GCC后端及汇编发布(5)
3.2.3. 向决策序列加入模式的 RTL 模板
对于上面我们的 define_insn 例子,在 2467 行,被传给 add_to_sequence 的类型是 RECOG 。而参数 pattern 是这个 define_insn 模式的 RTL 模板。对于我们的例子是:
[(set (reg 17)
(compare (match_operand:DI 0 "nonimmediate_operand" "r,?mr")
(match_operand:DI 1 "const0_operand" "n,n")))]
767 static struct decision *
768 add_to_sequence (rtx pattern, struct decision_head *last, in genrecog.c
769 const char *position, enum routine_type insn_type, int top)
770 {
771 RTX_CODE code;
772 struct decision *this, *sub;
773 struct decision_test *test;
774 struct decision_test **place;
775 char *subpos;
776 size_t i;
777 const char *fmt;
778 int depth = strlen (position);
779 int len;
780 enum machine_mode mode;
781
782 if (depth > max_depth )
783 max_depth = depth;
784
785 subpos = xmalloc (depth + 2);
786 strcpy (subpos, position);
787 subpos[depth + 1] = 0;
788
789 sub = this = new_decision (position, last);
790 place = &this->tests;
791
792 restart:
793 mode = GET_MODE (pattern);
794 code = GET_CODE (pattern);
795
796 switch (code)
797 {
798 case PARALLEL:
…
819 break ;
820
821 case MATCH_PARALLEL:
…
831 case MATCH_OPERAND:
832 case MATCH_SCRATCH:
833 case MATCH_OPERATOR:
834 case MATCH_INSN:
835 {
…
915 }
916
917 case MATCH_OP_DUP:
…
932 goto fini;
933
934 case MATCH_DUP:
935 case MATCH_PAR_DUP:
936 code = UNKNOWN;
937
938 test = new_decision_test (DT_dup, &place);
939 test->u.dup = XINT (pattern, 0);
940 goto fini;
941
942 case ADDRESS:
943 pattern = XEXP (pattern, 0);
944 goto restart;
945
946 default :
947 break ;
948 }
当以 SET 码进入这个函数时,它将进入 946 行的 default 语句。在这个层次上,参数 position 是一个空字符串( “” )。并且注意到在 789 行,变量 sub 及 test 指向相同的新分配的决策实例。参见下面的 new_decision 。
316 static struct decision *
317 new_decision (const char *position, struct decision_head *last) in genrecog.c
318 {
319 struct decision *new = xcalloc (1, sizeof (struct decision));
320
321 new->success = *last;
322 new->position = xstrdup (position);
323 new->number = next_number ++;
324
325 last->first = last->last = new;
326 return new;
327 }
在 789 行,传递给 new_decision 的第二个参数是在 make_insn_sequence 的 2421 行声明的变量 head 。这个新的 decision 从头部链入,正如下图所示。
图 5 : 向决策序列加入 RTL 模板,图 1
add_to_sequence (continued)
950 fmt = GET_RTX_FORMAT (code);
951 len = GET_RTX_LENGTH (code);
952
953 /* Do tests against the current node first. */
954 for (i = 0; i < (size_t) len; i++)
955 {
956 if (fmt[i] == 'i')
957 {
958 if (i == 0)
959 {
960 test = new_decision_test (DT_elt_zero_int, &place);
961 test->u.intval = XINT (pattern, i);
962 }
963 else if (i == 1)
964 {
965 test = new_decision_test (DT_elt_one_int, &place);
966 test->u.intval = XINT (pattern, i);
967 }
968 else
969 abort ();
970 }
971 else if (fmt[i] == 'w')
972 {
973 /* If this value actually fits in an int, we can use a switch
974 statement here, so indicate that. */
975 enum decision_type type
976 = ((int) XWINT (pattern, i) == XWINT (pattern, i))
977 ? DT_elt_zero_wide_safe : DT_elt_zero_wide;
978
979 if (i != 0)
980 abort ();
981
982 test = new_decision_test (type, &place);
983 test->u.intval = XWINT (pattern, i);
984 }
985 else if (fmt[i] == 'E')
986 {
987 if (i != 0)
988 abort ();
989
990 test = new_decision_test (DT_veclen, &place);
991 test->u.veclen = XVECLEN (pattern, i);
992 }
993 }
在这里,我们再一次根据其格式处理模式。对于格式中的每个元素,通过 new_decision_test 构建了一个 decision_test 的实例。它定义了将要进行的测试。
331 static struct decision_test * in genrecog.c
332 new_decision_test (enum decision_type type, struct decision_test ***pplace)
333 {
334 struct decision_test **place = *pplace;
335 struct decision_test *test;
336
337 test = xmalloc (sizeof (*test));
338 test->next = *place;
