Mahout的taste里的几种相似度计算方法
欧几里德相似度(Euclidean Distance)
最初用于计算欧几里德空间中两个点的距离,以两个用户x和y为例子,看成是n维空间的两个向量x和y, xi表示用户x对itemi的喜好值,yi表示用户y对itemi的喜好值,他们之前的欧几里德距离是
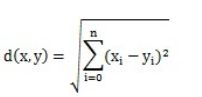
对应的欧几里德相似度,一般采用以下公式进行转换:距离越小 ,相似度越大
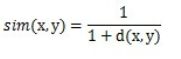
在taste里,计算user之间和item之前欧几里德相似度的类是EuclideanDistanceSimilarity。
皮尔逊相似度(Pearson Correlation Coefficient)
皮尔逊相关系数一般用于计算两个定距变量间线性相关的紧密程度,它的取值在[-1,+1]之间。当取值大于0时表示两个变量是正相关的,即一个变量的值越大,另一个变量的值也会越大;当取值小于0时表示两个变量是负相关的,即一个变量的值越大,另一个变量的值反而会越小。其计算公式如下
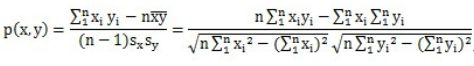
其中sx和sy是样品的标准偏差
在taste里, PearsonCorrelationSimilarity的实现方式不是采用上述公式,而是采用3的实现。
Cosine相似度(Cosine Similarity)
就是两个向量的夹角余弦,被广泛应用于计算文档数据的相似度
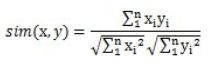
在taste里, 实现Cosine相似度的类是PearsonCorrelationSimilarity, 另外一个类UncenteredCosineSimilarity的实现了形式化以后的cosine向量夹角,如下公式
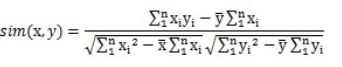
用这种公式计算的原因如下:余弦相似度更多的是从方向上区分差异,而对绝对的数值不敏感。因此没法衡量每个维数值的差异,会导致这样一个情况:比如用户对内容评分,5分制,X和Y两个用户对两个内容的评分分别为(1,2)和(4,5),使用余弦相似度得出的结果是0.98,两者极为相似,但从评分上看X似乎不喜欢这2个内容,而Y比较喜欢,余弦相似度对数值的不敏感导致了结果的误差,需要修正这种不合理性,就出现了调整余弦相似度,即所有维度上的数值都减去一个均值,比如X和Y的评分均值都是3,那么调整后为(-2,-1)和(1,2),再用余弦相似度计算,得到-0.8,相似度为负值并且差异不小,但显然更加符合现实。
Tanimoto 相似度
Tanimoto系数也称Jaccard系数,是Cosine相似度的扩展,也多用于计算文档相似度。计算公式如下:
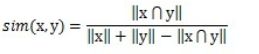
其中x表示用户x所喜好的所有item的集合, y表示用户y所喜好的所有item的集合。
在taste里,实现Tanimoto 相似度的类是TanimotoCoefficientSimilarity,可以看出这种计算方法适用于用户对item的喜好是0和1那种情况。
City Block(或者曼哈顿)相似度
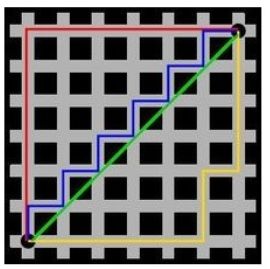
出租车几何或曼哈顿距离(Manhattan Distance)是由十九世纪的赫尔曼·闵可夫斯基所创词汇 ,是种使用在几何度量空间的几何学用语,用以标明两个点上在标准坐标系上的绝对轴距总和。图中红线代表曼哈顿距离,绿色代表欧氏距离,也就是直线距离,而蓝色和黄色代表等价的曼哈顿距离。
计算公式是:
转换后的相似度为:

在tasete里的实现类CityBlockSimilarity采用了简化的计算方式,比较适用于用户的喜欢数据时0或者1的情况
LogLikelihood(对数似然相似度)相似度
公式比较复杂,实现类为LogLikelihoodSimilarity,比较适用于用户的喜欢数据时0或者1的情况
Spearman(斯皮尔曼)相似度
斯皮尔曼相关性可以理解为是排列后(Rank)用户喜好值之间的Pearson相关度。《Mahout in Action》中有这样的解释:假设对于每个用户,我们找到他最不喜欢的物品,重写他的评分值为“1”;然后找到下一个最不喜欢的物品,重写评分值为“2”,依此类推。然后我们对这些转换后的值求Pearson相关系数,这就是Spearman相关系数。
斯皮尔曼相关度的计算舍弃了一些重要信息,即真实的评分值。但它保留了用户喜好值的本质特性——排序(ordering),它是建立在排序(或等级,Rank)的基础上计算的。
因为斯皮尔曼相关性的计算需要花时间计算并存储喜好值的一个排序(Ranks),具体时间取决于数据的数量级大小。正因为这样,斯皮尔曼相关系数一般用于学术研究或者是小规模的计算。
在taste里的实现类为SpearmanCorrelationSimilarity