hadoop2.7.2基于centos完全分布式安装
作为linux和hadoop小白,初次安装hadoop真是心累,用了两天时间才安装成功。下面就介绍下Hadoop安装:
一、机器配置和安装说明
一台笔记本、 vmware 、I7处理器 。centos—7系统。hadoop使用2.7.2
二、利用vmware 安装 三个节点。(此处可以先建立一个centos虚拟机,因为后面需要安装jdk,hadoop,还要配置环境变量,可以利用虚拟机克隆的方法得到另外两个节点,省去了很多时间和麻烦。当然之后还要修改不同节点的hostname 。建议此种方案!)
1、首先是安装jdk了。此处不多说,网上很多,我用的是jdk-1.8.0_77
2、按照hadoop集群的基本要求,其中一个是master结点,主要是用于运行hadoop程序中的namenode、secondorynamenode和ResourceManager任务。另外两个结点均为slave结点,其中一个是用于冗余目的,如果没有冗余,就不能称之为hadoop了,所以模拟hadoop集群至少要有3个结点,如果电脑配置非常高,可以考虑增加一些其它的结点。slave结点主要将运行hadoop程序中的datanode和nodeManager任务。
所以,在准备好这3个结点之后,需要分别将linux系统的主机名重命名(因为前面是复制和粘帖操作产生另两上结点,此时这3个结点的主机名是一样的),重命名主机名的方法:
所以,在准备好这3个结点之后,需要分别将linux系统的主机名重命名(因为前面是复制和粘帖操作产生另两上结点,此时这3个结点的主机名是一样的),重命名主机名的方法:
命令:vi /etc/hostname(完全修改)
通过修改hostname文件即可,这三个点结均要修改,以示区分。
以下是我对三个结点的ubuntu系统主机分别命名为:master, node1, node2.
三、每台linux虚拟机配置静态IP
命令: cd /etc/sysconfig/network-scripts/
vi ifcfg-eth1
将DHCP修改成static,增加IP地址,MAC地址,子网掩码、网关等。网上centos7很多.
四、修改hosts文件。
命令:vi /etc/hosts
master ip地址(192.***.***.***)
node1 ip地址()
node2 ip地址()
五、建立hadoop 运行账号(此步骤在建立linux系统时 很多人应该做了)
sudo groupadd hadoop //设置hadoop用户组
sudo useradd –s /bin/bash –d /home/hadoop –m hadoop –g hadoop –G admin //添加一个zhm用户,此用户属于hadoop用户组,且具有admin权限。
sudo passwd hadoop //设置用户zhm登录密码
su hadoop //切换到zhm用户中
六、配置ssh免密码接入。
无密码登陆,效果也就是在master上,通过 ssh node1或 ssh node2 就可以登陆到对方计算机上。而且不用输入密码。
1.三台虚拟机上,使用 ssh-keygen -t rsa,一路按回车就行了。这部主要是设置ssh的密钥和密钥的存放路径。 路径为~/.ssh下。打开~/.ssh 下面有三个文件:authorizedkeys(已认证的keys),idrsa(私钥),id_rsa.pub(公钥)
1.三台虚拟机上,使用 ssh-keygen -t rsa,一路按回车就行了。这部主要是设置ssh的密钥和密钥的存放路径。 路径为~/.ssh下。打开~/.ssh 下面有三个文件:authorizedkeys(已认证的keys),idrsa(私钥),id_rsa.pub(公钥)
2.在master上将公钥放到authorizedkeys里。命令:sudo cat idrsa.pub>>authorized_keys
3.将master上的authorized_keys放到node1和node2的~/.ssh目录下。
命令:sudo scp authorized_keys [email protected]:~/.ssh
用法:sudo scp authorized_keys 远程主机用户名@远程主机名或ip:存放路径。
4.修改authorizedkeys权限,命令:chmod 644 authorizedkeys

5.测试是否成功
ssh node1 输入用户名密码,然后退出,再次ssh node1不用密码,直接进入系统。这就表示成功了。
6.exit退出回到原节点。
七、下载并解压hadoop安装包
hadoop安装包放在了/home/hadoop下面
命令:tar –zxvf hadoop-2.7.2.tar.gz #解压hadoop安装包
安装成功后配置路径:跟jdk相似。
命令:vi /etc/profile
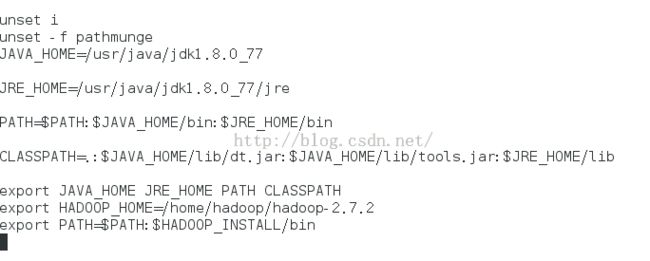
八、配置namenode 修改site文件
1、修改core-site.xml文件
命令:cd /home/hadoop/hadoop-2.7.2/etc/hadoop
ls 可以看到有core-site.xml hdfs-site.xml yarn-site.xml
命令:vi core-site.xml

2、修改hdfs-site.xml文件
命令:vi hdfs-site.xml
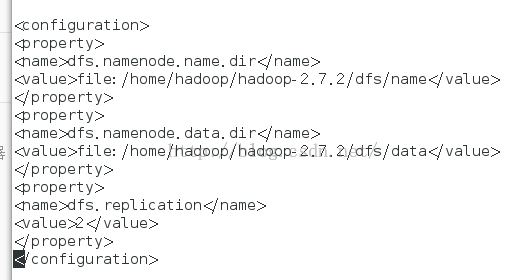
3、修改yarn-site.xml文件

4、修改mapred-site.xml.template

5、修改hadoop-env.sh 文件
命令:source hadoop-env.sh 让其生效
九、配置slaves文件
命令:cd /home/hadoop/hadoop-2.7.2/etc/hadoop
ls 查看slaves文件
vi slaves
如图:

十、向各节点复制hadoop 由于自己是逐一配置,因此不需要此步骤。如果是只配置了一个 可以使用scp命令 向其他两个节点复制hadoop配置的文件和环境
十一、格式化namenode,只格式一次
命令:hadoop namenode -format
如果出现了successfully format 则成功!!
十二、启动hadoop
切到/home/hadoop/hadoop-2.7.2/sbin目录下,命令:./start-all.sh
在node1和node2节点处查看启动的守护进程:jps

至此,大功告成!!