大型网站架构演变及缓存技术
网站架构的演变:
1,从一个小网站开始:一台服务器,只有文件和数据库。
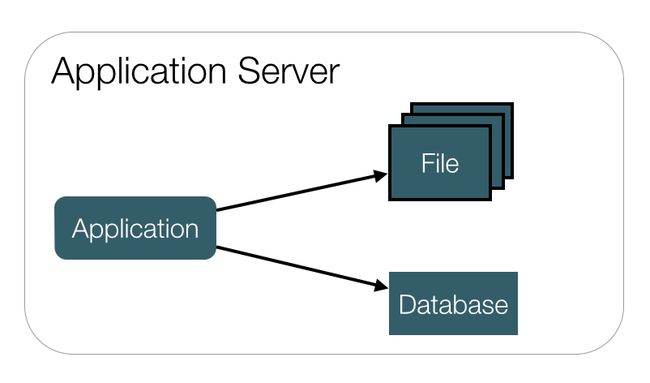
2,数据服务与应用服务分离:应用服务器更好的CPU,数据服务器更快更大的硬盘。动静态资源分离。
3,使用缓存:1,客户端缓存(浏览器,)2,前端页面缓存(squid)3,页面片段缓存ESI(Edge Side Includes)4,应用服务器本地缓存 5,远程分布式缓存
4,服务器增多,使用服务器集群和负载均衡。
这会引来Session的管理问题,有以下几种方案解决:1,Session Sticky,就是在负载均衡服务器(load balancer)上保存Session,但是如果服务器重启,则Session都会清除掉,不够稳定。2,Session Copy,就是在各个应用服务器上复制并保存Session,这适用于服务器机器数目较少的情况,但会占用应用服务器的带宽和内存。3,Cookies,每个用户访问时自带Cookies,但是Cookies自身长度有限,携带信息有限,并且会消耗服务器外部带宽,不够安全,当请求数目过多时,影响应用服务器性能。4,在应用服务器后面加个Session处理服务器,适用于Session数目大和服务器充足的情况。
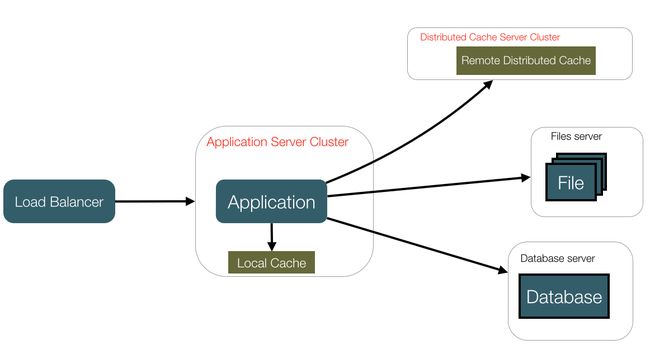
5,当数据库读性能下降时,实施读写分离,将读操作引向slave数据库。数据库负载均衡。
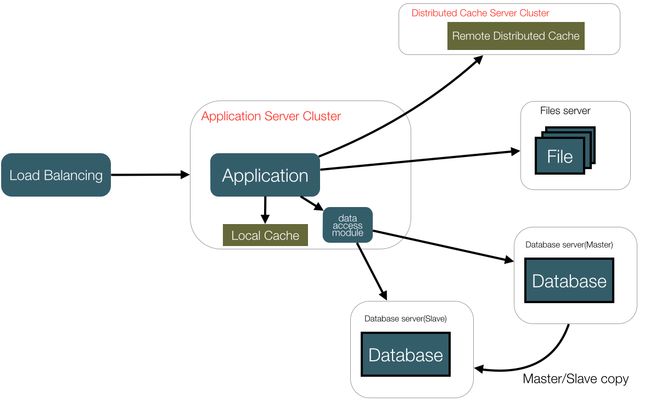
6,反向代理和CDN加速,解决不同地区的访问速度问题。

7,使用分布式文件系统,如:Lustre,HDFS,GFS,TFS,FreeNas等。

8,数据库分库(垂直切分),可按照功能模块等分为用户数据库,产品数据库,交易数据库等。
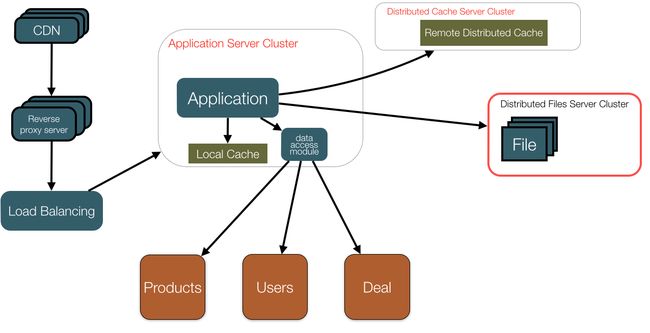
当单个数据库的性能达到瓶颈时,进行水平切分,将某个数据表如User表分开为多个结构相同的数据库。水平切分会碰到SQL的路由问题,分页查询,跨库跨表的Join等问题。可以使用分布式缓存方案解决部分场景使用,如Memcached,Redis等