339 test->type = type;
340 *place = test;
341
342 place = &test->next;
343 *pplace = place;
344
345 return test;
346 }
上面,在这里传递给 new_decision_test 的第二个参数——声明在 add_to_sequence 的 790 行的变量 place ,指向变量 this 的 tests 域,这个变量是在 add_to_sequence 的 789 行构建的一个 decision 实例,同时在 make_insn_sequence 的 2421 行 this 链入以变量 head 开头的链表。
这个函数看起来有点晕,让我们一步一步来看。
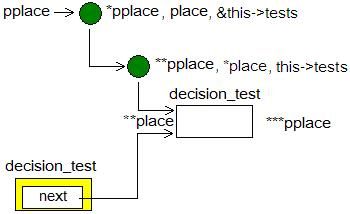
图 6 : new_decision_test ,步骤 1
直到 339 行,我们可以得到如上图所示的数据。看到新构建的 decision_test 的 next 域指向旧的 decision_test 。那么在 440 行, pplace , place 及 this->tests 都指向这个新节点,如下图所示。
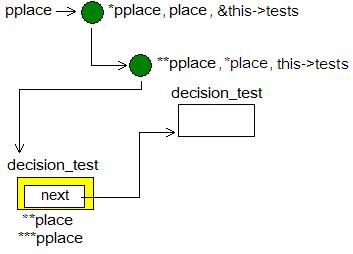
图 7 : new_decision_test ,步骤 2
在 new_decision_test 的余下部分, place 及 pplace 将指向新节点的 next 域的地址,如下图所示。
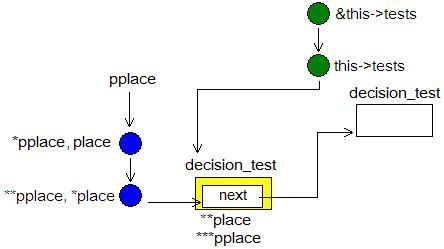
图 8 : new_decision_test ,步骤 3
然后对于下一个加入的节点(黄色),直到 340 行,我们可以得到以下图形。
图 9 : new_decision_test ,步骤 4
最后, pplace , place 将指向这个新加入的节点(黄色)。
图 10 : new_decision_test ,步骤 5
从这些图形,我们可以看到对于进一步加入的节点,它们将被插入到初始节点与上一个被加入节点之间。这意味着对于加入节点序列 1 , 2 , 3 , … , n ,我们将得到以下的列表:
This à tests à 1 à 2 à 3… à n à 初始节点
对于我们的情形, rtx 对象 SET 具有格式‘ ee ’, 954 到 993 行的 FOR 块将不做任何事。
add_to_sequence (continued)
995 /* Now test our sub-patterns. */
996 for (i = 0; i < (size_t) len; i++)
997 {
998 switch (fmt[i])
999 {
1000 case 'e': case 'u':
1001 subpos[depth] = '0' + i;
1002 sub = add_to_sequence (XEXP (pattern, i), &sub->success,
1003 subpos, insn_type, 0);
1004 break ;
1005
1006 case 'E':
1007 {
1008 int j;
1009 for (j = 0; j < XVECLEN (pattern, i); j++)
1010 {
1011 subpos[depth] = 'a' + j;
1012 sub = add_to_sequence (XVECEXP (pattern, i, j),
1013 &sub->success, subpos, insn_type, 0);
1014 }
1015 break ;
1016 }
1017
1018 case 'i': case 'w':
1019 /* Handled above. */
1020 break ;
1021 case '0':
1022 break ;
1023
1024 default :
1025 abort ();
1026 }
1027 }
在 954 行的 FOR 块之后,是另一个 FOR 块。对于我们的例子,它将进入 1000 行的 CASE 块。在 1001 行的 subpos 保存了这个递归的深度信息。它包含了形如“ 0123abc45ab ”的信息,其中数字用于显示格式元素的序列,而字母用于显示对应某些格式(即‘ E ’,‘ V ’)的 rtx 向量的序列。然后为这个 SET 对象的两个孩子调用 add_to_sequence 。
对于第一个孩子 reg 对象,在 add_to_sequence 中,它直接跑到 fini 标签处。因为其编码是 REG ,在 1035 行构建了一个新的 decision_test ,并在 decision 中,链入在其父亲的之后。而且对于我们的 reg 对象,其 mode 是 VOIDmode ,正如我们之前看到的。
对于第二个孩子 compare 对象,它的处理路径与 set 对象相同。在 1000 行它为其孩子调用 add_to_sequence 。
add_to_sequence (continued)
1029 fini:
1030 /* Insert nodes testing mode and code, if they're still relevant,
1031 before any of the nodes we may have added above. */
1032 if (code != UNKNOWN)
1033 {
1034 place = &this->tests;
1035 test = new_decision_test (DT_code, &place);
1036 test->u.code = code;
1037 }
1038
1039 if (mode != VOIDmode)
1040 {
1041 place = &this->tests;
1042 test = new_decision_test (DT_mode, &place);
1043 test->u.mode = mode;
1044 }
1045
1046 /* If we didn't insert any tests or accept nodes, hork. */
1047 if (this->tests == NULL)
1048 abort ();
1049
1050 ret:
1051 free (subpos);
1052 return sub;
1053 }
现在对于在这个 compare 对象的第二个孩子,其编码是 MATCH_OPERAND ,将进入 add_to_sequence 中以下部分的代码。
add_to_sequence (continued)
831 case MATCH_OPERAND:
832 case MATCH_SCRATCH:
833 case MATCH_OPERATOR:
834 case MATCH_INSN:
835 {
836 const char *pred_name;
837 RTX_CODE was_code = code;
838 int allows_const_int = 1;
839
840 if (code == MATCH_SCRATCH)
841 {
842 pred_name = "scratch_operand";
843 code = UNKNOWN;
844 }
845 else
846 {
847 pred_name = XSTR (pattern, 1);
848 if (code == MATCH_PARALLEL)
849 code = PARALLEL;
850 else
851 code = UNKNOWN;
852 }
853
854 if (pred_name[0] != 0)
855 {
856 test = new_decision_test (DT_pred, &place);
857 test->u.pred.name = pred_name;
858 test->u.pred.mode = mode;
859
860 /* See if we know about this predicate and save its number.
