页面分配,使用和回收, 并不一定涉及页面的盘区交换
2. 盘区交换, 最终目的是为了页面的回收。
对于用户空间中的页面, 及涉及分配, 使用和回收, 还涉及页面的换入和换出, 即使是进程的代码段, 从系统角度看待, 都是动态分配的。
对于映射到系统空间的页面都不会被换出。只会有用完了之后, 需要释放的问题, 有些页面获取比较费劲, 可能还会采用 LRU 队列。
3.2.1 页面交换策略
- 最简单的策略就是即用即分配, 但是可想而知效率很低
- 使用LRU, ie, 最近最少用到的页面交换策略, 但是可能会引起 页面 抖动。
- 为了减少抖动, 引入暂存队列
- 加入页面 脏, 干净 等状态, 进一步优化
3.2.2 物理内存页面换入换出的周转要点
- 空闲, 此时page 在 某个zone 管理区的free_area 队列中。 页面引用计数为 0.
- 分配, 分配页面, 引用计数 为 1, page 不在处于 free_area队列中。
- 活跃状态, 通过 lru 结构连入 active_list, 递增引用计数
- 不活跃状态(脏), 利用lru 连入 inactive_dirty_list, 递减引用计数
- 将不活跃脏内容写入交换设备, 并将其移动到 inactive_clean_list 中
- 不活跃状态(干净)
- 如果在转入不活跃状态后一段时间内收到访问, 转入活跃状态, 恢复映射
- 如果需要, 可以从干净队列中回收页面, 或者回到空闲队列, 或者另行分配。
用我自己的语言来解释一下:
我们先分配了一个页面, 然后这个页面处于 活动状态 active, 然后, 我们暂时不去访问它了, 他就开始老化, 进入inactive 不活动(脏)状态, 但这时候, 我们不是立即写入交换设备, 等再过一段时间, 确实没人访问, 我们将它写入交换设备, 但是这部分页面, 我们还是没有释放哦, 他被标记为 inactive 不活动(干净) 状态, 现在是由相应的存储区 zone 来管理了, 之前是由全局队列管理的。如果在这个页面被用作其他用途之前, 又被访问了, 直接建立映射就好了, 通过这种方法, 减少了页面的抖动现象
3.2.3 策略实现
- 全局LRU 队列, active_list 和 inactive_dirty_list
- 每个页面管理区设置 inactive_clean_list
- 全局 address_space 数据结构 swapper_space
- 为加快搜索, 引入 page_hash_table
下面来看下, 内核中交换的代码
3.2.3.1 code
==================== mm/swap_state.c 54 70 ====================
54 void add_to_swap_cache(struct page *page, swp_entry_t entry)
55 {
56 unsigned long flags;
57
58 #ifdef SWAP_CACHE_INFO
59 swap_cache_add_total++;
60 #endif
61 if (!PageLocked(page))
62 BUG();
63 if (PageTestandSetSwapCache(page))
64 BUG();
65 if (page->mapping)
66 BUG();
67 flags = page->flags & ~((1 << PG_error) | (1 << PG_arch_1));
68 page->flags = flags | (1 << PG_uptodate);
69 add_to_page_cache_locked(page, &swapper_space, entry.val);
70 }
==================== mm/filemap.c 476 494 ====================
476 /* 477 * Add a page to the inode page cache. 478 * 479 * The caller must have locked the page and 480 * set all the page flags correctly.. 481 */
482 void add_to_page_cache_locked(struct page * page, struct address_space *mapping, unsigned long index)
483 {
484 if (!PageLocked(page))
485 BUG();
486
487 page_cache_get(page);
488 spin_lock(&pagecache_lock);
489 page->index = index;
490 add_page_to_inode_queue(mapping, page);
491 add_page_to_hash_queue(page, page_hash(mapping, index));
492 lru_cache_add(page);
493 spin_unlock(&pagecache_lock);
494 }
==================== include/linux/fs.h 365 375 ====================
365 struct address_space {
366 struct list_head clean_pages; /* list of clean pages */
367 struct list_head dirty_pages; /* list of dirty pages */
368 struct list_head locked_pages; /* list of locked pages */
369 unsigned long nrpages; /* number of total pages */
370 struct address_space_operations *a_ops; /* methods */
371 struct inode *host; /* owner: inode, block_device */
372 struct vm_area_struct *i_mmap; /* list of private mappings */
373 struct vm_area_struct *i_mmap_shared; /* list of shared mappings */
374 spinlock_t i_shared_lock; /* and spinlock protecting it */
375 };
==================== mm/swap_state.c 31 37 ====================
31 struct address_space swapper_space = {
32 LIST_HEAD_INIT(swapper_space.clean_pages),
33 LIST_HEAD_INIT(swapper_space.dirty_pages),
34 LIST_HEAD_INIT(swapper_space.locked_pages),
35 0, /* nrpages */
36 &swap_aops,
37 };
==================== include/linux/mm.h 150 150 ====================
150 #define get_page(p) atomic_inc(&(p)->count)
==================== include/linux/pagemap.h 31 31 ====================
31 #define page_cache_get(x) get_page(x)
==================== mm/filemap.c 72 79 ====================
72 static inline void add_page_to_inode_queue(struct address_space *mapping, struct page * page)
73 {
74 struct list_head *head = &mapping->clean_pages;
75
76 mapping->nrpages++;
77 list_add(&page->list, head);
78 page->mapping = mapping;
79 }
==================== mm/filemap.c 58 70 ====================
58 static void add_page_to_hash_queue(struct page * page, struct page **p)
59 {
60 struct page *next = *p;
61
62 *p = page;
63 page->next_hash = next;
64 page->pprev_hash = p;
65 if (next)
66 next->pprev_hash = &page->next_hash;
67 if (page->buffers)
68 PAGE_BUG(page);
69 atomic_inc(&page_cache_size);
70 }
==================== include/linux/pagemap.h 68 68 ====================
68 #define page_hash(mapping,index) (page_hash_table+_page_hashfn(mapping,index))
==================== mm/swap.c 226 241 ====================
226 /** 227 * lru_cache_add: add a page to the page lists 228 * @page: the page to add 229 */
230 void lru_cache_add(struct page * page)
231 {
232 spin_lock(&pagemap_lru_lock);
233 if (!PageLocked(page))
234 BUG();
235 DEBUG_ADD_PAGE
236 add_page_to_active_list(page);
237 /* This should be relatively rare */
238 if (!page->age)
239 deactivate_page_nolock(page);
240 spin_unlock(&pagemap_lru_lock);
241 }
==================== include/linux/swap.h 209 215 ====================
209 #define add_page_to_active_list(page) { \
210 DEBUG_ADD_PAGE \
211 ZERO_PAGE_BUG \
212 SetPageActive(page); \
213 list_add(&(page)->lru, &active_list); \
214 nr_active_pages++; \
215 }
从add_to_page_cache_locked 函数中, 我们可以知道, 页面page 被加入到了 3 个队列中:
1. 利用 list 加入暂存队列 swapper_space
2. 利用next_hash 和 pprev_hash 加入 hash_queue
3. 利用 lru 加入 LRU 队列 active_list
3.3 用户参与内存管理
特权用户可以通过 swapon, swapoff 参与存储管理等。