Spring 4.2.5 - 之一
分析目标 - 初始化BeanFactory
代码:BeanFactory bf = new XmlBeanFactory(new ClassPathResource("bean.xml"));
第 1 步
new ClassPathResource(“bean.xml”)
实现方式如下
public class ClassPathResource extends AbstractFileResolvingResource {
public ClassPathResource(String path) {
this(path, (ClassLoader) null);
}
public ClassPathResource(String path, ClassLoader classLoader) {
Assert.notNull(path, "Path must not be null");
// 规范化path,比如去除Windows的\\ 例 .\\xml/../.\\bean.xml 转化为 bean.xml
String pathToUse = StringUtils.cleanPath(path);
if (pathToUse.startsWith("/")) {
pathToUse = pathToUse.substring(1);
}
// 保存path和classLoader
this.path = pathToUse;
this.classLoader = (classLoader != null ? classLoader : ClassUtils.getDefaultClassLoader());
}
}PS:
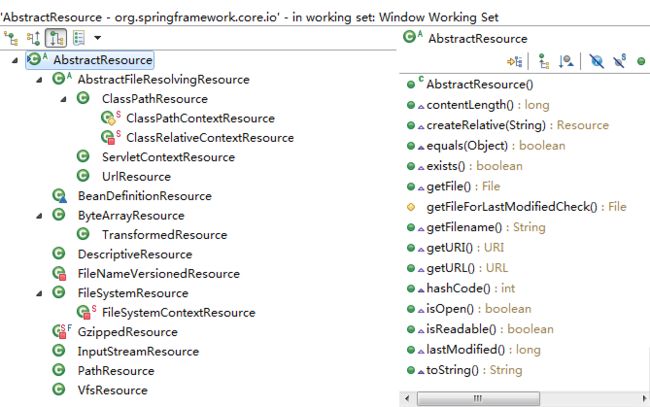
Resource是Spring中对于资源的抽象接口,AbstractResouce是基于其的抽象对象,其子类如下图所示。学习一下Spring的资源的抽象和封装方式
总结:
代码重点工作
1. 清理掉入参Path中无关的路径,并保存
2. 获取当前环境的ClassLoader,并保存
3. 封装为ClassPathResource对象,为后续提供InputStream getInputStream(),提供文件流接口打基础
收获:
1. Spring中Resource接口及其衍生对象
2. Spring中StringUtils工具类
第 2 步
new XmlBeanFactory(new ClassPathResource("bean.xml"));
XmlBeanFactory类的代码非常简单,只有构造函数定义,下面是此类所有的代码
public class XmlBeanFactory extends DefaultListableBeanFactory {
private final XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(this);
public XmlBeanFactory(Resource resource) throws BeansException {
this(resource, null);
}
public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) throws BeansException {
super(parentBeanFactory);
// *实现资源加载*
this.reader.loadBeanDefinitions(resource);
}
}只有短短的几行。
重点是 this.reader.loadBeanDefinitions(resource); 完成了XML的解析和数据加载。但是我们一步一步来,先看 super(parentBeanFactory) - DefaultListableBeanFactory;
public class DefaultListableBeanFactory extends AbstractAutowireCapableBeanFactory implements ConfigurableListableBeanFactory, BeanDefinitionRegistry, Serializable {
public DefaultListableBeanFactory(BeanFactory parentBeanFactory) {
super(parentBeanFactory);
}
}继续调用父类AbstractAutowireCapableBeanFactory,此处parentBeanFactory值是null
1. ConfigurableListableBeanFactory接口 -
2. BeanDefinitionRegistry接口 -
public abstract class AbstractAutowireCapableBeanFactory extends AbstractBeanFactory implements AutowireCapableBeanFactory {
public AbstractAutowireCapableBeanFactory(BeanFactory parentBeanFactory) {
this();
setParentBeanFactory(parentBeanFactory);
}
public AbstractAutowireCapableBeanFactory() {
// 父类AbstractBeanFactory 定义为 public AbstractBeanFactory() {},未做任何操作
super();
// ignoreDependencyInterface忽略给定接口的自动装配功能
ignoreDependencyInterface(BeanNameAware.class);