图片来源http://www.codeceo.com/article/web-artch-perform.html
Web缓存的规则:
- 如果请求信息是需要认证或者安全加密的(如, HTTPS),相应内容也不会被缓存;可以通过
Cache-Control: public头的设置使其公有。HTTP 1.1标准兼容的缓存服务器可以使之缓存。 - 缓存如果有以下表现,则认为是fresh新鲜的(无需检查源服务器,直接发送给客户端):
- 含有完整的过期时间和寿命控制头信息,并且内容仍在保鲜期内,或者
- 缓存最近已展现,并且在不久前修改。则内容缓存直取,绕过源服务器。
- 若内容陈旧,则会要求源服务器做验证validate,或者告诉缓存其拷贝副本是否是OK的。
Cache-Control
响应头信息,让网站的发布者可以更全面的控制他们的内容,更好地处理Expires的些限制。
Cache-Control
有用的响应头包括:
- max-age=[秒]:表示在这个时间范围内缓存是新鲜的无需更新。类似Expires时间,不过这个时间是相对的,而不是绝对的。也就是某次请求成功后多少秒内缓存是新鲜的。
- s-maxage=[秒]:类似
max-age, 除了仅应用于共享缓存(如代理)。 - public:标记认证的响应才能够被缓存。一般而言,需要认证HTTP请求内容会自动私有化(不会被缓存Add)。
- private:允许缓存专门为某一个用户存储响应,比方说在浏览器中;共享缓存一般不会,例如在代理中。
- no-cache:每次在释放缓存副本之前都强制发送请求给源服务器进行验证,这在确保认证有效性上很管用或者保证内容必须是即时的,不得无视缓存的所有优点,如国内的微博、twitter等的刷新显示。
- no-store:强制缓存在任何情况下都不要保留任何副本。
- must-revalidate:告诉缓存,我给你准备了一些关于新鲜度的信息,在表现的时候要严格遵循之。HTTP允许缓存在某些特定情况下返回过期数据,指定了这个属性,相对于告诉缓存,你丫必须严格遵循我的规则。
- proxy-revalidate:类似
must-revalidate,除了只能应用于代理缓存。如:Cache-Control: max-age=3600, must-revalidate
Last-Modified
头信息通信确定文档最后的修改时间,如果缓存有内容存储,会包含
Last-Modified
信息的,辅助
If-Modified-Since
请求,我们可以询问服务器内容是否改变了。
HTTP 1.1引入了一个新的验证器,称为
Etag。Etag
是每次展现内容改变时候由服务器生成的唯一标识符,由于服务器控制
ETag
如何生成,当缓存发起
If-None-Match
请求的时候,如果
Etag
匹配,就可以确定展示内容其实是一样的。
典型的Web资源 可以一个Web页,但也可能是JSON或XML文档。服务器单独负责判断记号是什么及其含义,并在HTTP响应头中将其传送到客户端,以下是服务器端返回的格式:ETag:“50b1c1d4f775c61:df3”客户端的查询更新格式是这样的:If-None-Match : W / “50b1c1d4f775c61:df3”如果ETag没改变,则返回状态304然后不返回,这也和Last-Modified一样。测试Etag主要 在断点下载时比较有用。
- 保持URL稳定:这是缓存的金科玉律,如果你为不同页面,不同用户或不同网站提供相同的内容,他们应该使用相同的URL. 这是简单却非常行之有效的方法。例如,你的HTML中的某个引用地址是
"/index.html", 则要一直使用这个地址。 - 不同地方的图片和其他元素使用同一库。
- 对于不经常改变的图片/页面启用缓存,通过将
Cache-Control: max-age头信息的值设大一点。 - 对于定期更新的内容通过指定
max-age或过期时间实现缓存。 - 如果资源改变了(尤其下载文件),改变其名字。由于一般这种资源会有很长的过期时间,而服务器上一直是正确的版本;因此,链接这个下载资源的页面需要要比较短的过期时间(//zxx: 我司页面5分钟过期)。否则,会出现服务器的资源是新的,但页面被缓存了,其中的链接地址还是旧的,就会出现新旧版本冲突的可能Add。
- 万不得已不要变动文件:否则你要设置一个新的
Last-Modified值。另外,当你更新站点的时候,只要上传改动的那些文件,而不要把整个站点都覆盖过去。 - Cookie能不用就不用:Cookie难以被缓存,且大多情境下是没有必要的。如果你非得使用Cookie,建议用在动态页面上。
- 减少SSL的使用:因为共享缓存不能存储认证页面,只在必要的时候使用,并且在SSL页面上减少图片的使用。
- 使用REDbot检查你的网站。