861 If we do, and it only accepts one code, note that fact.
862
863 If we know that the predicate does not allow CONST_INT,
864 we know that the only way the predicate can match is if
865 the modes match (here we use the kludge of relying on the
866 fact that "address_operand" accepts CONST_INT; otherwise,
867 it would have to be a special case), so we can test the
868 mode (but we need not). This fact should considerably
869 simplify the generated code. */
870
871 for (i = 0; i < NUM_KNOWN_PREDS; i++)
872 if (! strcmp (preds [i].name, pred_name))
873 break ;
874
875 if (i < NUM_KNOWN_PREDS)
876 {
877 int j;
878
879 test->u.pred.index = i;
880
881 if (preds [i].codes[1] == 0 && code == UNKNOWN)
882 code = preds [i].codes[0];
883
884 allows_const_int = 0;
885 for (j = 0; preds [i].codes[j] != 0; j++)
886 if (preds [i].codes[j] == CONST_INT)
887 {
888 allows_const_int = 1;
889 break ;
890 }
891 }
892 else
893 test->u.pred.index = -1;
894 }
895
896 /* Can't enforce a mode if we allow const_int. */
897 if (allows_const_int)
898 mode = VOIDmode;
899
900 /* Accept the operand, ie. record it in `operands'. */
901 test = new_decision_test (DT_accept_op, &place);
902 test->u.opno = XINT (pattern, 0);
903
904 if (was_code == MATCH_OPERATOR || was_code == MATCH_PARALLEL)
905 {
906 char base = (was_code == MATCH_OPERATOR ? '0' : 'a');
907 for (i = 0; i < (size_t) XVECLEN (pattern, 2); i++)
908 {
909 subpos[depth] = i + base;
910 sub = add_to_sequence (XVECEXP (pattern, 2, i),
911 &sub->success, subpos, insn_type, 0);
912 }
913 }
914 goto fini;
915 }
这个代码类似于 validate_pattern 的那部分。当我们的例子模式通过这个函数时,我们可以得到以下的树。
图 11 :向决策序列加入 RTL 模板,图 2
然后我们从 add_to_sequence 返回到 make_insn_sequence 。在 2469 行的 last 指向,由 add_to_sequence 返回的,上图中 poistion 域是“ 11 ”的 decision 。
make_insn_sequence (continued)
2465 /* Find the end of the test chain on the last node. */
2466 for (test = last->tests; test->next; test = test->next)
2467 continue ;
2468 place = &test->next;
2469
2470 /* Skip the C test if it's known to be true at compile time. */
2471 if (truth == -1)
2472 {
2473 /* Need a new node if we have another test to add. */
2474 if (test->type == DT_accept_op)
2475 {
2476 last = new_decision (c_test_pos, &last->success);
2477 place = &last->tests;
2478 }
2479 test = new_decision_test (DT_c_test, &place);
2480 test->u.c_test = c_test;
2481 }
2482
2483 test = new_decision_test (DT_accept_insn, &place);
2484 test->u.insn.code_number = next_insn_code ;
2485 test->u.insn.lineno = pattern_lineno ;
2486 test->u.insn.num_clobbers_to_add = 0;
在 2475 行, truth 是 2418 行的 maybe_eval_c_test 的结果。正如我们已经在 genconditions 中看到的, maybe_eval_c_test 将返回 -1 ,如果条件测试部分不是编译时常量。对于我们的例子,这个条件测试部分是:
"TARGET_64BIT && ix86_match_ccmode (insn, CCNOmode)"
函数 ix86_match_ccmode 不是编译时的常量,因此 truth 在这里将是 -1 (参见 2475 行)。注意到在 2471 行, place 指向最后一个 test 节点 next 域的地址,在执行了上面的代码后,我们可以得到下面的树。
图 12 : 向决策序列加入 RTL 模板,图 3
make_insn_sequence (continued)
2492 switch (type)
2493 {
2494 case RECOG:
2495 /* If this is a DEFINE_INSN and X is a PARALLEL, see if it ends
2496 with a group of CLOBBERs of (hard) registers or MATCH_SCRATCHes.