ignoreDependencyInterface(BeanFactoryAware.class);
ignoreDependencyInterface(BeanClassLoaderAware.class);
}
}可以看出,XmlBeanFactory初始化过程中第一步,super(parentBeanFactory),仅仅是完成了BeanNameAware等特性的设置。举个例子说明这样操作的未来影响。比如Bean A中定义了成员对象B,B实现了BeanNameAware接口。基于Spring的Autowiring自动装配特性,在Spring获取A的时候,本应自动初始化B。但是因为B实现了BeanNameAware接口,所以B不会被初始化。
初始化过程的第二步 this.reader.loadBeanDefinitions(resource) 将完成最重要的功能 - 实现资源的加载。下面将进行重点分析。
首先是reader对象初始化,代码如下private final XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(this);
public class XmlBeanDefinitionReader extends AbstractBeanDefinitionReader {
// 入参registry(this)指代的XmlBeanFactory对象的父类DefaultListableBeanFactory实现了BeanDefinitionRegistry 接口
public XmlBeanDefinitionReader(BeanDefinitionRegistry registry) {
// 调用父类 AbstractBeanDefinitionReader 构造方法
super(registry);
}
}
public abstract class AbstractBeanDefinitionReader implements EnvironmentCapable, BeanDefinitionReader {
protected AbstractBeanDefinitionReader(BeanDefinitionRegistry registry) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
this.registry = registry;
// Determine ResourceLoader to use.
if (this.registry instanceof ResourceLoader) {
this.resourceLoader = (ResourceLoader) this.registry;
}
else {
// 因为XmlBeanFactory 不是 ResourceLoader 的实例。所以..
this.resourceLoader = new PathMatchingResourcePatternResolver();
}
// Inherit Environment if possible
if (this.registry instanceof EnvironmentCapable) {
this.environment = ((EnvironmentCapable) this.registry).getEnvironment();
}
else {
// 因为XmlBeanFactory 不是 EnvironmentCapable 的实例。所以..
this.environment = new StandardEnvironment();
}
}
}以上代码主要完成了Reader对象的属性初始化:
1. 初始化 resourceLoader 为 PathMatchingResourcePatternResolver对象
2. 初始化 environment 为 StandardEnvironment对象
接着是loadBeanDefinitions(resource)
public class XmlBeanDefinitionReader extends AbstractBeanDefinitionReader {
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
// 对于本次调用来说,EncodeResource不完成什么功能
// EncodeResource主要是对于InputStreamReader的封装,支持charset和encoding设置
return loadBeanDefinitions(new EncodedResource(resource));
}
}所以
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isInfoEnabled()) {
logger.info("Loading XML bean definitions from " + encodedResource.getResource());
}
// 因为还设置,此处获得的currentResource为null
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
// 初始化容量为4的HashSet
currentResources = new HashSet<EncodedResource>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
} try {
// 获取之前创建的Resource的InputStream,并转化为xml InputSource
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
// doLoadBeanDefinitions 核心方法!
