推荐系统学习03-SVDFeature
介绍
SVDFeature是由Apex Data & Knowledge Management Lab在KDD CUP11竞赛中开发出来的工具包。它的目的是有效地解决基于特征的矩阵分解。新的模型可以只通过定义新的特征来实现。这种基于特征的设置允许我们把很多信息包含在模型中,使得模型更加与时俱进。使用此工具包,可以很容易的把其他信息整合进模型,比如时间动态,领域关系和分层信息。除了评分预测,还可以实现pairwise ranking任务。
模型
SVDFeature的模型定义如下:
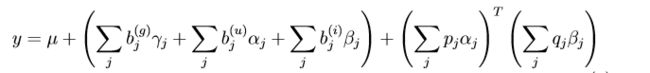
输入包含三种特征<α,β,γ>,分别是用户特征,物品特征和全局特征。
模型的最终版本是:
活跃函数和损失函数的通常选择如下(忽略后面的标识):
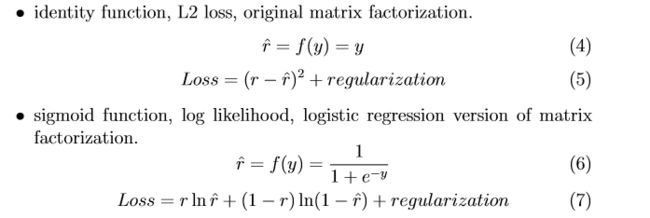
详细内容可自行查阅SVDFeature-manual。
输入格式
输入格式是和SVM格式相似的稀疏特征格式。对一个输入样本,我们需要指定三种特征,< α,β,γ >和预测目标。格式如下:
这里的id和value对应非零项的特征id和特征值。特征文件首先指定预测的目标,然后是全局,用户,物品特征向量中非零项的数目。然后以稀疏特征格式列举出非零全局,用户和物品特征。例如,如果我们使用基本矩阵分解模型,用户0给物品10评分为5:
5 0 1 1 0:1 10:1
这里的<0,1,1>表示0个全局特征,1一个用户特征和1个物品特征。0:1表示用户特征,10:1表示物品特征。
其余详细内容自行查阅SVDFeature-manual。
SVDFeature工具包里的文件:
* solvers: all the customization of SVDFeature solvers, not included in the basic package
* tools : the auxiliary tools that can be used for experiment
* demo : the examples that can help to get started on the toolkit
操作
我使用的是Ubuntu14.04。编译环境要求g++4.6及以上,至于如何安装g++,自行百度。
将Svdfeature-1.2.2.tar.gz拷贝到Ubuntu中,解压。
进入主目录和tools目录分别输入“make”进行编译。
编译完成后进入demo目录:

SVDFeature提供了5个例子,分别是:basicMF、binaryClassification、implicitfeedback、neighborhoodModel和pairwiseRank。
单独进入一个目录,里面包含了一个run.sh文件,运行“./run.sh”即可完成训练和测试阶段。
假如目录中还有run-ml100K.sh文件,说明可以使用Movielen数据,步骤为:下载 ml-100K 数据, 把 ua.base和ua.test放入目录 , 运行“ run-ml100K.sh”。
普通运行过程:
运行结束:
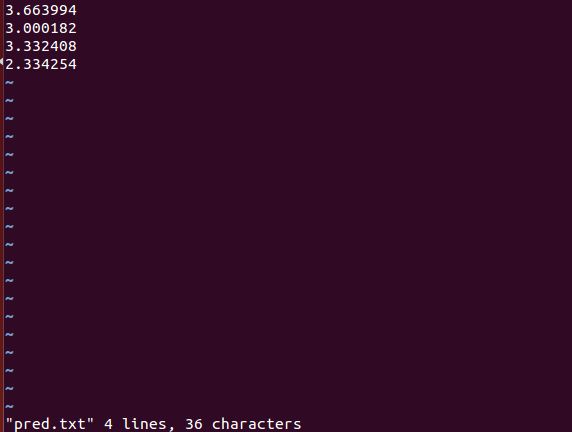
预测结果:
使用movielen运行:
运行的结果保存在pred.txt中:
其余几个例子就不一一展示了。