2497 If so, set up to recognize the pattern without these CLOBBERs. */
2498
2499 if (GET_CODE (x) == PARALLEL)
2500 {
2501 int i;
2502
2503 /* Find the last non-clobber in the parallel. */
2504 for (i = XVECLEN (x, 0); i > 0; i--)
2505 {
2506 rtx y = XVECEXP (x, 0, i - 1);
2507 if (GET_CODE (y) != CLOBBER
2508 || (GET_CODE (XEXP (y, 0)) != REG
2509 && GET_CODE (XEXP (y, 0)) != MATCH_SCRATCH))
2510 break ;
2511 }
2512
2513 if (i != XVECLEN (x, 0))
2514 {
2515 rtx new;
2516 struct decision_head clobber_head;
2517
2518 /* Build a similar insn without the clobbers. */
2519 if (i == 1)
2520 new = XVECEXP (x, 0, 0);
2521 else
2522 {
2523 int j;
2524
2525 new = rtx_alloc (PARALLEL);
2526 XVEC (new, 0) = rtvec_alloc (i);
2527 for (j = i - 1; j >= 0; j--)
2528 XVECEXP (new, 0, j) = XVECEXP (x, 0, j);
2529 }
2530
2531 /* Recognize it. */
2532 memset (&clobber_head, 0, sizeof (clobber_head));
2533 last = add_to_sequence (new, &clobber_head, "", type, 1);
2534
2535 /* Find the end of the test chain on the last node. */
2536 for (test = last->tests; test->next; test = test->next)
2537 continue ;
2538
2539 /* We definitely have a new test to add -- create a new
2540 node if needed. */
2541 place = &test->next;
2542 if (test->type == DT_accept_op)
2543 {
2544 last = new_decision ("", &last->success);
2545 place = &last->tests;
2546 }
2547
2548 /* Skip the C test if it's known to be true at compile
2549 time. */
2550 if (truth == -1)
2551 {
2552 test = new_decision_test (DT_c_test, &place);
2553 test->u.c_test = c_test;
2554 }
2555
2556 test = new_decision_test (DT_accept_insn, &place);
2557 test->u.insn.code_number = next_insn_code ;
2558 test->u.insn.lineno = pattern_lineno ;
2559 test->u.insn.num_clobbers_to_add = XVECLEN (x, 0) - i;
2560
2561 merge_trees (&head, &clobber_head);
2562 }
2563 }
2564 break ;
2565
2566 case SPLIT:
2567 /* Define the subroutine we will call below and emit in genemit. */
2568 printf ("extern rtx gen_split_%d (rtx *);/n", next_insn_code );
2569 break ;
2570
2571 case PEEPHOLE2:
2572 /* Define the subroutine we will call below and emit in genemit. */
2573 printf ("extern rtx gen_peephole2_%d (rtx, rtx *);/n",
2574 next_insn_code);
2575 break ;
2576 }
2577
2578 return head;
2579 }
对于我们的例子模式,其类型是 RECOG ,并且其编码是 SET ,因此在函数余下部分不做任何事。
回到 main ,在 make_insn_sequence 返回了这棵树的根节点后,这个根节点作为第二个参数传递给 merge_trees 。我们的例子模式是 i386.md 中的第一个 define_insn 模式,因此 recog_tree 全是 0 ,并在 1407 行返回。
为了更贴近地看 merge_trees 可以为我们做什么,我们需要另一个模式。在 i386.md 里,跟着我们例子的下一个 define_insn 模式是:
497 (define_insn "*cmpdi_minus_1_rex64"
498 [(set (reg 17)
499 (compare (minus:DI (match_operand:DI 0 "nonimmediate_operand" "rm,r")
500 (match_operand:DI 1 "x86_64_general_operand" "re,mr"))
501 (const_int 0)))]
502 "TARGET_64BIT && ix86_match_ccmode (insn, CCGOCmode)"
503 "cmp{q}/t{%1, %0|%0, %1}"
504 [(set_attr "type" "icmp")
505 (set _attr "mode" "DI")])
而在 make_insn_sequence 处理之后,对于该模式我们可以得到以下的树。