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
finally {
inputStream.close();
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("IOException parsing XML document from "
+ encodedResource.getResource(), ex);
}
finally {
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}绕来绕去,终于绕道正题 doLoadBeanDefinitions(inputSource, encodedResource.getResource());
总结:
代码重点工作
1. 完成了BeanName/BeanFactory/BeanClassLoaderAware等相关特性的设置(父类构造函数中完成)
2. 将Resource封装为EncodedResource,完成对于字符编码的统一化处理,完成对于字节流到字符流的统一封装
2. 通过SAX读取Resource提供的XML文件字节流,初始化InputSource对象
到此,所有的准备工作都已经完成,终于进入正题
收获:
1. Spring中EncodedResouce封装
2. Spring利用SAX库完成XML解析
2. BeanFactory不直接参与Bean对象的读取和加载,而由XmlBeanDefinitionReader成员对象完成
第 2.5 步
doLoadBeanDefinitions(inputSource, encodedResource.getResource());
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
// 获取XML文件验证模式,加载XML文件,并得到对应的Document
Document doc = doLoadDocument(inputSource, resource);
// 根据返回的Document完成Bean注册
return registerBeanDefinitions(doc, resource);
}
catch (BeanDefinitionStoreException ex) {
...// 先忽略冗长的catch代码
}无视catch代码,这段代码核心为
1. doLoadDocument(inputSource, resource);
2. registerBeanDefinitions(doc, resource);
(PS:早期版本中getValidationModeForResource获取XML文件验证模式功能,及this.documentLoader.loadDocument在本版本中整合到doLoadDocument中。)
首先是doLoadDocument
protected Document doLoadDocument(InputSource inputSource, Resource resource) throws Exception {
return this.documentLoader.loadDocument(inputSource, getEntityResolver(), this.errorHandler,
getValidationModeForResource(resource), isNamespaceAware());
}短短一句代码包含了大量的信息。
1. getEntityResolver()
2. getValidationModeForResource(resource) - 获取XML文件验证模式 DTD or XSD,直接通过判断是否包含 DOCTYPE
3. isNamespaceAware() - 默认false
4. this.documentLoader.loadDocument
先看 getEntityResolver() ,EntityResolver ,如果SAX应用程序需要实现自定义处理外部实体,则必须实现此接口并使用setEntityResolver方法向SAX DocumentBuilder 注册一个实例。
EntityResolver 的作用是项目本身可以提供一个如何寻找DTD声明的方式,默认是通过网络来下载DTD声明,并完成认证。
protected EntityResolver getEntityResolver() {
if (this.entityResolver == null) {
// Determine default EntityResolver to use.
// ResourceLoader接口用于实现不同的Resource加载策略
ResourceLoader resourceLoader = getResourceLoader();
if (resourceLoader != null) {
this.entityResolver = new ResourceEntityResolver(resourceLoader);
}
else {
this.entityResolver = new DelegatingEntityResolver(getBeanClassLoader());
}
}
return this.entityResolver;
}getResourceLoader()会返回 PathMatchingResourcePatternResolver 对象,追溯一下最初的赋值过程。
public class XmlBeanFactory extends DefaultListableBeanFactory {
// 应该还记得 this.reader.loadBeanDefinitions(resource); 这段代码吧,这里是reader的初始化过程
private final XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(this);
}
public class XmlBeanDefinitionReader extends AbstractBeanDefinitionReader {
public XmlBeanDefinitionReader(BeanDefinitionRegistry registry) {
super(registry);
}
}
// 一层层追溯
public abstract class AbstractBeanDefinitionReader implements EnvironmentCapable, BeanDefinitionReader {
protected AbstractBeanDefinitionReader(BeanDefinitionRegistry registry) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
this.registry = registry;
// Determine ResourceLoader to use.
if (this.registry instanceof ResourceLoader) {
this.resourceLoader = (ResourceLoader) this.registry;
}
else {
// 因为 XmlBeanFactory 并未实现ResourceLoader接口,所以默认设置为PathMatchingRes..
this.resourceLoader = new PathMatchingResourcePatternResolver();
}
// Inherit Environment if possible
if (this.registry instanceof EnvironmentCapable) {
this.environment = ((EnvironmentCapable) this.registry).getEnvironment();
}
else {
this.environment = new StandardEnvironment();
}
}可以很清晰的看出,XXXBeanDefinitionReader在初始化时会完成必要的初始逻辑,主要是设置ResourceLoader及EnvironmentCapable接口对象。
PathMatchingResourcePatternResolver类实现了ResourcePatternResolver接口,interface ResourcePatternResolver extends ResourceLoader,在对继承自ResourceLoader接口的方法的实现会代理给该引用,同时在getResources()方法实现中,当找到一个匹配的资源location时,可以使用该引用解析成Resource实例。默认使用DefaultResourceLoader类,用户可以使用构造函数传入自定义的ResourceLoader。
PathMatchingResourcePatternResolver还包含了一个对PathMatcher接口的引用,该接口基于路径字符串实现匹配处理,如判断一个路径字符串是否包含通配符(’*’、’?’),判断给定的path是否匹配给定的pattern等。Spring提供了AntPathMatcher对PathMatcher的默认实现,表达该PathMatcher是采用Ant风格的实现。详细介绍见 http://www.blogjava.net/DLevin/archive/2012/12/01/392337.html
回到之前的逻辑中,getEntityResolver将最终返回一个 ResourceEntityResolver 对象,使用 PathMatchingResourcePatternResolver 初始化。
最后是loadDocument,Spring没有做什么特别的事情,通过SAX解析XML都是都是这个套路。先创建 DocumentBuilderFactory 然后创建 DocumentBuilder ,然后解析返回 Document 对象
public class DefaultDocumentLoader implements DocumentLoader {
public Document loadDocument(InputSource inputSource, EntityResolver entityResolver,
ErrorHandler errorHandler, int validationMode, boolean namespaceAware) throws Exception {
// 简单封装完成基础的比如 SCHEMA_LANGUAGE_ATTRIBUTE 等设置
DocumentBuilderFactory factory = createDocumentBuilderFactory(validationMode, namespaceAware);
if (logger.isDebugEnabled()) {
logger.debug("Using JAXP provider [" + factory.getClass().getName() + "]");
}
// 简单封装,完成 entityResolver errorHandler 的设置
DocumentBuilder builder = createDocumentBuilder(factory, entityResolver, errorHandler);
return builder.parse(inputSource);
}
}至此,
doLoadBeanDefinitions(InputSource inputSource, Resource resource) throws BeanDefinitionStoreException {
try {
Document doc = doLoadDocument(inputSource, resource);
return registerBeanDefinitions(doc, resource);
}
...// 忽略冗长的catch代码
}中最关键的两句,doLoadDocument已经解析完成,我们总结一下主要流程
1. 获取XML文件验证模式
2. 向SAX注册Spring自己实现的EntityResolver以完成本地化DTD or XSD 认证
3. 通过SAX完成解析,获取Document对象
接下来我们将分析registerBeanDefinitions(doc, resource);
第 2.9 步
registerBeanDefinitions(doc, resource);
public class XmlBeanDefinitionReader extends AbstractBeanDefinitionReader {
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
// 这里实例化的是DefaultBeanDefinitionDocumentReader对象,可以通过this.setDocumentReaderClass设置
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
// 获取已经创建的bean的数量,此处getRegistry返回的是之前创建的XmlBeanFactory(implements interface BeanDefinitionRegistry)
int countBefore = getRegistry().getBeanDefinitionCount();
// Read bean definitions from the given DOM document and register them with the registry in the given reader context.
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
// 返回获取的Bean的个数
return getRegistry().getBeanDefinitionCount() - countBefore;
}
}依然是XmlBeanDefinitionReader类中定义的方法。我们一条条来分析。首先是 BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();这里实例化的是DefaultBeanDefinitionDocumentReader对象,实现了BeanDefinitionDocumentReader 接口,接口仅定义了一个方法 registerBeanDefinitions
public class DefaultBeanDefinitionDocumentReader implements BeanDefinitionDocumentReader {
// 无自定义构造函数
}
public interface BeanDefinitionDocumentReader {
/** * Read bean definitions from the given DOM document and * register them with the registry in the given reader context. * @param doc the DOM document * @param readerContext the current context of the reader * (includes the target registry and the resource being parsed) * @throws BeanDefinitionStoreException in case of parsing errors */
void registerBeanDefinitions(Document doc, XmlReaderContext readerContext)
throws BeanDefinitionStoreException;
}完成实例化之后就是调用 registerBeanDefinitions,将之前获取的Document对象及方法
public class DefaultBeanDefinitionDocumentReader implements BeanDefinitionDocumentReader {
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
logger.debug("Loading bean definitions");
Element root = doc.getDocumentElement();
doRegisterBeanDefinitions(root);
}
}这里我们终于看到最核心的部分 doRegisterBeanDefinitions(root)。
(未完待续)